Orthogonal Characterization in Autonomous Workflows: Ensuring Reliability in AI-Driven Scientific Discovery
The integration of autonomous artificial intelligence (AI) with orthogonal characterization—the use of multiple, independent analytical methods—is revolutionizing scientific research and drug development.
Orthogonal Characterization in Autonomous Workflows: Ensuring Reliability in AI-Driven Scientific Discovery
Abstract
The integration of autonomous artificial intelligence (AI) with orthogonal characterization—the use of multiple, independent analytical methods—is revolutionizing scientific research and drug development. This article explores the foundational principles of this synergy, demonstrating how it enhances the reliability, reproducibility, and decision-making capabilities of self-driving laboratories. By examining real-world applications from chemical synthesis to biopharmaceutical profiling, we provide a methodological framework for implementation, address key troubleshooting and optimization challenges, and present validation strategies that compare autonomous systems against conventional research. This synthesis is intended to equip researchers and development professionals with the knowledge to build more robust, trustworthy, and efficient AI-driven research platforms.
The Pillars of Trust: Defining Orthogonal Characterization and Agentic Autonomy
The landscape of artificial intelligence in science is undergoing a fundamental transformation, evolving from narrowly-scoped computational tools toward autonomous, end-to-end research partners. This progression marks a pivotal stage in the AI for Science paradigm, where AI systems have moved from acting as computational oracles for targeted tasks toward the emergence of what is now termed Agentic Science [1]. In this advanced stage, AI operates as an autonomous scientific agent capable of formulating hypotheses, designing and executing experiments, interpreting results, and iteratively refining theories with significantly reduced human guidance [1]. This evolution is particularly pronounced in fields like drug development and synthetic chemistry, where the integration of orthogonal characterization techniques—using multiple, independent measurement methods to validate findings—has become a critical component of autonomous workflows [2]. The shift from tools to partners represents not merely improved algorithms but a fundamental reimagining of the scientific process itself, with AI systems now demonstrating capabilities in complex reasoning, planning, and collaborative problem-solving that were once considered exclusively human domains [3] [1].
Defining the Spectrum: From AI Tools to Autonomous Partners
The transition to Agentic Science can be understood as an evolution through distinct levels of autonomy and capability. This progression begins with AI as a specialized tool and advances toward AI as a fully autonomous scientific partner. The terminology surrounding this field has crystallized into three distinct but interconnected concepts: AI Agents, Agentic AI, and Autonomous AI [3].
Table 1: Key Definitions in the Spectrum of Scientific AI
| Term | Definition | Core Characteristics | Scientific Analogy |
|---|---|---|---|
| AI Agents [3] | Foundational systems that perceive their environment and act to meet predefined goals within fixed rules. | Task-specific automation, limited adaptability, reliable in predictable environments. | A specialized lab instrument that performs a single, repetitive measurement. |
| Agentic AI [3] [4] | Systems that exhibit planning, learning, and context-aware adaptability for dynamic goal achievement. | Multi-step reasoning, dynamic task decomposition, adaptability to new information, collaboration. | A research assistant who can plan a series of experiments and adjust protocols based on initial results. |
| Autonomous AI [3] [1] | Systems capable of self-initiated decision-making and long-term planning with minimal human oversight. | Self-initiation, adaptation to novel situations, long-term planning, minimal supervision. | A principal investigator who defines research directions, formulates hypotheses, and directs entire projects. |
The conceptual relationship between these systems can be visualized as a progressive increase in capabilities, with each stage building upon the last.
Diagram 1: The AI Autonomy Spectrum
The Evolutionary Stages of AI in Science
Formally, this evolution can be categorized into distinct levels of scientific autonomy:
Level 1: AI as a Computational Oracle (Expert Tools): At this foundational level, AI operates as a collection of highly specialized, non-agentic models designed to solve discrete, well-defined problems within a human-led workflow. These expert tools excel at tasks such as prediction and generation but lack autonomy; they function as sophisticated function approximators that require constant human guidance for task definition, execution, and interpretation of results [1]. The core of the scientific process remains entirely in the hands of the human researcher.
Level 2: AI as an Automated Research Assistant (Partial Agentic Discovery): This level marks the introduction of AI as an Automated Research Assistant. Here, AI systems exhibit partial autonomy, functioning as agents that can execute specific, pre-defined stages of the research workflow. These agents can integrate multiple tools and carry out sequences of actions to complete well-defined sub-goals, such as running a series of experiments or performing a standardized data analysis pipeline. However, the high-level scientific direction, including the initial hypothesis, is still provided by human researchers [1].
Level 3: AI as an Autonomous Research Partner (Full Agentic Discovery): This represents the current frontier of Agentic Science, where AI systems operate as full research partners capable of end-to-end scientific investigation. These systems can formulate novel hypotheses, design complete experimental campaigns, execute methodologies through integrated platforms, analyze resulting data, and iteratively refine their understanding with minimal human intervention [1]. This level is characterized by robust multi-agent collaboration, where different AI specialists (e.g., design agents, analysis agents, validation agents) work in concert to solve complex problems [4] [1].
Case Study: Autonomous Discovery in Synthetic Chemistry
A landmark demonstration of Level 3 Autonomous AI recently emerged from synthetic chemistry, where researchers developed a modular autonomous platform for general exploratory synthesis using mobile robots [2]. This system exemplifies the core principles of Agentic Science and provides a compelling case study for evaluating orthogonal characterization in autonomous workflows.
Experimental Protocol and Workflow Design
The autonomous chemistry platform was designed to mimic human decision-making processes while leveraging the persistence and precision of robotic systems. The methodology centered on a closed-loop synthesis-analysis-decision cycle that integrated multiple analytical techniques for robust characterization [2].
Table 2: Core Experimental Protocol for Autonomous Chemical Discovery
| Protocol Phase | Description | Agentic Capability Demonstrated |
|---|---|---|
| Automated Synthesis | Reactions performed using a Chemspeed ISynth synthesizer with automated aliquot sampling and reformatting for different analysis types. | Task execution, sample handling |
| Orthogonal Characterization | Samples autonomously transported by mobile robots to UPLC-MS and benchtop NMR instruments for parallel analysis. | Tool integration, multi-modal perception |
| Heuristic Decision-Making | Custom algorithm processes both UPLC-MS and NMR data to provide binary pass/fail grading based on expert-defined criteria. | Reasoning, decision logic, goal orientation |
| Workflow Progression | System autonomously selects successful reactions for scale-up or further elaboration based on combined analytical results. | Planning, iterative learning, goal achievement |
The complete workflow, integrating physical robotics with algorithmic decision-making, represents a sophisticated embodiment of agentic science principles.
Diagram 2: Autonomous Chemistry Workflow
The Scientist's Toolkit: Research Reagent Solutions
The successful implementation of this autonomous workflow depended on carefully selected research reagents and instrumentation that enabled reliable, reproducible operations with minimal human intervention.
Table 3: Essential Research Reagents and Platforms for Autonomous Discovery
| Tool/Platform | Function | Role in Autonomous Workflow |
|---|---|---|
| Chemspeed ISynth Synthesizer | Automated chemical synthesis platform | Core reaction execution with integrated aliquot sampling |
| Mobile Robots with Multipurpose Grippers | Sample transportation and equipment operation | Physical linkage between modules; enables shared equipment use |
| UPLC-MS System | Ultra-high performance liquid chromatography with mass spectrometry | Primary characterization providing molecular weight and purity data |
| Benchtop NMR Spectrometer | Nuclear magnetic resonance spectroscopy | Orthogonal characterization for structural elucidation |
| Heuristic Decision Algorithm | Custom software for data interpretation | Autonomous decision-making based on multiple analytical inputs |
| Python Control Scripts | Customizable automation protocols | Orchestrates data acquisition and instrument control |
Orthogonal Characterization in Autonomous Workflows
A critical innovation in this platform was its emphasis on orthogonal characterization through combining UPLC-MS and NMR spectroscopic analysis [2]. Unlike earlier autonomous systems that relied on single analytical techniques, this approach mirrored human experimental practice by employing multiple, independent measurement methods to validate findings. This orthogonal methodology was particularly valuable for exploratory synthesis where reactions could yield multiple potential products, such as in supramolecular self-assembly processes [2]. The heuristic decision-maker processed these orthogonal datasets to make context-aware decisions about which reactions to advance, effectively dealing with the complexity inherent in chemical discovery where some products might yield complex NMR spectra but simple mass spectra, while others showed the reverse behavior [2].
Performance Comparison: Quantitative Assessment of AI Systems
Evaluating the performance of agentic AI systems requires multiple metrics beyond traditional computational benchmarks. The following comparative analysis examines both the capabilities and current limitations of these systems across different domains and task types.
Table 4: Performance Comparison of AI Systems Across Domains
| Domain/System | Key Performance Metrics | Strengths | Limitations/Challenges |
|---|---|---|---|
| Synthetic Chemistry Automation [2] | Successful autonomous navigation of multi-step synthetic pathways; Integration of orthogonal characterization (UPLC-MS + NMR) | Human-like decision-making; Equipment sharing without lab monopolization; Handling of exploratory synthesis | Limited to predefined chemistry spaces; Heuristic rules may overlook novel phenomena |
| Software Development [5] | -19% speed impact on experienced developers; 20-24% expected vs. actual performance gap | Effective for algorithmic tasks and benchmarks; Useful for prototyping and single-use code | Slows developers on complex, real-world codebases; Struggles with implicit requirements and high-quality standards |
| Drug Discovery Platforms [6] | AI-designed drugs reaching clinical trials in ~2 years vs. traditional ~5 years; 70% faster design cycles with 10x fewer compounds | Dramatically compressed discovery timelines; Efficient lead optimization; Integration of patient-derived biology | No AI-discovered drugs fully approved yet; Questions about better success vs. faster failure |
| Scientific Benchmark Performance [7] | 18.8-67.3 percentage point increases on demanding new benchmarks (MMMU, GPQA, SWE-bench) | Rapid performance improvements on specialized tasks; High scores on algorithmic evaluation | Performance may not translate to real-world scientific tasks; Potential for overestimation of capabilities |
The Validation Challenge: Reconciling Different Performance Metrics
The performance data reveals significant disparities between AI capabilities measured in controlled benchmarks versus real-world applications. While AI systems demonstrate impressive results on specialized benchmarks—with scores on demanding tests like MMMU, GPQA, and SWE-bench increasing by 18.8, 48.9, and 67.3 percentage points respectively [7]—their performance in practical scientific settings reveals important limitations. For instance, a randomized controlled trial with experienced software developers found that AI assistance actually resulted in a 19% slowdown when working on real-world codebases from large open-source projects [5]. This contrast highlights the critical importance of orthogonal validation methodologies that assess AI systems not just through algorithmic benchmarks but through realistic workflow integration and outcome measurement.
Current Landscape and Future Trajectory
AI in Pharmaceutical Development: The 2025 Outlook
The pharmaceutical industry represents a critical testing ground for Agentic Science, with AI-driven platforms demonstrating tangible progress. By mid-2025, over 75 AI-derived drug candidates had reached clinical stages, representing exponential growth from essentially zero in 2020 [6]. Leading AI drug discovery companies have advanced candidates into clinical trials, with notable examples including:
- Insilico Medicine's generative-AI-designed idiopathic pulmonary fibrosis drug progressing from target discovery to Phase I in 18 months, compared to the typical 5-year timeline [6].
- Exscientia's platform achieving approximately 70% faster design cycles while requiring 10x fewer synthesized compounds than industry norms [6].
- Schrödinger's physics-enabled design strategy advancing the TYK2 inhibitor zasocitinib into Phase III clinical trials [6].
The U.S. Food and Drug Administration (FDA) has recognized this trend, reporting a significant increase in drug application submissions using AI/ML components, and has established the CDER AI Council in 2024 to provide oversight and coordination of AI-related activities [8]. This regulatory engagement underscores the transition of AI from experimental curiosity to clinical utility.
Technical and Implementation Challenges
Despite promising advances, Agentic Science faces significant hurdles before achieving widespread adoption:
Reproducibility and Validation: The ability of autonomous AI systems to make genuinely novel discoveries that are reproducible and valid remains unproven. As noted in one survey, "AI's advancing capabilities have captured policymakers' attention, leading to an increase in AI-related policies worldwide" [7], reflecting concerns about reliability and accountability.
Integration with Existing Infrastructure: Successful autonomous systems must operate within established laboratory environments without monopolizing equipment or requiring extensive redesign. The mobile robot approach in synthetic chemistry demonstrates one solution, enabling "robots to share existing laboratory equipment with human researchers without monopolizing it" [2].
Reasoning Limitations: Current AI systems still struggle with complex reasoning benchmarks. As the 2025 AI Index Report notes, AI models "often fail to reliably solve logic tasks even when provably correct solutions exist, limiting their effectiveness in high-stakes settings where precision is critical" [7].
Trust and Communication Barriers: In pharmaceutical applications, concerns about "data security, algorithmic bias, and the reproducibility of AI's predictions contribute to hesitation among stakeholders" [9]. Bridging communication gaps between domain scientists and AI specialists remains challenging.
The evolution from AI tools to autonomous partners represents a fundamental transformation in scientific methodology. The integration of orthogonal characterization approaches—both in analytical techniques and performance validation—will be crucial for advancing Agentic Science from demonstration projects to reliable research partners. As autonomous systems increasingly handle exploratory tasks in complex domains like synthetic chemistry and drug discovery, their ability to leverage multiple, independent measurement and validation techniques will separate symbolic automation from genuine scientific advancement.
The most promising developments combine sophisticated AI reasoning with physical laboratory automation, creating closed-loop systems that can navigate the iterative, often ambiguous nature of scientific discovery. As these systems evolve, the focus must remain on robust validation, transparent methodology, and complementary human-AI collaboration rather than wholesale replacement of human researchers. The future of Agentic Science lies not in autonomous systems working in isolation, but in effectively orchestrated partnerships that leverage the unique strengths of both human and artificial intelligence to accelerate the pace of scientific discovery.
Defining Orthogonal Characterization
In scientific research and development, orthogonal characterization refers to the strategy of using multiple, independent analytical methods to measure the same essential property of a sample. The core principle is that each technique operates on a different physical or chemical measurement principle, thus providing independent data streams that cross-validate one another [10] [11].
This approach is fundamentally linked to complementary methods, but with a key distinction:
- Orthogonal Methods target the same property (e.g., particle size) using different physical principles (e.g., flow imaging microscopy vs. light obscuration) to minimize method-specific biases and provide independent confirmation [10] [11].
- Complementary Methods provide information about different properties of a sample (e.g., particle size and protein conformation) to build a more comprehensive profile [10].
The power of orthogonality lies in its ability to mitigate the inherent biases and limitations of any single analytical technique. By comparing results from methods with different systematic errors, scientists can achieve a more accurate and reliable measurement of Critical Quality Attributes (CQAs), which are essential for ensuring the safety and efficacy of products like biopharmaceuticals [10] [12].
The Critical Role of Orthogonal Characterization
Orthogonal characterization matters because it is a cornerstone of reliability and accuracy in complex scientific fields. Its importance is most evident in several key areas:
Ensuring Product Quality and Safety
In the pharmaceutical and biopharmaceutical industries, orthogonal methods are essential for characterizing complex biological products like monoclonal antibodies, vaccines, and cell therapies [12]. For instance, combining Flow Imaging Microscopy (FIM) with Light Obscuration (LO) provides a more accurate assessment of subvisible particles and protein aggregates in a drug product than either method alone, ensuring batch consistency and patient safety [10].
Building Robust Analytical Methods
During drug development, orthogonal methods are used to validate primary analytical techniques. As shown in Table 1, a systematic approach using multiple chromatographic conditions can reveal impurities or degradation products that a single method might miss, ensuring the primary control method is truly stability-indicating [13].
Enabling Autonomous Discovery
The use of orthogonal data is becoming crucial for advanced research workflows, including autonomous laboratories. A 2024 study in Nature demonstrated a robotic platform that uses UPLC-MS and benchtop NMR to autonomously characterize reaction outcomes. The heuristic decision-maker processes this orthogonal data to select successful reactions for further exploration, mimicking the multifaceted decision-making of a human researcher [14].
Table 1: Summary of Orthogonal Method Applications Across Industries
| Field/Industry | Common Orthogonal Technique Pairs | Property Measured | Primary Benefit |
|---|---|---|---|
| Biopharmaceuticals | Flow Imaging Microscopy (FIM) & Light Obscuration (LO) [10] | Subvisible particle size & concentration | Cross-validation for accurate particle counting and regulatory compliance. |
| Analytical Chemistry | Multiple HPLC methods with different columns and mobile phases [13] | Impurity and degradation product profiles | Ensures no critical impurities are overlooked by the primary stability-indicating method. |
| Antibody Engineering | Dynamic Light Scattering (DLS), Size Exclusion Chromatography (SEC), & Mass Photometry [15] | Protein aggregation, size, and oligomeric state | Robust evaluation of conformational stability and aggregation propensity. |
| Autonomous Chemistry | UPLC-MS & Benchtop NMR Spectroscopy [14] | Reaction outcome and product identity | Enables robotic platforms to make reliable, human-like decisions on synthetic success. |
Experimental Protocols: Implementing an Orthogonal Workflow
The following case studies illustrate detailed protocols for implementing orthogonal characterization.
Case Study 1: Orthogonal Screening for HPLC Method Development
This protocol ensures a primary HPLC method can separate all potential impurities and degradation products [13].
- Sample Generation: Collect all available batches of drug substance and product. Generate potential degradation products through forced decomposition studies (e.g., exposure to heat, light, acid, base, oxidants).
- Initial Screening: Analyze the generated samples using a single, broad generic gradient HPLC method to identify samples with unique impurity profiles for further study.
- Orthogonal Screening: Screen the selected samples using a matrix of 36 different chromatographic conditions. This typically involves six different broad gradients, each run on six different column chemistries (e.g., C18, C8, PFP, phenyl) with varying pH modifiers (e.g., formic acid, trifluoroacetic acid, ammonium acetate) [13].
- Method Selection & Optimization: From the screening data, select a primary method that separates all components of interest. Identify a second, orthogonal method that provides a distinctly different selectivity profile. Use modeling software to fine-tune both methods.
- Validation and Deployment: Validate the primary method for release and stability testing. Use the orthogonal method to screen samples from new synthetic routes or pivotal stability studies to ensure the primary method remains specific over time [13].
Case Study 2: Orthogonal Analysis of Engineered Antibodies
This protocol characterizes the stability and aggregation propensity of various antibody constructs (e.g., full-length IgG, scFv fragments) [15].
- Sample Preparation: Express and purify the panel of antibody constructs (e.g., in Expi293 cells using transient transfection and Protein-G purification).
- Multi-Technique Analysis: Subject each construct to a suite of orthogonal analytical techniques:
- Size Exclusion Chromatography (SEC): To monitor oligomeric state and quantify soluble aggregates.
- Dynamic Light Scattering (DLS): To determine hydrodynamic size distribution and polydispersity.
- Mass Photometry: To measure molecular mass and quantify oligomers in solution.
- nano-Differential Scanning Fluorimetry (nanoDSF): To assess thermal stability by measuring protein unfolding.
- Circular Dichroism (CD): To evaluate secondary and tertiary structure.
- Data Integration: Correlate findings across all techniques. For example, an early elution peak in SEC, an increase in polydispersity from DLS, and a shift in thermal unfolding from nanoDSF collectively provide orthogonal confirmation of reduced stability and increased aggregation propensity in engineered fragments compared to full-length antibodies [15].
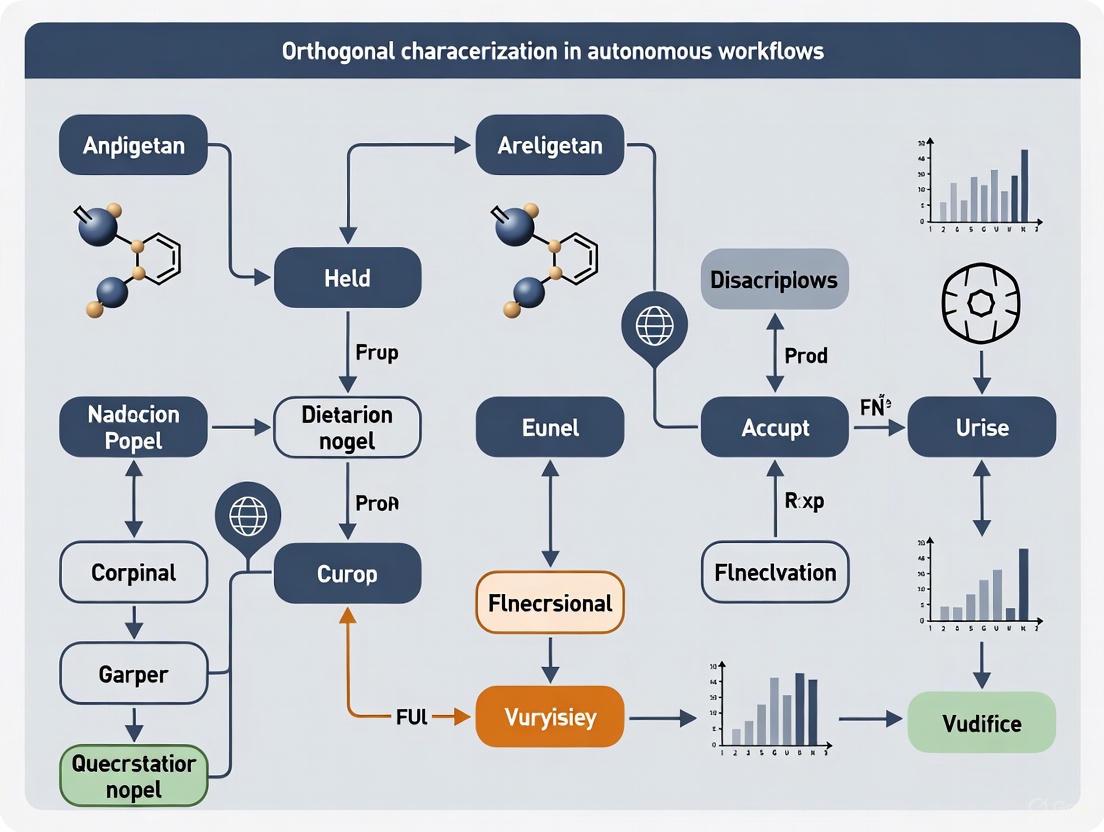
Orthogonal Characterization in Autonomous Workflows
The integration of orthogonal characterization is a key enabler for the next generation of autonomous laboratories. The workflow, as demonstrated by the mobile robot platform, can be visualized as a cyclic process of synthesis, orthogonal analysis, and heuristic decision-making.
Diagram 1: Autonomous Orthogonal Workflow. This cycle shows how a synthesis platform, coupled with orthogonal analysis and a decision-maker, can operate autonomously.
In this workflow, the robot handles samples and operates standard, unmodified laboratory equipment like UPLC-MS and NMR spectrometers [14]. The "heuristic decision-maker" processes the orthogonal data streams (e.g., MS molecular weight information and NMR structural information) to assign a pass/fail grade to each reaction. This allows the system to autonomously select successful reactions for scale-up or further diversification, and to check the reproducibility of screening hits, all based on multifaceted data that mimics human judgment [14].
The Scientist's Toolkit: Key Reagents and Instruments
Table 2: Essential Research Solutions for Orthogonal Characterization
| Category | Item / Technique | Primary Function in Orthogonal Workflows |
|---|---|---|
| Separation & Analysis | Size Exclusion Chromatography (SEC) | Separates biomolecules by size to analyze aggregation and oligomeric state [15]. |
| Dynamic Light Scattering (DLS) | Measures hydrodynamic size distribution and polydispersity of particles in solution [15]. | |
| UPLC/HPLC-MS | Separates complex mixtures (UPLC/HPLC) and provides molecular weight/identity data (MS) [14]. | |
| Structural Analysis | Nuclear Magnetic Resonance (NMR) | Provides detailed information on molecular structure, dynamics, and environment [14]. |
| Circular Dichroism (CD) | Assesses protein secondary and tertiary structure and folding stability [15]. | |
| nanoDSF | Measures thermal unfolding to evaluate protein conformational stability [15]. | |
| Imaging & Counting | Flow Imaging Microscopy (FIM) | Takes images of individual particles for size, count, and morphological analysis [10]. |
| Light Obscuration (LO) | Counts and sizes particles based on light blockage, often for pharmacopeial compliance [10]. | |
| Material Characterization | Orthogonal Experimental Design | Statistically optimizes multiple parameters (e.g., in battery thermal management) with minimal experimental runs [16] [17]. |
Orthogonal characterization is far more than a technical best practice; it is a fundamental paradigm for ensuring data integrity and making reliable decisions in science. By deliberately employing multiple independent measurement techniques, researchers can control for methodological biases, uncover hidden complexities, and build a more truthful understanding of their samples. As scientific challenges grow more complex, particularly with the advent of autonomous discovery platforms, the principle of orthogonality will remain a critical tool for ensuring that our measurements are robust, our products are safe, and our discoveries are sound.
The evolution of autonomous scientific systems represents a fundamental shift in research methodology, moving from single-measurement optimization to multifaceted, data-rich decision-making. Autonomous laboratories, particularly in fields like chemical synthesis and drug discovery, now demonstrate that integrating multiple, independent data streams significantly enhances the robustness and discovery potential of self-directed research. This approach, termed orthogonal characterization, leverages complementary analytical techniques to create a more comprehensive understanding of experimental outcomes than any single method could provide. Unlike traditional automated systems designed to maximize a single, known output, modern autonomous workflows must navigate complex, open-ended problems where multiple potential outcomes exist and the "correct" answer may not be predefined. The synergy created by fusing these orthogonal data streams enables autonomous systems to make nuanced decisions that more closely emulate human expert reasoning, thereby accelerating scientific discovery while remaining open to novel findings that might otherwise be overlooked.
Theoretical Foundation: From Single-Stream to Multi-Stream Data Integration
The Limitations of Single-Stream Automation
Traditional automated research workflows often rely on bespoke equipment with hard-wired characterization techniques, forcing decision-making algorithms to operate with limited analytical information [14]. This single-stream approach works adequately for well-defined optimization problems, such as maximizing the yield of a known catalyst, where a single scalar output (e.g., chromatographic peak area) suffices [14]. However, it fails dramatically in exploratory science where outcomes are multivariate and unknown in advance. In drug discovery, for instance, early-stage research has seen widespread AI adoption (76% of use cases in molecule discovery), while later clinical phases remain cautious (only 3% in clinical outcomes analysis), partly due to limitations in validation frameworks for complex, multi-faceted decision-making [18].
The Principle of Orthogonality in Data Streams
Orthogonal characterization combines measurement techniques that provide independent, non-redundant information about a system's properties. The power of this approach lies in the statistical independence of the data streams - where one method might fail or provide ambiguous results, another offers complementary insights. For example, in chemical synthesis, mass spectrometry reveals molecular weight information, while nuclear magnetic resonance spectroscopy elucidates molecular structure [14]. A product might yield highly complex NMR spectra but simple mass spectra, or vice versa [14]. Autonomous systems leveraging such orthogonal measurements can make context-based decisions about which data streams to prioritize, much like human researchers do, creating decision-making resilience that single-characterization systems lack.
Experimental Evidence: Quantitative Comparisons of Workflow Performance
Case Study: Autonomous Exploratory Chemistry
A landmark study in Nature (2024) directly demonstrates the superiority of multi-stream autonomous workflows. Researchers developed a modular platform using mobile robots to operate a synthesis platform, UPLC-MS, and benchtop NMR spectrometer, with a heuristic decision-maker processing the orthogonal measurement data [14]. The system was tested across three domains: structural diversification chemistry, supramolecular host-guest chemistry, and photochemical synthesis [14].
Table 1: Performance Comparison of Single vs. Multiple Data Streams in Autonomous Chemistry
| Workflow Configuration | Characterization Techniques | Decision Accuracy | Novelty Detection | Reproducibility Verification |
|---|---|---|---|---|
| Single-Stream (Chromatography) | UPLC only | Limited to known peak identification | Low - misses non-chromophoric products | Partial - based on retention time only |
| Single-Stream (Spectroscopy) | NMR only | Moderate for structural confirmation | Moderate - identifies novel structures | Good for structural reproducibility |
| Multi-Stream Orthogonal | UPLC-MS + NMR | High - combinatorial assessment | High - captures diverse product types | Comprehensive - structural + compositional |
The experimental results demonstrated that reactions needed to pass both orthogonal analyses to proceed to the next step, with the combined assessment effectively selecting successful reactions and automatically checking the reproducibility of screening hits [14]. This approach proved particularly valuable in supramolecular chemistry where self-assembly processes can produce diverse combinations from the same starting materials, frequently giving complex product mixtures [14].
Case Study: Autonomous Biomedical Research System
The Data-dRiven self-Evolving Autonomous systeM (DREAM) represents another advanced implementation of multi-stream decision-making in biomedical research. This fully autonomous system operates without human intervention, autonomously formulating scientific questions, configuring computational environments, and performing result evaluation and validation [19].
Table 2: Performance Metrics of DREAM Autonomous Research System
| Evaluation Metric | DREAM Performance | Top Human Scientists | Graduate Students | GPT-4 |
|---|---|---|---|---|
| Question Difficulty Score | Exceeded top-tier articles by 5.7% | Baseline | 56.0% lower than DREAM | 58.6% lower than DREAM |
| Question Originality | 12.3% gain over initial questions | Baseline | >40% lower than DREAM | >40% lower than DREAM |
| Research Efficiency (Framingham Heart Study) | 10,000x average scientists | Baseline | Not measured | Not measured |
| Success Rate in Environment Configuration | Higher than experienced human researchers | Baseline | Not measured | Not measured |
DREAM's architecture incorporates multiple data interpretation modules (dataInterpreter, questionRaiser, variableGetter, taskPlanner, codeMaker, dockerMaker, codeDebugger, resultJudger, resultAnalyzer, resultValidator, deepQuestioner) that process diverse data streams to enable robust autonomous decision-making [19]. After four evolutionary rounds, 68% of DREAM's generated questions were successfully addressed, with 10% surpassing published articles in originality and complexity [19].
Methodologies: Experimental Protocols for Orthogonal Workflows
Protocol: Modular Robotic Workflow for Exploratory Synthesis
The autonomous chemistry platform exemplifies a meticulously designed protocol for orthogonal characterization [14]:
Synthesis Module: Reactions are performed in a Chemspeed ISynth synthesizer, which automatically takes aliquots of each reaction mixture upon completion.
Sample Reformating: The synthesizer reformats samples separately for MS and NMR analysis to ensure optimal preparation for each technique.
Mobile Robot Transportation: Free-roaming mobile robots handle samples and transport them to the appropriate analytical instruments (UPLC-MS and benchtop NMR), enabling physical integration of distributed laboratory equipment.
Parallel Data Acquisition: Customizable Python scripts autonomously operate both analytical instruments, with resulting data saved to a central database.
Heuristic Decision-Making: A domain-expert-designed algorithm processes both UPLC-MS and 1H NMR data, applying experiment-specific pass/fail criteria to each analytical technique.
Combinatorial Assessment: Binary results from each analysis are combined to give pairwise grading for each reaction, determining which experiments proceed to subsequent stages.
This protocol successfully bridges the gap between automated experimentation (where researchers make decisions) and true autonomy (where machines interpret data and make decisions) [14]. The modular design allows instruments to be shared with human researchers without monopolization or requiring extensive laboratory redesign [14].
Protocol: Fully Autonomous Biomedical Research System
The DREAM system implements a different but equally sophisticated protocol for autonomous research [19]:
Data Interpretation: The dataInterpreter module autonomously interprets information from structured biomedical datasets, including omics and clinical data.
Question Generation: The questionRaiser module generates research questions directly from data, filtered for research value using defined scoring criteria.
Variable Screening: Relevant variables are identified (variableGetter) for each research question.
Task Planning: The taskPlanner designs appropriate analysis tasks and steps.
Code Generation: Analytical code is automatically written (codeMaker) to implement the planned analyses.
Environment Configuration: Computational environments are automatically configured (dockerMaker) without human intervention.
Execution and Debugging: The codeDebugger executes and debugs analytical code as needed.
Result Judgment: The resultJudger evaluates results against research questions.
Interpretation and Validation: Results are interpreted (resultAnalyzer) and validated (resultValidator) against literature and cross-datasets.
Self-Evolution: The deepQuestioner formulates more complex questions based on previous outcomes, enabling continuous research progression.
This UNIQUE paradigm (Question, codE, coNfIgure, jUdge) enables fully autonomous operation across the entire research lifecycle [19].
Visualization: Workflow Architectures for Orthogonal Data Integration
Orthogonal Characterization Workflow in Autonomous Chemistry
Self-Evolving Autonomous Research System Architecture
Implementation: The Researcher's Toolkit for Autonomous Workflows
Successful implementation of orthogonal characterization in autonomous workflows requires specific technical components and analytical resources. The following table details essential research reagent solutions and their functions in enabling robust multi-stream decision-making.
Table 3: Research Reagent Solutions for Orthogonal Characterization Workflows
| Component Category | Specific Solution | Function in Autonomous Workflow | Key Capabilities |
|---|---|---|---|
| Robotic Hardware | Mobile robot agents with multipurpose grippers | Sample transportation and instrument operation | Free-roaming mobility enables distributed instrument access without laboratory redesign [14] |
| Synthesis Platform | Chemspeed ISynth synthesizer | Automated chemical synthesis with aliquot capability | Combinatorial chemistry execution with automatic sample reformatting for multiple analyses [14] |
| Analytical Instrumentation | UPLC-MS system | Molecular separation and mass detection | Provides retention time, peak area, and molecular weight data for reaction assessment [14] |
| Analytical Instrumentation | Benchtop NMR spectrometer | Molecular structure characterization | Delivers structural information complementary to MS data [14] |
| Decision Algorithms | Heuristic decision-maker | Orthogonal data integration and pass/fail assessment | Combines binary results from multiple analyses using domain-expert-defined criteria [14] |
| Control Software | Customizable Python scripts | Instrument control and data acquisition | Enables autonomous operation of unmodified laboratory equipment [14] |
| Data Management | Central database | Storage and retrieval of multimodal analytical data | Maintains integrated data from multiple characterization techniques [14] |
| Autonomous Research System | DREAM framework | End-to-end autonomous research without human intervention | Implements UNIQUE paradigm for continuous self-evolving research [19] |
Regulatory and Practical Considerations
The implementation of multi-stream autonomous workflows operates within an evolving regulatory landscape, particularly for drug development applications. The U.S. FDA has established the CDER AI Council to provide oversight, coordination, and consolidation of activities around AI use, responding to a significant increase in drug application submissions using AI components [8]. The European Medicines Agency has articulated a risk-based approach focusing on 'high patient risk' applications and 'high regulatory impact' cases [18]. Notably, the EMA framework prohibits incremental learning during clinical trials to ensure the integrity of clinical evidence generation, while permitting continuous model enhancement in post-authorization phases with rigorous validation and monitoring [18].
Practical implementation must also address computational efficiency concerns. Methods like Orthogonal Recursive Fitting (ORFit) demonstrate approaches for one-pass learning that update parameters in directions orthogonal to past gradients, minimizing disruption of previous predictions while incorporating new data [20]. This is particularly valuable for autonomous systems operating on streaming data where storing and reprocessing all previous data is computationally prohibitive.
The integration of multiple orthogonal data streams represents a fundamental advancement in autonomous research systems, enabling decision-making robustness that exceeds the capabilities of single-characterization approaches. Experimental evidence from both chemical synthesis and biomedical research demonstrates that systems leveraging complementary data streams achieve superior performance in identifying successful experiments, generating novel insights, and maintaining reproducibility. As these technologies mature, their impact will increasingly transform scientific discovery from a human-directed process to a collaborative partnership between researchers and autonomous systems. The continued evolution of regulatory frameworks, computational methods, and instrumentation integration will further enhance the capabilities of these systems, potentially accelerating the pace of scientific discovery by orders of magnitude and opening new frontiers in exploratory science.
In the development of complex biologics, ensuring product quality, safety, and efficacy is paramount. Unlike small-molecule drugs, biologics are large, complex molecules produced by living systems, making them inherently heterogeneous and sensitive to manufacturing conditions [21] [22]. This complexity necessitates a rigorous framework for defining and controlling Critical Quality Attributes (CQAs)—physical, chemical, biological, or microbiological properties that must remain within appropriate limits to ensure desired product quality [21]. Among these, Identity, Potency, Purity, and Stability stand as the four foundational pillars. With the advent of autonomous workflows and advanced analytical techniques, the pharmaceutical industry is undergoing a transformation in how these attributes are characterized and controlled. This guide provides a comparative analysis of the experimental methodologies used to assess these key attributes, focusing on the integration of orthogonal characterization within modern, automated research environments.
Identity Confirmation
Core Concept and Analytical Techniques
Identity refers to the definitive confirmation of a biologic's molecular structure, including its primary amino acid sequence and higher-order structure. Verifying identity ensures that the product is what it claims to be, a fundamental requirement for safety and consistency [23].
- Primary Structure Analysis: Peptide mapping using Liquid Chromatography-Mass Spectrometry (LC-MS) is a gold standard for confirming the amino acid sequence and identifying post-translational modifications such as oxidation or deamidation [23]. High-resolution mass spectrometry further pinpoints these modifications and can confirm disulfide bond arrangements [23].
- Higher-Order Structure Analysis: Techniques like Circular Dichroism (CD) and Fourier-Transform Infrared (FTIR) spectroscopy probe the secondary and tertiary structure of the protein, confirming its correct folding [23]. Hydrogen–deuterium exchange mass spectrometry (HDX-MS) is an advanced method for characterizing higher-order structure and dynamics in solution [23].
Autonomous Workflow Integration
In autonomous laboratories, the identity confirmation workflow can be seamlessly integrated. A robotic system can prepare samples from a synthesis module, transport them via a mobile robot to a benchtop NMR spectrometer and a UPLC-MS for analysis, and feed the orthogonal data into a central database for a heuristic decision-maker to provide a pass/fail grade [2]. This closed-loop system mimics human protocols but with enhanced reproducibility and speed.
Table 1: Key Analytical Techniques for Assessing Identity
| Quality Attribute | Analytical Technique | Key Information Provided | Suitability for Autonomous Workflows |
|---|---|---|---|
| Identity | Peptide Mapping (LC-MS) | Amino acid sequence verification, post-translational modifications | High (Automated sample processing and data analysis) |
| High-Resolution Mass Spectrometry | Precise molecular weight, disulfide bond confirmation | High | |
| Circular Dichroism (CD) | Secondary and tertiary structure confirmation | Medium (Requires specific sample preparation) | |
| HDX-MS | Higher-order structure and dynamics in solution | Medium (Complex data interpretation) |
Potency Assessment
Core Concept and Bioassays
Potency is a quantitative measure of a biologic's biological activity, directly linked to its mechanism of action and therapeutic effect. It ensures that each batch of the product can elicit the desired clinical response [22] [24].
- Cell-Based Bioassays: These assays measure a functional response, such as antibody-dependent cell-mediated cytotoxicity (ADCC) or cytokine neutralization, reflecting the biologic's intended mechanism of action in a live-cell system [23].
- Binding Assays: Techniques like Enzyme-Linked Immunosorbent Assay (ELISA) determine affinity and specificity. Surface Plasmon Resonance (SPR) provides kinetic data (on-rate/off-rate) and active concentration, offering a more detailed immunological profile [23].
Data-Driven Decision-Making
Potency is a primary driver for lead selection in discovery. When multiple candidates show equivalent potency, other developability properties are used for differentiation. Hierarchical clustering analysis (HCA) can be applied to high-dimensional data from potency and other developability assays to systematically rank molecules and identify optimal leads with the best combination of properties, streamlining decision-making [25].
Purity and Impurity Analysis
Core Concept and Variants
Purity refers to the freedom from product-related and process-related impurities. Product-related variants include aggregates, fragments, and charge isoforms, while process-related impurities can include host cell proteins and DNA [24] [23].
- Size Variants: Size Exclusion Chromatography-High Performance Liquid Chromatography (SEC-HPLC) is critical for differentiating aggregates and high molecular weight species from the desired monomeric product, which are key indicators of instability [24] [23]. Capillary electrophoresis (CE-SDS) is also routinely used [23].
- Charge Variants: Ion Exchange (IEX)-HPLC and isoelectric focusing are recommended for monitoring charge state variants that arise from modifications like deamidation or sialylation [24].
- Orthogonality in Autonomous Systems: The combination of UPLC-MS and NMR spectroscopy, as used in modular robotic workflows, provides a powerful orthogonal approach to purity analysis, mitigating the uncertainty of relying on a single measurement [2].
Table 2: Key Analytical Techniques for Assessing Purity and Stability
| Quality Attribute | Analytical Technique | Key Information Provided | Key Measured Output(s) |
|---|---|---|---|
| Purity | SEC-HPLC | Quantification of aggregates and fragments | % Monomer, % High-Molecular-Weight Species |
| IEX-HPLC | Quantification of acidic and basic charge variants | % Acidic Peak, % Main Peak, % Basic Peak | |
| CE-SDS | Purity and aggregation under denaturing conditions | % Purity, % Fragments | |
| Stability | SEC-HPLC (Stability Indicating) | Monitoring aggregate formation over time | Increase in % Aggregates over time |
| First-Order Kinetic Modeling | Predicting long-term stability and shelf-life | Rate constant (k), Predicted shelf-life | |
| Accelerated Stability Studies | Identifying degradation pathways under stress | Degradation rate at elevated temperatures |
Stability Profiling
Core Concept and Degradation Pathways
Stability is the ability of a drug substance or product to retain its properties within specified limits throughout its shelf life. For biologics, instability often manifests as fragmentation or aggregation, which can lead to a loss of efficacy or increased immunogenicity [24].
- Stability-Indicating Methods: As per ICH Q5C, a stability-testing program should include long-term, accelerated, and stress studies [24]. SEC-HPLC is a cornerstone method for monitoring stability, as it can track the increase in aggregates and fragments over time [24].
- Predictive Kinetic Modeling: Traditionally, predicting long-term stability was challenging. However, recent advances demonstrate that simplified first-order kinetic models combined with the Arrhenius equation can accurately predict long-term stability for various quality attributes, including aggregates, across different protein modalities (e.g., IgG1, bispecifics, scFv) [26]. This Accelerated Predictive Stability (APS) approach is more precise than linear extrapolation and is being incorporated into revised ICH guidelines [26].
Experimental Protocol: Predictive Stability Modeling
The protocol for APS involves:
- Study Design: Expose the biologic to a range of temperatures (e.g., 5°C, 25°C, 40°C) for a defined period (e.g., 12-36 months) [26].
- Sample Pull Points: At predefined intervals, samples are taken and analyzed using a stability-indicating method like SEC to quantify attributes like % aggregates [26].
- Data Modeling: The degradation data at each temperature is fitted using a first-order kinetic model. The model is simplified to avoid overfitting, often focusing on a single dominant degradation pathway relevant to storage conditions [26].
- Arrhenius Plotting: The reaction rate constants (k) at different temperatures are used in the Arrhenius equation to extrapolate the degradation rate at the recommended storage temperature (e.g., 2-8°C), enabling shelf-life prediction [26].
The Autonomous Workflow: Integrating Orthogonal Characterization
Modern autonomous laboratories are revolutionizing biologics characterization by integrating disparate modules into a single, closed-loop workflow. This approach leverages robotics and heuristic or AI-driven decision-making to execute exploratory synthesis and characterization with minimal human intervention [2].
The Scientist's Toolkit: Essential Research Reagent Solutions
The following table details key reagents, materials, and instruments essential for the characterization of biologics, particularly within advanced automated workflows.
Table 3: Essential Research Reagent Solutions for Biologics Characterization
| Item | Function/Application | Key Characteristics |
|---|---|---|
| UPLC-MS System | Orthogonal analysis for identity (peptide mapping) and purity. Combines chromatographic separation with mass detection. | High resolution, sensitivity, and compatibility with automated data pipelines [2] [23]. |
| Benchtop NMR Spectrometer | Orthogonal analysis for identity and higher-order structure confirmation. Provides atomic-level structural information. | Lower footprint for lab integration, operable by robotic agents [2]. |
| Size Exclusion Chromatography (SEC) Column | Critical for purity and stability analysis, separating monomers from aggregates and fragments. | High resolution for quantitating low-abundance species; used with specific mobile phases [26] [24]. |
| Surface Plasmon Resonance (SPR) Chip | Functional characterization for potency; measures binding kinetics (kon, koff) and affinity (KD). | Coated with antigen or other binding partner for specific interaction studies [23]. |
| Automated Synthesis Platform (e.g., Chemspeed ISynth) | Executes synthetic operations and sample preparation autonomously based on AI/heuristic instructions. | Modular, integrable with robotic sample handlers for end-to-end automation [2]. |
| Mobile Robot Agents | Physical linkage between synthesis and analysis modules; transport samples and labware. | Free-roaming, capable of operating standard laboratory equipment [2]. |
The rigorous assessment of Identity, Potency, Purity, and Stability is non-negotiable for developing safe and effective complex biologics. The landscape of characterization is being profoundly reshaped by the adoption of autonomous workflows that integrate orthogonal analytical techniques like UPLC-MS and NMR, coupled with data-driven decision-making through heuristic algorithms or machine learning. These advanced approaches, including predictive kinetic modeling for stability and hierarchical clustering for lead selection, enable a more efficient, reproducible, and in-depth understanding of Critical Quality Attributes. As these technologies mature, they promise to accelerate the pace of biologics development from discovery to commercial manufacturing, ensuring that high-quality therapeutics reach patients faster and more reliably.
The biological complexity of Cell and Gene Therapy (CGT) products, comprising viable cells, genetic material, and viral vectors, represents a fundamental departure from traditional small-molecule drugs [27]. This complexity necessitates rigorous quality control strategies to ensure product efficacy, patient safety, and batch-to-batch consistency [27]. An orthogonal approach—which employs multiple independent analytical methods to assess the same quality attribute—has become a regulatory expectation and scientific necessity for comprehensive product characterization [27]. This methodology mitigates the risk of false results inherent to any single analytical technique and provides a more complete understanding of Critical Quality Attributes (CQAs). Furthermore, the emergence of autonomous laboratories and AI-driven workflows is poised to integrate these orthogonal methods into seamless, automated characterization pipelines, accelerating development while maintaining rigorous quality standards [28].
Critical Quality Attributes and the Orthogonal Approach
For CGT products, key CQAs typically include identity, potency, purity, and for cell-based products, viability [27]. The orthogonal strategy is applied by using different analytical techniques that provide independent but complementary data on each attribute.
Table 1: Orthogonal Methods for Critical Quality Attribute Analysis
| Critical Quality Attribute | Analytical Technique 1 | Analytical Technique 2 | Additional Techniques | Primary Application |
|---|---|---|---|---|
| Identity (Cell Therapy) | Flow Cytometry (Phenotype) [27] | STR Profiling (Genotype) [27] | Karyological Analysis [27] | Confirms cell population and donor source [27] |
| Identity (Viral Vector) | Restriction Analysis [27] | Transgene Sequencing [27] | Dynamic Light Scattering (DLS) [27] | Verifies vector construct and physical properties [27] |
| Potency | Functional Cell-Based Assays [27] | Cytokine Secretion Profile [27] | Transgene Expression Analysis [27] | Measures biological activity [27] |
| Purity (Full/Empty Capsids) | Analytical Ultracentrifugation (AUC) [27] [29] | SEC-MALS [27] [29] | Mass Photometry, dPCR/ELISA [29] | Quantifies product-related impurities [27] |
| Genome Integrity | digital PCR (dPCR) [29] | Next-Generation Sequencing (NGS) [29] | Gel Electrophoresis [29] | Assesses integrity of packaged genetic material [29] |
Identity Testing
Identity confirmation ensures the product contains the correct biological components. For cell therapies, this involves a multi-level characterization:
- Phenotypic Analysis: Techniques like flow cytometry confirm the identity of the cell population by detecting specific surface and intracellular markers [27].
- Genotypic Analysis: Short Tandem Repeat (STR) profiling provides a genetic fingerprint, crucial for verifying the autologous or allogeneic origin of cells and ensuring they have not been cross-contaminated [27].
- Karyological Analysis: This assesses genetic stability, providing indirect evidence of safety concerning tumorigenic potential [27].
For viral vector-based gene therapies, identity is confirmed through a combination of methods that analyze the vector itself and its functional output. Restriction analysis and transgene sequencing characterize the genetic construct, while biophysical methods like Dynamic Light Scattering (DLS) can determine the size of viral particles, helping to distinguish between full and empty capsids [27].
Potency and Purity Assessment
Potency, a measure of the product's biological activity, is often evaluated using functional assays tailored to the mechanism of action. For a CAR-T cell product, this could involve measuring target cell killing or cytokine secretion upon target engagement [27]. Purity often focuses on quantifying product-related impurities, with the full-to-empty capsid ratio being a major CQA for AAV-based gene therapies. The presence of empty capsids is an impurity that can reduce efficacy and trigger immune responses [27].
Table 2: Orthogonal Methods for Full/Empty Capsid Ratio and Genome Integrity Analysis
| Method | Principle | Key Advantage | Key Limitation | Role in Orthogonality |
|---|---|---|---|---|
| Analytical Ultracentrifugation (AUC) | Separates particles by buoyant density under centrifugal force [27]. | Considered a gold standard; can resolve full, partial, and empty capsids [27]. | Low-throughput, not ideal for GMP release [27]. | Primary method for in-depth characterization [27]. |
| SEC-MALS | Separates by size, then measures mass via light scattering [27]. | Suitable for quality control in GMP release [27]. | Cannot separate partially filled capsids [27]. | Orthogonal QC method correlated with AUC [29]. |
| Mass Photometry | Measures mass of individual particles by light scattering [29]. | Rapid, label-free analysis at the single-particle level. | Emerging technique, requires further standardization. | Provides orthogonal mass measurements. |
| dPCR/ELISA | dPCR quantifies genome copies; ELISA quantifies total capsids [29]. | High sensitivity and suitability for routine QC [29]. | Indirect ratio calculation; requires two separate assays. | Fast, cost-effective orthogonal check [29]. |
The evaluation of genome integrity—the proportion of full-length, correctly assembled genetic sequences within viral vectors—has emerged as a critical parameter closely linked to potency. Digital PCR (dPCR) is advancing as a key tool here, with multiplex assays designed to target different regions of the genome (e.g., promoter, poly-A tail, and internal regions) to provide a percentage of intact genomes [29]. This data has shown strong correlation with potency assay results, explaining observed variations in biological activity [29]. dPCR results are often validated orthogonally by Next-Generation Sequencing (NGS), which provides base-by-base sequence information but is more time-consuming and costly [29].
The Autonomous Workflow: Integrating Orthogonal Characterization
The future of CGT characterization lies in the integration of orthogonal methods into intelligent, automated systems. Autonomous laboratories are demonstrating how AI-driven decision-making can be coupled with robotic experimentation to create closed-loop discovery and characterization cycles [28] [14].
These systems seamlessly integrate various instruments. For instance, a modular robotic workflow can use mobile robots to transport samples between an automated synthesis platform, a liquid chromatography–mass spectrometer (UPLC-MS), and a benchtop NMR spectrometer [14]. A central heuristic decision-maker then processes this orthogonal analytical data (MS and NMR spectra) to automatically grade reaction outcomes and determine the next experimental steps, mimicking human expert judgment [14].
The diagram above illustrates a generalized autonomous R&D workflow. The critical phase of "Orthogonal Analysis" is where multiple characterization techniques are executed, and their data is fed into the decision-making algorithm. This mirrors the manual orthogonal approach but achieves unprecedented speed and consistency by eliminating human downtime and subjective bias [28] [14]. As noted in research on AI-driven labs, "By tightly integrating these stages... autonomous labs aim to turn processes that once took months of trial and error into routine high-throughput workflows" [28].
Experimental Protocols in Practice
Protocol: Genome Integrity Analysis via Multiplex Digital PCR
Purpose: To determine the percentage of intact versus fragmented viral genomes in an AAV-based gene therapy product [29].
Key Reagent Solutions:
- QIAGEN CGT Viral Vector Lysis Kit: For digesting host cell DNA and releasing the viral genome for analysis. The included DNAse is critical for removing contaminating DNA [29].
- Cell and Gene Therapy Assays for dPCR (QIAGEN): Pre-designed assays targeting specific regions of the genome (e.g., ITR, promoter, poly-A tail, and internal gene sequence) [29].
- Universal AAV Standard (Agathos Biologics): A well-characterized control template that allows for comparative analysis and validation of dPCR assays across different targets and products [29].
Methodology:
- Lysis and Digestion: Incubate the A vector sample with the lysis kit to break open the capsids and digest any external DNA [29].
- Assay Design: A multiplex dPCR assay is designed with probes targeting at least two, but ideally more, distinct regions of the viral genome. A common strategy is to place one probe at the 5' end (e.g., near a promoter) and another at the 3' end (e.g., near the poly-A tail). The co-localization of signals from both probes in a single droplet indicates an intact genome [29].
- dPCR Run: The lysed sample is partitioned into thousands of nanodroplets, and PCR amplification is performed [29].
- Data Analysis: The software (e.g., QIAcuity Software v3.1) automatically calculates the percentage of droplets positive for all target regions, providing the genome integrity percentage. Advanced software features include cross-talk compensation to prevent signal bleed-through between different fluorescent probes [29].
Orthogonal Validation: The results from the dPCR integrity assay are validated using Next-Generation Sequencing (NGS), which provides direct sequence information to confirm the presence of full-length, correct sequences [29].
Protocol: Full/Empty Capsid Ratio Analysis
Purpose: To quantify the ratio of genome-filled capsids (full) to non-genome-containing capsids (empty) in a final AAV product lot.
Methodology 1: Analytical Ultracentrifugation (AUC)
- Principle: Capsids are separated in a density gradient under high centrifugal force. Full capsids (denser due to the DNA genome) sediment at a different rate than empty capsids (less dense) [27].
- Procedure: The product is loaded into a centrifuge cell with a stabilizing gradient medium (e.g., cesium chloride). After prolonged centrifugation, the separated bands are detected optically, and their relative areas are quantified to determine the ratio [27].
- Application: Best suited for in-depth product characterization during development due to its resolution but lower throughput [27].
Methodology 2: Size-Exclusion Chromatography with Multi-Angle Light Scattering (SEC-MALS)
- Principle: SEC separates particles by size, with empty capsids typically eluting slightly later than full capsids. The connected MALS detector then measures the absolute molar mass of the eluting particles, providing unambiguous distinction between full and empty populations based on mass [27] [29].
- Procedure: The product is injected into an SEC column. The eluent passes through a UV detector and a MALS detector. The mass data from MALS is cross-referenced with the elution volume to identify and quantify each population [27].
- Application: More suitable than AUC for quality control during GMP batch release due to higher throughput and automation compatibility [27].
The adoption of orthogonal methods is non-negotiable for the rigorous characterization required to bring safe and effective CGT products to market. The synergistic use of techniques like dPCR/AUC/SEC-MALS for capsid analysis and flow cytometry/STR for cell identity provides a robust safety net against analytical errors and a deeper product understanding. The field is rapidly evolving toward the integration of these methods into AI-driven autonomous workflows, where robotic systems execute synthesis, orthogonal analysis, and data-driven decision-making in a continuous loop. This convergence of rigorous analytical science and intelligent automation promises to accelerate the development of these transformative therapies while upholding the highest standards of quality and safety.
From Theory to Practice: Implementing Orthogonal Workflows in Self-Driving Labs
The field of scientific discovery is undergoing a profound transformation, driven by the integration of artificial intelligence (AI), robotics, and orthogonal characterization techniques into a continuous, closed-loop cycle. Autonomous laboratories, or "self-driving labs," represent a powerful strategy to accelerate scientific experimentation by seamlessly combining these elements into workflows that require minimal human intervention [28]. At the core of this paradigm shift is the move from traditional, linear research processes to an iterative cycle where AI plans experiments, robotic systems execute them, and multiple analytical techniques provide complementary (orthogonal) data on the results. This data then informs the next cycle of AI-driven planning [2] [28]. This article objectively compares the performance of several pioneering autonomous platforms, focusing on their architectural approaches to integrating orthogonal characterization—the use of multiple, independent measurement techniques to unambiguously identify reaction products—a critical capability for exploratory research in fields like drug development and materials science [2].
Comparative Analysis of Autonomous Platforms
The following section compares three distinct architectural implementations of the closed-loop principle, highlighting their unique strategies for integrating AI, robotics, and analysis.
The Mobile Robotics Platform for Exploratory Chemistry
A modular autonomous platform for exploratory synthetic chemistry demonstrates a highly flexible architecture. It uses free-roaming mobile robots to physically connect an automated synthesis platform (Chemspeed ISynth) with standalone analytical instruments: an ultrahigh-performance liquid chromatography–mass spectrometer (UPLC-MS) and a benchtop nuclear magnetic resonance (NMR) spectrometer [2]. This setup allows robots to share existing laboratory equipment with human researchers without requiring extensive redesign or monopolizing instruments [2].
- Decision-Making Protocol: Unlike optimization-focused systems, this platform employs a heuristic decision-maker designed by domain experts. It processes orthogonal UPLC-MS and NMR data, assigning a binary pass/fail grade to each analysis based on experiment-specific criteria. Reactions must pass both analyses to proceed to the next stage, such as scale-up or functional assays, mimicking human expert judgment [2].
- Performance and Application: This workflow has been successfully applied to structural diversification chemistry, supramolecular host-guest chemistry, and photochemical synthesis. In supramolecular chemistry, where reactions can yield multiple products, the "loose" heuristic decision-maker remains open to novelty, facilitating genuine chemical discovery rather than just optimizing for a single, known metric [2].
A-Lab: The AI-Driven Materials Synthesis Platform
A-Lab is a fully autonomous solid-state synthesis platform specifically designed for inorganic materials discovery [28]. Its workflow is a tightly integrated, computationally driven closed loop.
- Decision-Making Protocol: A-Lab's intelligence is rooted in AI and machine learning. It begins by selecting novel, theoretically stable materials from large-scale ab initio databases. Natural-language models trained on vast literature data generate synthesis recipes. After robotic execution, machine learning models, particularly convolutional neural networks, analyze X-ray diffraction (XRD) patterns for phase identification. An active-learning algorithm (ARROWS3) then iteratively improves synthesis routes based on the results [28].
- Performance and Application: In a seminal demonstration, A-Lab operated continuously for 17 days, successfully synthesizing 41 out of 58 target inorganic materials predicted by density functional theory (DFT), achieving a 71% success rate with minimal human input [28]. This showcases the power of a dedicated, AI-centric platform for high-throughput materials discovery.
The Pyiron Framework: Integrating Simulation and Experimentation
The pyiron framework offers an integrated development environment (IDE) originally designed for high-throughput computational materials science that has been extended to include experimental data acquisition [30]. This approach focuses on fusing data from simulations and experiments within a single platform.
- Decision-Making Protocol: Pyiron implements an Active Learning loop with a direct interface to experimental equipment. It uses Gaussian Process Regression (GPR) to model a material's property (e.g., electrical resistance across a composition spread) and to suggest the most informative next measurement point. A key feature is its ability to use prior knowledge from density functional theory (DFT) simulations and literature mining to accelerate the learning process [30].
- Performance and Application: This strategy optimizes the measurement process itself, drastically reducing the number of actual measurements required to characterize a material library with a defined uncertainty. By leveraging existing knowledge, it accelerates the entire materials discovery cycle, demonstrating a pathway toward partially autonomous research systems where computational and experimental resources collaborate [30].
Quantitative Performance Comparison
The table below summarizes the key performance metrics and characteristics of the three platforms.
Table 1: Performance Comparison of Autonomous Laboratory Platforms
| Platform Feature | Mobile Robotics Platform [2] | A-Lab [28] | Pyiron Framework [30] |
|---|---|---|---|
| Primary Domain | Exploratory Synthetic Chemistry | Inorganic Materials Synthesis | Materials Characterization & Discovery |
| Central AI Model | Heuristic Decision-Maker | Natural Language Models, Convolutional Neural Networks, Active Learning | Gaussian Process Regression, Active Learning |
| Key Robotic Component | Free-roaming Mobile Robots | Integrated Robotic Arms | Interface to Measurement Devices |
| Orthogonal Characterization | UPLC-MS & Benchtop NMR | X-ray Diffraction (XRD) | Electrical Resistance, prior DFT/data |
| Reported Success Rate/Outcome | Successful application in multi-step synthesis & host-guest assays | 71% (41/58 target materials synthesized) | Order-of-magnitude reduction in required measurements |
| Key Strength | Flexibility, use of existing lab equipment | High-throughput, end-to-end autonomy | Fusion of simulation and experimental data |
Experimental Protocols for Orthogonal Characterization
The reliability of an autonomous workflow hinges on its experimental protocols. This section details the methodologies for the key analytical techniques cited.
Protocol 1: Heuristic Analysis of UPLC-MS and ¹H NMR Data
This protocol is designed for the mobile robotics platform to assess the outcome of organic and supramolecular synthesis reactions [2].
- Sample Preparation: Upon reaction completion, the Chemspeed ISynth synthesizer automatically takes an aliquot of the reaction mixture and reformats it into separate vials suitable for MS and NMR analysis.
- Sample Transport: Mobile robots retrieve the vials and transport them to the respective instruments (UPLC-MS and benchtop NMR), which are located elsewhere in the laboratory.
- Data Acquisition:
- UPLC-MS: The system runs a standardized method to separate reaction components and acquire mass spectrometry data.
- ¹H NMR: The benchtop NMR spectrometer acquires proton nuclear magnetic resonance spectra.
- Autonomous Data Processing & Decision:
- MS Analysis: The decision-maker uses a precomputed m/z lookup table to identify expected and unexpected masses.
- NMR Analysis: The decision-maker uses dynamic time warping to detect reaction-induced spectral changes compared to controls.
- Heuristic Fusion: Each analysis receives a binary pass/fail. The results are combined, and a reaction must pass both to be considered a "hit" and proceed to the next stage (e.g., replication or scale-up).
Protocol 2: ML-Driven Phase Identification for Solid-State Materials
This protocol is central to the A-Lab's operation for identifying synthesized inorganic materials [28].
- Synthesis: Robotic arms handle precursor powders, mix them, and pelletize the mixture. The pellet is heated in a furnace at a temperature suggested by the AI.
- Characterization: After synthesis, the sample is automatically transferred to an X-ray diffractometer for structural characterization.
- Phase Analysis: The acquired XRD pattern is fed into a machine learning model (a convolutional neural network) trained on a vast database of known diffraction patterns.
- Identification and Optimization: The ML model identifies the crystalline phases present in the sample. If the target material is not formed or is impure, the active learning algorithm (ARROWS3) analyzes the result and proposes a modified synthesis recipe (e.g., different precursors or heating temperature) for the next iteration.
Workflow Architecture Visualization
The following diagram illustrates the core closed-loop logic that is common to advanced autonomous laboratories, integrating the key stages of planning, execution, and analysis.
Diagram 1: Generic autonomous laboratory workflow.
The Scientist's Toolkit: Essential Research Reagents & Platforms
This section details the key hardware and software components that form the foundation of modern autonomous research workflows.
Table 2: Key Research Reagents and Platforms for Autonomous Workflows
| Tool / Platform Name | Type | Primary Function in the Workflow |
|---|---|---|
| Chemspeed ISynth | Automated Synthesis Platform | Performs automated liquid handling, reagent dispensing, and reaction control in an inert atmosphere [2]. |
| UPLC-MS | Analytical Instrument | Provides orthogonal data on reaction components through separation (chromatography) and mass identification (spectrometry) [2]. |
| Benchtop NMR | Analytical Instrument | Provides orthogonal data on molecular structure and reaction progress via nuclear magnetic resonance spectroscopy [2]. |
| X-ray Diffractometer | Analytical Instrument | Identifies crystalline phases and structure in solid-state materials synthesis [28]. |
| Mobile Robots | Robotic Agent | Transports samples between modular stations (synthesis, MS, NMR), enabling flexibility and shared lab equipment [2]. |
| Pyiron | Software Framework | An integrated development environment (IDE) that manages data, automates workflows, and combines simulation and experimental data [30]. |
| Gaussian Process Regression | AI/ML Model | A surrogate model used in active learning to predict material properties and suggest optimal next experiments [30]. |
The development of modern biopharmaceuticals, particularly complex engineered proteins and antibody-based therapeutics, demands a rigorous analytical approach to ensure product quality, safety, and efficacy. Reliable biophysical characterization is essential for assessing critical quality attributes such as purity, folding stability, aggregation propensity, and overall conformational integrity [15]. Orthogonal analytical strategies—which employ multiple, independent measurement techniques to cross-validate results—have become foundational to autonomous workflows in pharmaceutical research. By integrating techniques like UPLC-MS/MS, NMR, DLS, SEC, and NanoDSF, scientists can build comprehensive and robust datasets that overcome the limitations of any single method. This guide provides an objective comparison of these key instrumentation tools, supported by experimental data, to inform their application in therapeutic development pipelines.
Each technique in the analytical toolbox provides unique insights into different aspects of a molecule's properties. The following table summarizes their primary functions, key performance metrics, and comparative advantages.
Table 1: Performance Comparison of Key Analytical Techniques
| Technique | Primary Function | Key Measured Parameters | Typical Analysis Time | Sample Consumption | Key Strengths |
|---|---|---|---|---|---|
| UPLC-MS/MS | Quantitative analysis of small molecules and some biologics [31] | Retention time, mass-to-charge ratio, concentration [32] | 2-5 min per sample [32] | Low (µL volumes) [32] | High sensitivity, specificity, and throughput [32] |
| NanoDSF | Protein conformational stability [33] | Melting temperature (Tm), onset of unfolding (Ton) [33] | 30-90 min (including temp. ramp) | Low (10 µL capillaries) [15] | Label-free, uses intrinsic fluorescence [34] |
| DLS | Hydrodynamic size and aggregation [15] | Hydrodynamic radius (Rh), polydispersity [15] | Minutes | Low (µL volumes) | Measures size distribution in native state |
| SEC | Size-based separation and purity [15] | Elution volume/profile, molecular weight [15] | 10-30 min | Moderate (50-100 µL) | Gold standard for quantifying aggregates |
| NMR | Atomic-level structure and dynamics | Chemical shift, relaxation times | Hours to days | High (mg amounts) | Provides atomic-resolution structural data |
Table 2: Quantitative Performance Data from Representative Studies
| Technique | Application Context | Reported Precision/Accuracy | Key Performance Metric |
|---|---|---|---|
| UPLC-MS/MS | Voriconazole quantification in plasma [35] | Inter-/intra-day RSD < 15% [35] | Linear range: 0.1 - 10.0 mg/L [35] |
| UPLC-MS/MS | Intestinal permeability markers [31] | CV% ≤ 15%, accuracy ±15% [31] | LLOQ: meets FDA criteria [31] |
| NanoDSF | Membrane protein thermostability [34] | Identifies distinct Tm values (e.g., 70.5°C, 77.5°C) [34] | Detects complex, multi-state unfolding [34] |
| DLS & SEC | Engineered antibody constructs [15] | Differentiates monomeric vs. aggregated species [15] | Reveals increased aggregation in fragments [15] |
Detailed Experimental Protocols
UPLC-MS/MS for Quantitative Bioanalysis
The application of UPLC-MS/MS for quantifying intestinal permeability markers (atenolol, propranolol, quinidine, verapamil) in Caco-2 cell models exemplifies a validated protocol for drug development studies [31].
Sample Preparation: Solid-phase extraction (SPE) is employed to enhance analyte recovery and minimize matrix effects. Samples are loaded onto conditioned SPE cartridges, washed with appropriate buffers, and eluted with a solvent such as methanol or acetonitrile. The eluate is then evaporated to dryness and reconstituted in mobile phase for injection [31].
UPLC Conditions:
- Column: Reversed-phase C18 column (e.g., 2.1 x 100 mm, 1.7-1.8 µm particle size).
- Mobile Phase: Gradient elution with water (containing 0.1% formic acid) and acetonitrile.
- Flow Rate: 0.3-0.4 mL/min.
- Injection Volume: 2-5 µL.
- Run Time: Approximately 5-7 minutes [31].
MS/MS Detection:
- Ionization: Electrospray ionization (ESI) in positive mode.
- Detection: Multiple reaction monitoring (MRM) for each analyte and internal standard.
- Data Analysis: Peak areas are integrated, and calibration curves are constructed using linear regression with 1/x or 1/x² weighting [31].
Method Validation: The protocol follows FDA guidelines, demonstrating selectivity, linearity (r² > 0.998), precision (CV% ≤ 15%), accuracy (within ±15%), and stability under various storage conditions [31].
NanoDSF for Protein Stability Assessment
NanoDSF measures protein thermal stability by monitoring the intrinsic fluorescence of tryptophan residues as they become exposed to solvent during unfolding.
Sample Preparation: Protein samples are buffer-exchanged into a formulation of interest and diluted to a concentration typically between 0.5-2 mg/mL. Samples are loaded into specialized nanoDSF capillaries without the need for dyes or labels [33] [34].
Measurement Protocol:
- The capillary tray is placed into the instrument (e.g., Prometheus Panta).
- A temperature gradient is applied, typically from 20°C to 95°C, with a controlled ramp rate (e.g., 1°C/min).
- The intrinsic fluorescence at 330 nm and 350 nm is continuously monitored [33].
Data Analysis:
- The F350/F330 ratio is plotted against temperature.
- The melting temperature (Tm) is determined as the inflection point of this sigmoidal curve.
- The onset of unfolding (Ton) is identified as the temperature at which the curve first deviates from the baseline [33].
- For membrane proteins in "dark nanodiscs," complex biphasic unfolding patterns can be deconvoluted to reveal multiple transition states [34].
Orthogonal Stability Screening Workflow
An integrated workflow combining DLS, SEC, and nanoDSF provides a comprehensive assessment of protein stability, particularly for engineered antibody constructs [15].
Sample Preparation: Recombinant proteins (e.g., full-length IgG, scFv fragments) are expressed in mammalian cells (e.g., Expi293) and purified via protein-G chromatography. Samples are buffer-exchanged into PBS or a relevant formulation buffer, and concentration is determined by absorbance at 280 nm [15].
Parallel Analysis:
- DLS: Samples are loaded into a cuvette, and the hydrodynamic radius (Rh) and polydispersity index are measured at a fixed temperature (e.g., 25°C) to assess monodispersity and aggregation state [15].
- SEC: Samples are injected onto a size-exclusion column (e.g., Superdex Increase) equilibrated with a suitable mobile phase. The elution profile is monitored by UV absorbance to quantify monomeric and aggregated species based on retention time [15].
- nanoDSF: As described in section 3.2, samples are subjected to a thermal ramp to determine conformational stability parameters (Tm, Ton) [15] [33].
Data Integration: Results are correlated to build a complete picture of protein behavior. For example, a low Tm from nanoDSF may correlate with early elution peaks in SEC and high polydispersity in DLS, indicating poor conformational stability and high aggregation propensity [15].
Integrated Workflow for Protein Stability
Essential Research Reagent Solutions
Successful implementation of these analytical techniques requires specific reagents and materials to ensure reliable and reproducible results.
Table 3: Essential Research Reagents and Materials
| Reagent/Material | Primary Function | Example Application |
|---|---|---|
| Expi293 Cells | Mammalian expression system for transient protein production [15] | Production of recombinant antibodies and fragments [15] |
| Protein-G Columns | Affinity purification of antibodies and Fc-fusion proteins [15] | Isolation of IgG and related constructs from culture supernatant [15] |
| Caco-2 Cell Line | In vitro model of intestinal permeability [31] | Prediction of drug absorption for BCS classification [31] |
| Silica-based SPE Cartridges | Sample clean-up and analyte concentration [31] | Extraction of drugs from biological matrices prior to UPLC-MS/MS [31] |
| Dark Nanodiscs (MSP) | Model membrane system for membrane protein studies [34] | Measuring thermostability of membrane proteins without fluorescent interference [34] |
| NanoDSF Capillaries | Sample holders for label-free thermal stability analysis [33] | Containing protein samples during temperature ramp measurements [33] |
The integration of UPLC-MS, NMR, DLS, SEC, and NanoDSF creates a powerful orthogonal framework for autonomous characterization workflows in drug development. As demonstrated by the experimental data, no single technique provides a complete picture of complex biologics' properties. UPLC-MS/MS excels in sensitive quantification, NanoDSF in label-free stability assessment, DLS in native size distribution, and SEC in aggregate quantification. By understanding the specific capabilities, performance parameters, and implementation protocols of each tool, researchers can design robust, data-driven strategies to advance therapeutic candidates with greater confidence and efficiency.
This guide provides an objective comparison of two leading platforms in autonomous research: the CRESt (Copilot for Real-world Experimental Scientists) platform for materials discovery and a modular system using AI-driven mobile robots for exploratory chemistry. The evaluation is framed within the critical research thesis of assessing orthogonal characterization—the use of multiple, independent measurement techniques—in autonomous workflows.
The core distinction between these platforms lies in their integration philosophy: CRESt is a highly integrated, AI-centric system, while the mobile robot platform employs a modular, physically distributed approach.
CRESt for Materials Discovery: Developed at MIT, CRESt is a comprehensive platform designed to accelerate the discovery of new materials, such as fuel cell catalysts. It functions as an AI assistant that incorporates diverse data sources, including experimental results, scientific literature, microstructural images, and human feedback. Its robotic equipment is used for high-throughput synthesis and testing, with the AI using this multimodal feedback to plan new experiments [36].
Mobile Robots for Exploratory Chemistry: Developed by the University of Liverpool, this platform uses one or more autonomous mobile robots to interconnect existing, unmodified laboratory equipment. The robots transport samples between a synthesis module (e.g., a Chemspeed ISynth synthesizer) and multiple characterization instruments (e.g., a liquid chromatography–mass spectrometer (UPLC-MS) and a benchtop nuclear magnetic resonance (NMR) spectrometer). This creates a modular workflow that shares infrastructure with human researchers without requiring extensive lab redesign [14] [37].
Table 1: Core Architectural Comparison of Autonomous Research Platforms
| Feature | CRESt Platform | Mobile Robot Platform |
|---|---|---|
| Primary Research Domain | Materials Science (e.g., fuel cell catalysts) [36] | Exploratory Synthetic Chemistry (e.g., supramolecular assemblies, drug-like molecules) [14] [37] |
| System Integration | Tightly integrated robotic workcells for synthesis and characterization [36] | Modular and distributed; mobile robots link standalone instruments [14] |
| AI & Decision-Making | Multimodal active learning; uses literature, experimental data, and human feedback to optimize recipes [36] | Heuristic decision-maker; uses rules from domain experts to process orthogonal data (UPLC-MS & NMR) [14] |
| Characterization Philosophy | Emphasizes multimodal data (imaging, composition, performance) and literature context [36] | Emphasizes orthogonal characterization (UPLC-MS and NMR) for verification and decision-making [14] |
| Key Innovation | Natural language interface; leveraging diverse knowledge sources for experiment design [36] | Physical flexibility; leveraging existing lab equipment for autonomous, exploratory workflows [14] |
Experimental Protocols & Orthogonal Characterization
Both platforms automate complex research cycles, but their experimental protocols highlight different approaches to data generation and utilization.
CRESt Workflow for Materials Discovery
The CRESt platform operates a closed-loop "design-make-test-analyze" cycle for materials [36].
- Design: The researcher converses with CRESt via natural language. The system's AI then suggests new material recipes, incorporating insights from scientific literature and previous experimental data.
- Synthesis & Characterization: A liquid-handling robot and a carbothermal shock system synthesize the proposed materials. The platform uses automated electron microscopy, X-ray diffraction, and other characterization tools to analyze the results.
- Testing: An automated electrochemical workstation evaluates the performance of the newly created materials (e.g., power density in a fuel cell).
- Analysis & Planning: The multimodal data (images, spectra, performance metrics) are fed back into the active learning models. These models, augmented with literature knowledge and human feedback, then plan the next set of experiments to optimize the target property.
Mobile Robot Workflow for Exploratory Chemistry
This platform's protocol is defined by its modularity and reliance on orthogonal analytical techniques [14].
- Synthesis: An automated synthesis platform (Chemspeed ISynth) performs parallel chemical reactions.
- Sample Reformating & Transport: The synthesizer prepares aliquots of the reaction mixtures in standard consumables for UPLC-MS and NMR analysis. A mobile robot with a specialized gripper picks up and transports these samples to the respective instruments.
- Orthogonal Characterization: The samples are analyzed by UPLC-MS and benchtop NMR spectroscopy. The UPLC-MS provides data on molecular weight and purity, while the NMR spectrometer provides structural information.
- Heuristic Decision-Making: A rule-based algorithm, defined by a domain expert, processes the data from both techniques. It gives a binary "pass/fail" grade for each analysis. Reactions must typically pass both analyses to be selected for the next step, such as scale-up or further elaboration. This decision is made autonomously and near-instantaneously.
Diagram 1: Orthogonal Characterization Workflow in the Mobile Robot Platform. Sample aliquots undergo independent UPLC-MS and NMR analysis. A heuristic decision-maker integrates both data streams to autonomously determine the subsequent experimental path.
Performance and Experimental Outcomes
Quantitative data from published studies demonstrate the performance and real-world impact of both platforms.
Table 2: Quantitative Performance and Experimental Outcomes
| Metric | CRESt Platform | Mobile Robot Platform |
|---|---|---|
| Reported Experiment Scale | Explored >900 chemistries, conducted 3,500 electrochemical tests over 3 months [36] | Capable of performing parallel syntheses and autonomous multi-step reactions [14] |
| Key Discovery | A catalyst material with 8 elements, achieving a 9.3-fold improvement in power density per dollar over pure palladium, and a record power density in a direct formate fuel cell [36] | Successful application in structural diversification chemistry, supramolecular host-guest chemistry, and photochemical synthesis, making human-like decisions on reaction progression [14] [37] |
| Decision-Making Speed | AI continuously plans new experiments based on multimodal feedback [36] | Autonomous decision on reaction progression is "basically instantaneous" (vs. hours for a human chemist) [37] |
| Characterization Orthogonality | Relies on multimodal data fusion (literature, imaging, composition, performance) [36] | Relies on two orthogonal techniques (UPLC-MS & NMR) for binary decision-making, mimicking human verification protocols [14] |
The Scientist's Toolkit: Essential Research Reagents and Materials
The following table details key reagents and materials used in the experiments conducted by the featured platforms, highlighting their function in the research.
Table 3: Key Research Reagents and Materials in Featured Experiments
| Item | Function in Research |
|---|---|
| Palladium (Pd) | A precious metal used as a baseline catalyst in fuel cell research. The CRESt platform's goal was to find a multi-element catalyst that reduces or replaces its use [36]. |
| Formate Salt | Used as a fuel in the direct formate fuel cells for which CRESt discovered a new catalyst [36]. |
| Alkyne Amines & Isothiocyanates/Isocyanates | Building block molecules used in the mobile robot platform's parallel synthesis of ureas and thioureas, which are relevant to drug discovery [14]. |
| Supramolecular Building Blocks | Chemical precursors designed to self-assemble into larger host-guest structures, a key test case for the mobile robot platform's exploratory capabilities [14]. |
| UPLC-MS Consumables | Columns, solvents, and vials essential for the operation of the Ultra-Performance Liquid Chromatography-Mass Spectrometer used for reaction monitoring [14]. |
| NMR Tubes and Deuterated Solvents | Essential consumables for preparing samples for analysis in the benchtop Nuclear Magnetic Resonance spectrometer [14]. |
This comparison reveals two powerful but distinct paradigms for autonomous research. The CRESt platform demonstrates the power of a deeply integrated, AI-driven system that leverages massive multimodal data fusion—from literature to real-time imaging—to drive discovery in materials science. In contrast, the mobile robot platform excels through physical and analytical flexibility, using mobile manipulators to create agile workflows that leverage orthogonal characterization (UPLC-MS and NMR) for decision-making in exploratory chemistry. Both platforms successfully implement closed-loop operations, yet they serve as exemplary models for different research environments: CRESt for high-throughput, data-intensive materials optimization, and the mobile robot platform for flexible, discovery-oriented chemical synthesis where sharing equipment and verifying results with multiple techniques is paramount.
The integration of Large Language Models (LLMs) as central orchestrators in multi-agent systems (MAS) represents a paradigm shift in how complex tasks are automated, particularly in research domains requiring high reliability and comprehensive characterization. This architecture moves beyond single-agent models by creating a collaborative network where a master LLM agent, functioning as a "brain," decomposes problems, assigns subtasks to specialized agents, and synthesizes their outputs into a final result [38] [39]. The core strength of this approach lies in its embodiment of orthogonal characterization—a principle borrowed from rigorous scientific fields like gene and cell therapy quality control, which employs multiple, independent methods to assess a single quality attribute, thereby eliminating false positives/negatives and ensuring comprehensive analysis [27]. In the context of autonomous workflows, this translates to using diverse, specialized AI agents to cross-validate results and tackle complex problems from multiple, independent angles, significantly enhancing the robustness and reliability of the outcomes.
This guide objectively evaluates the performance of the LLM-as-orchestrator architecture against alternative AI agent frameworks. It provides detailed experimental data and methodologies, contextualized specifically for the needs of researchers, scientists, and drug development professionals engaged in developing and validating autonomous research systems.
Performance Comparison: Single-Agent vs. Multi-Agent vs. LLM-Orchestrated Multi-Agent Systems
Quantitative data from recent studies demonstrates the clear advantages of a coordinated multi-agent approach. The table below summarizes key performance metrics across different architectural paradigms.
Table 1: Performance Comparison of AI Agent Architectures
| Metric | Single-Agent LLM | Basic Multi-Agent System | LLM-Orchestrated Multi-Agent System |
|---|---|---|---|
| Task Success Rate | 45–60% [39] | Not Explicitly Quantified | 85–95% [39] |
| Hallucination Rate | 15–25% [39] | Not Explicitly Quantified | 3–8% [39] |
| Complex Problem-Solving | Limited [39] | Good | Excellent [39] |
| Domain Expertise | Generalized [39] | Specialized | Specialized & Integrated [38] |
| Handling Extended Context | Limited by context window [40] | Segmented context per agent | Combined context comprehension [39] |
| Error Recovery | Poor [39] | Moderate | Good [39] |
The data reveals that the LLM-orchestrated system significantly outperforms single-agent models on critical metrics like success rate and hallucination reduction. This is largely because a single LLM acts as a "jack of all trades, master of none," whereas a multi-agent system allows for strategic specialization [39]. For example, in a legal document analysis task, a single GPT-4 agent achieved 63% accuracy, while a multi-agent system utilizing specialized models for contract law, jurisdiction, precedent research, and risk analysis achieved 89% accuracy [39].
Furthermore, the orchestrator model effectively solves the context window problem. While a single agent might be limited to 128k tokens, a multi-agent system can effectively comprehend 200k tokens or more by distributing context segments across different agents, each focusing on a specific portion of the information [39].
Table 2: Specialized Agent Roles in a Drug Discovery Workflow
| Agent Role | Core Function | Suggested LLM Specialization |
|---|---|---|
| Research Aggregator | Compiles and summarizes relevant scientific literature. | GPT-4 or Claude Sonnet |
| Hypothesis Generator | Proposes novel, testable research hypotheses based on current data. | Claude Opus |
| Protocol Designer | Designs detailed experimental methodologies. | GPT-4 with RAG on protocols |
| Data Analyst | Processes and interprets complex experimental results (e.g., spectral data). | Custom fine-tuned model |
| Compliance Auditor | Ensures proposed workflows adhere to regulatory standards. | Domain-specialized model |
Experimental Protocols for Evaluating Orthogonal Coordination
To quantitatively evaluate the efficacy of an LLM-orchestrated multi-agent system in a research setting, the following experimental protocol, inspired by real-world autonomous laboratory setups, can be employed.
Protocol: Autonomous Exploratory Synthesis and Analysis
This protocol is adapted from modular robotic workflows used in advanced synthetic chemistry [2]. It tests the system's ability to manage a complex, multi-step process involving physical hardware and data analysis.
Objective: To autonomously execute a multi-step chemical synthesis, analyze the results using orthogonal techniques (UPLC-MS and NMR), and make decisions about subsequent experimental steps based on a heuristic analysis of the combined data.
Experimental Setup & Workflow:
- Agents: 1 Orchestrator Agent, 1 Synthesis Control Agent, 1 MS Data Analysis Agent, 1 NMR Data Analysis Agent.
- Hardware Modules: An automated synthesis platform (e.g., Chemspeed ISynth), a UPLC-MS, a benchtop NMR spectrometer, and mobile robots for sample transport [2].
- Workflow: The process is cyclical, involving synthesis, orthogonal analysis, heuristic decision-making, and subsequent synthesis, as detailed in the diagram below.
Methodology Details:
- Task Decomposition: The Orchestrator Agent receives a high-level goal (e.g., "Perform a divergent synthesis of library compounds A, B, and C"). It decomposes this into specific synthesis operations for the automated platform [2].
- Synthesis & Orthogonal Analysis: The Synthesis Control Agent executes the reactions. Upon completion, mobile robots transport aliquots to the UPLC-MS and NMR instruments. The MS and NMR Data Analysis agents independently process their respective data streams, providing binary "pass/fail" grades based on experiment-specific criteria defined by a domain expert [2].
- Heuristic Decision-Making: A rule-based decision-maker integrates the two orthogonal analyses. In the cited study, a reaction had to pass both UPLC-MS and NMR analyses to proceed to the next step (e.g., scale-up). This mimics human protocols and ensures robust, cross-validated decision-making [2].
- Evaluation Metrics: The system's performance is measured by its task completion rate, the reproducibility of successful reactions, and the novelty and validity of the synthesized compounds as confirmed by orthogonal techniques.
Key Findings from Experimental Implementation
Implementation of this protocol demonstrated that the LLM-orchestrated, multi-agent workflow could successfully emulate end-to-end human-driven processes without intermediate intervention [2]. The use of orthogonal analytical techniques (UPLC-MS and NMR) was critical, as it allowed the system to capture the diversity inherent in exploratory synthesis, where some products might yield complex NMR spectra but simple mass spectra, and vice versa [2]. The "loose" heuristic decision-maker, while rule-based, remained open to novelty, allowing for genuine chemical discovery rather than just the optimization of a single, pre-defined metric.
Architectural Frameworks for Multi-Agent Coordination
The "brain" of the system can coordinate its agents through different architectural patterns, each with distinct advantages and trade-offs. The following diagram illustrates three primary coordination models.
Table 3: Comparison of Multi-Agent Coordination Architectures
| Architecture | Key Features | Strengths | Weaknesses | Best Use Cases |
|---|---|---|---|---|
| Hierarchical [41] | Centralized control, clear accountability, top-down task delegation. | High task efficiency, streamlined sequential workflows. | Single point of failure, potential bottlenecks at the orchestrator. | Workflow automation, document generation, structured R&D processes. |
| Peer-to-Peer [41] | Decentralized decisions, distributed collaboration, agents act as equals. | Dynamic problem-solving, parallel processing, fosters innovation. | Can suffer from coordination challenges and slower consensus-building. | Brainstorming, interdisciplinary problem-solving. |
| Hybrid [41] | Dynamic leadership, combines hierarchy and collaboration. | Highly versatile and adaptable to varying task requirements. | More complex to manage and balance; resource-intensive. | Strategic planning, projects with both structured and creative phases. |
Frameworks like AutoGen [40] [42], CrewAI [40] and LangGraph [40] [41] provide the necessary infrastructure to implement these coordination patterns, handling conversation orchestration, state management, and tool integration.
The Scientist's Toolkit: Essential Research Reagent Solutions
Building and operating a robust, multi-agent system for autonomous research requires a suite of software and hardware "reagents." The following table details key components and their functions.
Table 4: Essential Toolkit for Multi-Agent Autonomous Research Systems
| Tool / Solution | Category | Function in the Workflow |
|---|---|---|
| AutoGen [40] [42] | Agent Framework | Enables the creation of conversable AI agents that can collaborate, use tools, and involve humans in the loop. |
| LangGraph [40] [41] | Agent Framework | Specializes in building stateful, multi-actor applications with cyclical workflows, crucial for complex agent runtimes. |
| CrewAI [40] | Agent Framework | A Python-based framework focused on role-based collaboration, ideal for assembling crews of specialized agents. |
| UPLC-MS [2] | Analytical Hardware | Provides ultra-high-performance liquid chromatography and mass spectrometry data for analyzing reaction products. |
| Benchtop NMR [2] | Analytical Hardware | Provides nuclear magnetic resonance data for structural analysis of synthesized molecules. |
| Automated Synthesis Platform (e.g., Chemspeed ISynth) [2] | Laboratory Hardware | Executes chemical synthesis autonomously in a standardized and reproducible manner. |
| Mobile Robots [2] | Laboratory Hardware | Provide physical connectivity between modular stations (synthesis, analysis) in a flexible laboratory setup. |
| Heuristic Decision-Maker [2] | Software Logic | Applies expert-defined rules to integrate orthogonal data streams and autonomously decide on subsequent workflow steps. |
The accelerating complexity of biologic therapeutics, from multi-specific antibodies to sophisticated viral vectors, demands equally advanced analytical methods. Orthogonal characterization—the use of multiple independent techniques to analyze product attributes—has become indispensable for comprehensive profiling. Within the context of autonomous workflows, robust orthogonal methods provide the high-quality, multi-parameter data essential for training and validating artificial intelligence (AI) and machine learning (ML) models. These models, in turn, drive experimental planning and optimization in self-driving laboratories, creating a closed-loop cycle of discovery and development. This guide objectively compares the performance of cutting-edge technologies and platforms that are enhancing the profiling of therapeutic antibodies and viral vectors, thereby fueling the evolution of fully autonomous research environments.
Technology Performance Comparison
To select the appropriate profiling technology, researchers must consider the specific application—be it for antibody discovery or viral vector characterization. The following tables provide a comparative overview of leading platforms.
Table 1: Performance Comparison of High-Throughput Antibody Profiling Technologies
| Technology Platform | Key Measured Parameters | Throughput Capacity | Reported Cost Reduction | Key Advantages |
|---|---|---|---|---|
| oPool+ Display [43] | Binding specificity & cross-reactivity against antigen variants | 100s - 1,000s of antibody-antigen interactions in days | 80-90% reduction in materials and supplies [43] | Rapid candidate identification; ideal for AI model validation |
| AI/ML-Driven In Silico Design [44] [45] | Predicted antibody structure, affinity, stability, and immunogenicity | 1,000s of novel sequences generated in silico | Dramatically reduced timelines and failure rates [44] | Accelerates discovery from concept to trials; enables de novo design |
| Nanobody Platforms [44] | Tissue penetration, stability, binding to challenging epitopes | Varies by discovery method (e.g., phage display) | Cost-effective production in microbial systems [44] | Superior tissue penetration; access to unique epitopes; high stability |
Table 2: Performance Comparison of Viral Vector Characterization Platforms
| Vector Platform | Immunogenicity Profile | Cargo Capacity | Primary Challenges | Suitability for Autonomous Workflows |
|---|---|---|---|---|
| Adenovirus (e.g., ChAdOx1, Ad26) [46] | Potent T-cell and B-cell responses | ~8 kb [46] | Pre-existing immunity; rare safety signals (e.g., VITT) [46] | Established industrial processes and scalability facilitate automation |
| Lentivirus [46] | Sustained antigen expression, potent T-cell induction | ~8 kb [46] | More complex manufacturing & safety considerations [46] | Attractive for therapeutic vaccine concepts requiring persistent expression |
| Adeno-Associated Virus (AAV) [46] | Favors humoral responses, good safety profile | ~4.5 kb [46] | Pre-existing immunity; limited cargo capacity [46] | Relatively stable gene expression simplifies quality control parameters |
| Modified Vaccinia Ankara (MVA) [46] | Strong immunogenicity, large antigen payloads | Large capacity for transgenes [46] | Complex vector biology [46] | Proven track record in large populations, providing vast historical data |
Detailed Experimental Protocols and Methodologies
Protocol for High-Throughput Antibody Profiling using oPool+ Display
The oPool+ display platform combines high-volume synthesis with a binding analysis array to characterize thousands of antibody-antigen interactions in parallel [43].
Methodology:
- Library Construction: A library of antibody genes (e.g., ~300 native pairings from different donors) is cloned into a specialized expression vector.
- High-Throughput Synthesis: The vector library is used in a cell-free or microbial system to synthesize hundreds of antibody proteins simultaneously.
- Binding Analysis Array: The synthesized antibodies are systematically exposed to an array of different antigen variants (e.g., hemagglutinin from various influenza strains) immobilized on a solid surface.
- Characterization and Data Acquisition: Binding events are detected using high-throughput methods (e.g., fluorescence). The resulting data builds a specificity profile for each antibody, identifying the best candidates for further development and revealing common binding features across individuals [43].
Protocol for Orthogonal Characterization of Viral Vectors
A robust characterization protocol for viral vectors must assess multiple critical quality attributes (CQAs) to ensure safety and efficacy.
Methodology:
- Vector Titer and Potency:
- Physical Titer: Digital PCR (dPCR) is used to quantify vector genome copies (vg/mL). This technique offers high precision and absolute quantification without a standard curve.
- Functional Titer: In vitro transduction assays on permissive cell lines are performed, followed by flow cytometry or quantitative PCR to measure transgene expression or genome replication, respectively. This measures infectious units (IU/mL).
- Identity and Purity:
- Capsid Integrity: Analytical ultracentrifugation (AUC) separates empty capsids from full capsids containing the genetic payload based on their differential sedimentation rates.
- Residual Impurities: Enzyme-Linked Immunosorbent Assay (ELISA) is used to quantify host cell proteins and DNA from the production system.
- Safety and Immunogenicity Profile:
- In vivo studies in animal models are conducted to monitor for adverse events, such as Vaccine-Induced Immune Thrombotic Thrombocytopenia (VITT), which has been associated with certain adenovirus vectors [46].
The Scientist's Toolkit: Essential Research Reagents
Successful profiling relies on a suite of specialized reagents and tools.
Table 3: Key Research Reagent Solutions for Profiling
| Reagent / Tool | Function in Profiling Workflow |
|---|---|
| Immobilized Antigen Arrays | Serves as the binding target for high-throughput screening of antibody specificity and cross-reactivity [43]. |
| Cell-Based Transduction Assays | Provides a biologically relevant system for measuring the functional titer and potency of viral vectors. |
| dPCR Kits | Enables precise and absolute quantification of viral vector genome copies, a key metric for dosing and quality control. |
| Anti-AAV Neutralizing Antibody Assay | Quantifies pre-existing immunity to AAV serotypes, a critical factor for patient stratification and vector selection [46]. |
| Capsid-Specific Antibodies | Allows for the immunodetection and quantification of viral capsid proteins in assays like ELISA and Western Blot. |
Visualizing Autonomous Characterization Workflows
The integration of these profiling technologies into autonomous laboratories creates a powerful, closed-loop system for biologic development.
Diagram 1: Closed-loop autonomous workflow for biologic therapeutic development. The AI model uses the initial target profile to design candidates, which are synthesized robotically. Orthogonal characterization generates multi-parameter data that feeds back to the AI for analysis and the next cycle of design, creating an iterative optimization loop [44] [28] [43].
The interplay between different analytical techniques is crucial for obtaining a comprehensive understanding of a viral vector's properties.
Diagram 2: Orthogonal characterization of viral vectors. A single viral vector sample is analyzed in parallel by three independent method classes to assess its critical quality attributes. The data from titer, purity, and safety assays are combined to generate a comprehensive quality report [46].
The technologies profiled here, from the high-throughput oPool+ display for antibodies to the suite of orthogonal assays for viral vectors, are more than just incremental improvements. They are foundational components for building the autonomous laboratories of the future. By generating robust, multi-faceted data at unprecedented speed and scale, these platforms provide the fuel for AI-driven discovery and optimization cycles. As these tools continue to evolve and become more integrated, they promise to significantly accelerate the development of next-generation biologics, ultimately bringing safer and more effective treatments to patients faster.
Navigating Challenges: Data, Generalization, and Hardware Constraints
Conquering Data Scarcity and Noise with High-Quality Training Sets
In modern drug development and scientific research, autonomous workflows are transforming how discoveries are made. These self-driving laboratories rely on artificial intelligence (AI) and robotic systems to execute experiments with minimal human intervention. However, their performance is fundamentally constrained by two interconnected challenges: data scarcity and data noise. Data scarcity refers to the insufficient availability of high-quality, relevant training data, which hinders the development of effective AI models and reduces their predictive performance [47]. Simultaneously, data noise—inaccuracies and artifacts introduced during data collection and processing—can compromise the reliability of experimental outcomes and lead to erroneous conclusions.
The concept of orthogonal characterization has emerged as a powerful strategy to address these challenges. This approach utilizes multiple, independent measurement techniques to analyze the same experimental samples, creating robust and verifiable datasets. By cross-validating results across different analytical modalities, researchers can distinguish true signals from noise and build more trustworthy training sets for AI systems [14]. This article evaluates current methodologies for combating data scarcity and noise, with particular focus on how orthogonal characterization enhances data quality within autonomous workflows essential for researchers and drug development professionals.
Quantitative Comparison of Data Enhancement Techniques
Various approaches have been developed to address data quality challenges, each with distinct strengths and implementation requirements. The table below summarizes the performance characteristics of three primary categories of solutions: synthetic data generation, noise reduction algorithms, and orthogonal validation systems.
Table 1: Performance Comparison of Data Enhancement Techniques
| Technique | Primary Application | Key Performance Metrics | Reported Effectiveness | Implementation Complexity |
|---|---|---|---|---|
| Synthetic Data Generation [48] | Data scarcity across multiple domains | Diversity, Realism, Privacy preservation | Reduces data collection costs; Improves model robustness on rare cases | Moderate to High |
| Deep Learning Noise Reduction [49] | Medical imaging (Magnetic Particle Imaging) | Signal-to-Noise Ratio (SNR), Structural Similarity Index | 12 dB SNR improvement; PSNR: 29.11 dB; SSIM: 0.93 | High |
| Generative Fixed-Filter ANC [50] | Active noise control in physical systems | Noise reduction depth, Convergence speed | Outperforms FxLMS and commercial ANC algorithms | Moderate |
| Orthogonal Characterization [14] | Chemical discovery workflows | Reproducibility rate, Hit identification accuracy | Enabled 71% success rate in autonomous material synthesis | High |
Orthogonal Characterization Workflows in Practice
The implementation of orthogonal characterization in autonomous laboratories has demonstrated substantial improvements in experimental reliability. In modular robotic systems for exploratory synthetic chemistry, the combination of UPLC-MS and benchtop NMR provides independent verification of reaction outcomes [14]. This approach mirrors human expert decision-making by requiring reactions to "pass" both analytical assessments before proceeding to subsequent stages, effectively reducing false positives in screening processes.
In materials science, the A-Lab platform successfully synthesized 41 of 58 target materials by employing orthogonal characterization techniques, including X-ray diffraction (XRD) analysis paired with AI-driven phase identification [28]. This integration of multiple characterization modalities achieved a 71% success rate in autonomous material discovery, demonstrating how orthogonal validation enhances the reliability of closed-loop research systems.
Experimental Protocols for Data Quality Enhancement
Deep Learning-Based Noise Reduction in Medical Imaging
Objective: To suppress noise in system matrix measurements for Magnetic Particle Imaging (MPI), thereby enhancing image quality for diagnostic applications [49].
Methodology:
- Network Architecture: A hybrid encoder-decoder network integrating residual blocks (Res-Blocks) and swin transformer modules enables multi-scale feature extraction
- Training Data: The model was trained on simulated datasets, OpenMPI datasets, and data from in-house MPI systems
- Noise Disentanglement: The implementation employs multi-scale feature extraction to separate noise from valid signals, coupled with cross-level feature fusion to optimize frequency-domain recovery
- Validation: Performance was quantified using signal-to-noise ratio (SNR), peak signal-to-noise ratio (PSNR), and structural similarity index (SSIM) metrics
Key Implementation Detail: The hybrid approach allows the model to capture both local image features (via Res-Blocks) and global contextual relationships (via swin transformers), enabling comprehensive noise suppression while preserving critical diagnostic information.
Autonomous Workflows with Orthogonal Characterization
Objective: To enable reliable autonomous decision-making in exploratory synthetic chemistry through multi-modal analytical verification [14].
Methodology:
- Analytical Integration: A Chemspeed ISynth synthesizer is connected to UPLC-MS and benchtop NMR spectrometers via mobile robotic sample transport
- Sample Processing: Post-reaction, the system reformats aliquots separately for MS and NMR analysis
- Decision Algorithm: A heuristic decision-maker applies binary pass/fail grading to both MS and NMR results using:
- Dynamic time warping to detect reaction-induced spectral changes in NMR data
- Precomputed m/z lookup tables for MS verification
- Workflow Progression: Only reactions passing both analytical assessments proceed to scale-up or further experimentation
Key Implementation Detail: The physical separation of analytical instruments connected by mobile robots allows sharing of expensive equipment with human researchers, providing a scalable model for laboratory automation without requiring complete facility redesign.
The Scientist's Toolkit: Essential Research Reagent Solutions
Implementing robust data quality systems requires specific technical components. The table below details essential solutions for establishing orthogonal characterization capabilities in autonomous research environments.
Table 2: Research Reagent Solutions for Orthogonal Characterization Workflows
| Solution Component | Function | Application Context |
|---|---|---|
| UPLC-MS System [14] | Provides separation and mass analysis for molecular identification | Synthetic chemistry, drug metabolism studies |
| Benchtop NMR Spectrometer [14] | Delivers structural information through nuclear magnetic resonance | Reaction verification, compound characterization |
| Mobile Robotic Sample Transport [14] | Enables physical connection between modular instruments | Autonomous laboratories, shared equipment facilities |
| Heuristic Decision-Maker [14] | Processes orthogonal data streams to determine subsequent experimental steps | Autonomous workflow orchestration |
| Hybrid Encoder-Decoder Network [49] | Implements deep learning-based noise reduction | Medical imaging, analytical signal processing |
| Convolutional Neural Networks (CNNs) [50] | Generates appropriate control filters for varying noise types | Active noise control systems, signal processing |
| Synthetic Data Platforms [48] | Generates artificial datasets to augment limited experimental data | Drug discovery, rare disease research, privacy-sensitive contexts |
Workflow Visualization of Orthogonal Characterization Systems
Autonomous Chemistry Workflow with Orthogonal Characterization
Autonomous Chemistry Workflow with Orthogonal Characterization
Deep Learning Noise Reduction System
Deep Learning Noise Reduction System
The integration of orthogonal characterization methodologies represents a paradigm shift in how researchers approach data quality in autonomous workflows. By combining multiple, independent analytical techniques with advanced noise reduction algorithms and strategic synthetic data supplementation, scientific teams can significantly enhance the reliability of their training datasets. The experimental protocols and performance metrics detailed in this guide demonstrate that while no single solution completely eliminates data challenges, a systematic approach to data quality management yields substantial dividends in research efficiency and outcome validity.
For drug development professionals and research scientists, the implementation of these data quality frameworks requires careful consideration of domain-specific requirements. However, the underlying principles of verification through orthogonal measurement, noise-aware data processing, and judicious use of synthetic data augmentation provide a robust foundation for autonomous discovery systems. As these methodologies continue to mature, they promise to accelerate scientific innovation by ensuring that AI-driven research platforms operate on the highest-quality information possible.
Mitigating Model Hallucination and Overconfidence in LLM-Driven Systems
In autonomous workflows for drug development and exploratory science, the reliability of Large Language Models (LLMs) is paramount. Model hallucinations—factually incorrect or unfaithful generations—coupled with persistent overconfidence present significant risks in high-stakes research environments where errors can invalidate experiments or misdirect scientific programs. Recent research has reframed hallucinations not merely as technical artifacts but as a systemic incentive problem, where training objectives and evaluation metrics reward confident guessing over calibrated uncertainty [51]. This article examines the current landscape of hallucination and overconfidence mitigation, providing a comparative analysis of approaches relevant to researchers building trustworthy autonomous scientific systems.
The core challenge lies in the fact that LLMs frequently overestimate the probability that their answers are correct, with studies documenting this overconfidence bias ranging between 20% and 60% [52]. This phenomenon is particularly dangerous in autonomous workflows, where models must accurately signal uncertainty about experimental outcomes or chemical predictions rather than presenting fabricated results with undue confidence. Understanding and mitigating these limitations is foundational to implementing robust orthogonal characterization in autonomous research platforms.
Understanding the Problem Space: From Factual Errors to Systemic Overconfidence
Defining Hallucinations and Overconfidence
In the context of LLM-driven scientific systems, hallucinations manifest primarily as two distinct but related failure modes:
Knowledge-based Hallucinations: The model generates factually incorrect information not supported by external knowledge sources or training data. Examples include inventing non-existent chemical properties, misattributing biological pathways, or fabricating research findings [53] [54].
Logic-based Hallucinations: The model produces logically inconsistent reasoning chains, misrepresents source materials, or demonstrates broken causal reasoning despite having access to correct factual information [53].
Compounding both hallucination types is the problem of model overconfidence, where LLMs assign high confidence scores to incorrect responses. Recent research examining this phenomenon through a behavioral lens has found that larger models tend to overestimate their performance on challenging tasks and underestimate it on simpler ones, mirroring certain human cognitive bias patterns [55].
Root Causes in Autonomous Workflow Applications
The persistence of hallucinations and overconfidence in LLMs stems from interconnected factors particularly relevant to scientific applications:
Incentive Misalignment: Next-token training objectives and common leaderboards reward confident guessing over calibrated uncertainty, essentially teaching models to "bluff" when uncertain [51].
Architectural Limitations: The autoregressive nature of LLMs creates exposure bias, where small early errors can snowball throughout generation [51].
Data Biases: Training corpora inevitably contain outdated, incomplete, or false scientific information that models may reproduce [54].
Evaluation Gaps: Current benchmarks often penalize abstention ("I don't know") and favor detailed, confident-sounding responses in human feedback cycles [51].
Comparative Analysis of Mitigation Approaches
Performance Comparison of Hallucination Mitigation Techniques
Table 1: Comparative effectiveness of major hallucination mitigation approaches based on 2024-2025 research
| Mitigation Approach | Mechanism | Reported Effectiveness | Limitations | Best-Suited Applications |
|---|---|---|---|---|
| Retrieval-Augmented Generation (RAG) with Verification | Grounds generation in external knowledge sources with span-level fact checking | Reduces knowledge hallucinations by 47-53% in controlled studies [51] | Limited by retrieval quality; requires current, accurate knowledge bases | Scientific literature analysis, experimental protocol generation |
| Uncertainty-Calibrated Fine-Tuning | Trains models to recognize and express uncertainty using specialized datasets | Cuts hallucination rates by 90-96% on hard examples without hurting quality [51] | Requires significant computational resources and curated datasets | Domain-specific scientific assistants |
| Reward Models for Calibrated Uncertainty | Integrates confidence calibration into reinforcement learning to penalize over/underconfidence | Improves confidence calibration by 25-40% across task difficulty levels [51] | Complex implementation; may reduce response specificity | Autonomous experimental decision-making |
| Answer-Free Confidence Estimation (AFCE) | Decouples confidence estimation from answer generation by evaluating question sets without answers | Significantly reduces overconfidence, particularly on challenging tasks [55] | Provides confidence scores without actionable alternatives | Pre-experimental risk assessment |
| Factuality-Based Reranking | Generates multiple candidate responses then selects the most factual using lightweight metrics | Significantly lowers error rates without model retraining [51] | Increases computational overhead during inference | Research paper summarization, documentation |
| Emotion-Augmented Inference (EAI) | Uses visual-contrastive decoding and affective textual symbolization to enhance coherence | Improves accuracy by 4-8% in multimodal tasks; most effective in negative emotional contexts [56] | Novel approach with limited real-world testing | Multimodal data interpretation |
Overconfidence Mitigation Performance Across Model Scales
Table 2: Overconfidence patterns and mitigation effectiveness across model sizes
| Model Scale | Overconfidence Pattern | Impact of Mitigation Strategies | Recommended Approaches |
|---|---|---|---|
| Small Models (<7B parameters) | Consistent overconfidence across all task difficulty levels [55] | Limited responsiveness to calibration techniques; require architectural changes | RAG systems, external verification layers |
| Medium Models (7B-70B parameters) | Moderate overconfidence, more pronounced on difficult tasks | Good responsiveness to fine-tuning and reward modeling | Uncertainty-aware RLHF, targeted fine-tuning |
| Large Models (>70B parameters) | Human-like pattern: overestimation on hard tasks, underestimation on easy tasks [55] | Strongest responsiveness to calibration techniques; mirror human bias patterns | AFCE, confidence-estimation decoupling, reasoning tracking |
Experimental Protocols for Hallucination Assessment
Protocol 1: Retrieval-Augmented Generation with Span-Level Verification
Purpose: To evaluate and improve the factual accuracy of LLM-generated scientific content by grounding responses in verified external knowledge.
Materials:
- LLM system with retrieval capability
- Domain-specific knowledge bases (e.g., PubMed, proprietary chemical databases)
- Verification dataset with known ground truths
- Span-level annotation tools
Methodology:
- Query Processing: Receive scientific query and retrieve relevant documents from knowledge bases
- Context Integration: Process retrieved documents into model context window
- Response Generation: Generate answer based on retrieved context
- Span-Level Verification:
- Extract each factual claim from generated response
- Match claims against retrieved evidence sources
- Flag unsupported claims with confidence scores
- Response Refinement: Revise or qualify responses based on verification results
Evaluation Metrics:
- Faithfulness percentage (supported claims/total claims)
- Citation recall and precision
- Factual accuracy against ground truth
Recent implementations in legal and medical domains have demonstrated that adding span-level verification to RAG pipelines can identify and correct approximately 30% of factual errors that would otherwise go undetected with simple retrieval [51].
Protocol 2: Answer-Free Confidence Estimation (AFCE)
Purpose: To decouple confidence estimation from answer generation, reducing overconfidence particularly on challenging scientific tasks.
Materials:
- LLM with confidence estimation capability
- Question sets with known difficulty calibration
- Confidence scoring infrastructure
Methodology:
- Question Categorization: Classify questions by anticipated difficulty level using established benchmarks
- Confidence-Only Assessment: Present questions to model without answer generation, requesting confidence scores (0-100%) in correctness
- Actual Performance Measurement: Administer same questions under standard answering conditions
- Calibration Analysis: Compare confidence scores to actual performance across difficulty levels
- Bias Pattern Identification: Document overconfidence/underconfidence patterns by question type and difficulty
Evaluation Metrics:
- Calibration error (confidence minus accuracy)
- Overconfidence magnitude by task difficulty
- Correlation between confidence and actual performance
Preliminary studies using AFCE have demonstrated "significant reductions in overconfidence, particularly on challenging tasks" by preventing the cognitive entanglement between answer generation and confidence assessment [55].
Visualization of Mitigation Frameworks
Orthogonal Characterization Workflow for Autonomous Science
Orthogonal Characterization Workflow: This framework illustrates the integration of multiple verification mechanisms that operate independently (orthogonally) to detect and mitigate different types of errors, inspired by modular autonomous research platforms [2].
Hallucination Detection and Mitigation Pathways
Hallucination Detection Pathways: This diagram maps detection methods to specific hallucination types and connects them to appropriate mitigation strategies, highlighting the orthogonal relationship between different verification approaches.
Table 3: Research Reagent Solutions for Hallucination Mitigation Implementation
| Tool/Resource | Function | Implementation Role | Relevance to Autonomous Science |
|---|---|---|---|
| Mu-SHROOM Benchmark | Evaluates multilingual hallucinations in diverse contexts [51] | Baseline performance assessment | Critical for global research collaboration systems |
| CCHall Benchmark | Measures multimodal reasoning hallucinations [51] | Cross-modal capability validation | Essential for systems integrating textual and visual scientific data |
| RAGAS Framework | Specialized metrics for RAG systems including context recall and faithfulness [57] | Retrieval quality assurance | Ensures accurate grounding in scientific literature |
| LiveBench | Contamination-resistant benchmark with monthly updates [57] | Real-world performance tracking | Prevents benchmark gaming in continuous evaluation |
| MetaQA Framework | Uses metamorphic prompt mutations to detect hallucinations in closed-source models [51] | Black-box model assessment | Essential for evaluating proprietary models without internal access |
| GPQA-Diamond | Graduate-level expert questions requiring domain expertise [57] | Scientific reasoning evaluation | Tests genuine understanding beyond pattern recognition |
The mitigation of model hallucination and overconfidence represents a fundamental requirement for deploying LLMs in autonomous scientific workflows. As research advances, the focus has shifted from complete hallucination elimination to uncertainty calibration and transparent reliability signaling. The most effective implementations combine multiple orthogonal approaches—RAG with verification for knowledge-based errors, reasoning enhancement for logic-based errors, and confidence decoupling for overconfidence—tailored to specific scientific domains and use cases.
For drug development professionals and research scientists, the practical path forward involves implementing layered verification systems that make model uncertainty visible and actionable rather than seeking impossible perfection. This aligns with the emerging paradigm in autonomous laboratories where, similar to human researchers, AI systems must know when to express uncertainty, seek additional information, or defer to expert judgment [2]. As benchmark development continues to address real-world performance rather than leaderboard rankings, the integration of these mitigation strategies will become increasingly standardized in production scientific AI systems.
Overcoming Hardware Rigidity with Modular Platforms and Mobile Robotics
In the pursuit of scientific discovery, researchers in drug development and materials science are increasingly turning to autonomous laboratories to accelerate the design-make-test-analyze cycle. However, a significant bottleneck has emerged: hardware rigidity. Traditional automated systems often rely on bespoke, fixed equipment configurations that excel at optimizing for a single, predefined output but struggle with the exploratory and multi-faceted nature of cutting-edge research, particularly in fields like supramolecular chemistry or drug candidate screening [2]. This rigidity forces a compromise, where experiments are designed around available instrumentation rather than scientific need, potentially limiting the scope of discovery.
The core of the problem lies in the characterization of results. Exploratory synthesis often yields diverse outcomes, requiring multiple, orthogonal analytical techniques—such as mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy—for unambiguous identification [2]. When a workflow is "hard-wired" to a single characterization technique, the decision-making algorithms operate with a narrow data view, unlike the multifaceted approach a human researcher would employ. This paper evaluates the integration of modular robotics platforms and mobile robotics as a transformative solution, creating agile systems that can leverage a laboratory's full suite of instruments, thereby enabling truly intelligent and flexible autonomous research.
Modular & Mobile Platforms: Architecting Flexibility into the Lab
The solution to hardware rigidity is a shift from monolithic automation to distributed, modular architectures. This approach physically separates core functions—synthesis, analysis, and decision-making—and uses mobile robotic agents as the dynamic link between them [2]. This paradigm does not require a wholesale redesign of the laboratory; instead, it allows robots to share existing, often unmodified, equipment with human researchers.
Core Architectural Components
A successfully demonstrated modular workflow comprises several key components [2]:
- Synthesis Module: An automated synthesis platform (e.g., a Chemspeed ISynth) that prepares reaction mixtures and aliquots them for analysis.
- Orthogonal Analysis Modules: Standard, remotely located instruments such as a liquid chromatography–mass spectrometer (UPLC-MS) and a benchtop NMR spectrometer.
- Mobile Robots: Free-roaming robots responsible for transporting samples from the synthesizer to the various analytical instruments.
- Heuristic Decision-Maker: A software system that processes the multimodal data (UPLC-MS and NMR) from the completed experiments and makes autonomous decisions about the subsequent steps in the workflow, mimicking human reasoning.
A Comparative Look at Platform Strategies
The table below objectively compares the traditional, fixed automation approach with the emerging modular and mobile paradigm.
Table 1: Performance Comparison of Fixed Automation vs. Modular & Mobile Platforms
| Feature | Traditional Fixed Automation | Modular & Mobile Platforms |
|---|---|---|
| Characterization Basis | Typically relies on a single, hard-wired technique [2] | Utilizes orthogonal characterization (e.g., UPLC-MS & NMR) for robust analysis [2] |
| Infrastructure Cost & Flexibility | High; requires bespoke, integrated systems [2] | Lower; leverages existing lab equipment without major redesign [2] |
| Equipment Utilization | Instruments are monopolized by the automated line | Enables shared use of instruments between robots and human researchers [2] |
| Reconfigurability & Scalability | Low; changing workflows requires physical re-engineering | High; mobile robots can be reprogrammed, and new instruments can be added modularly [2] |
| Best-Suited Research | Optimization of a single, known output (e.g., catalyst yield) | Exploratory synthesis where multiple, unknown products are possible [2] |
Experimental Validation: Protocols and Data from an Autonomous Workflow
To quantitatively assess the performance of a modular approach, we can examine a landmark study that implemented this architecture for exploratory synthetic chemistry [2]. The following provides the detailed experimental protocol and the resulting data.
Detailed Experimental Protocol
The core methodology can be broken down into a cyclic workflow that integrates physical robotic actions with computational decision-making [2]:
- Autonomous Synthesis: The automated synthesizer executes a batch of programmed chemical reactions. Upon completion, it takes aliquots from each reaction mixture and reformats them into standard vials for MS and NMR analysis.
- Mobile Sample Transport: A mobile robot collects the prepared sample vials. It navigates the laboratory to transport NMR samples to the benchtop NMR spectrometer and MS samples to the UPLC-MS, operating each instrument's door via automated actuators.
- Orthogonal Data Acquisition: The analytical instruments run standardized methods to characterize the samples. The resulting data (chromatograms, mass spectra, and NMR spectra) are automatically saved to a central database.
- Heuristic Decision-Making: A custom algorithm processes the multimodal data. It applies experiment-specific, binary pass/fail criteria (defined by a domain expert) to the results from both the MS and NMR analyses. A reaction must typically pass both analyses to be selected for the next stage. This step also includes an automatic reproducibility check of any promising "hits" from the initial screen.
- Workflow Iteration: Based on the decision-maker's output, the system instructs the synthesizer on the next set of experiments, such as scaling up successful reactions or elaborating on promising precursor molecules, thus closing the autonomous loop.
This workflow is visualized in the following diagram, which outlines the logical relationships and data flow between the modules.
Supporting Performance Data
The efficacy of this modular approach was demonstrated across multiple chemistry domains, including structural diversification and supramolecular host-guest chemistry. The system's key achievement was its ability to successfully navigate complex reaction spaces and identify viable candidates based on robust, multi-technique characterization. The heuristic decision-maker allowed the platform to remain open to novel discoveries, a crucial feature for exploratory work that is not solely focused on maximizing a single, scalar output like yield [2].
Furthermore, the modular design principle extends to improving the hardware itself. Research into modular robot joint design has shown tangible benefits in core performance metrics. The table below summarizes experimental data from a study on a novel cantilever robot, highlighting the advantages of its modular, low-energy consumption architecture.
Table 2: Experimental Performance Data of a Modular Robot Design
| Performance Metric | Traditional Design | Novel Modular Design | Improvement |
|---|---|---|---|
| Pitch Joint Energy Consumption | Baseline | Reduced by 47.02% [58] | ~2x more efficient |
| Yaw Joint Workspace | Limited by interference points [58] | Significantly increased via single-motor dual-axis mechanism [58] | Enhanced flexibility |
| Structural Goal | Fixed, application-specific | Modular characteristics combined with low power consumption and large workspace [58] | Balanced performance |
The Researcher's Toolkit: Essential Components for Implementation
For research teams aiming to adopt this paradigm, a specific set of reagent solutions and hardware modules is essential. The following table details the key components based on the successfully implemented system [2].
Table 3: Research Reagent Solutions for a Modular Autonomous Workflow
| Item Name | Function in the Workflow |
|---|---|
| Automated Synthesis Platform | Executes liquid handling, mixing, and reaction incubation in a controlled, automated fashion. |
| Benchtop NMR Spectrometer | Provides orthogonal structural information about reaction products for heuristic analysis. |
| Liquid Chromatography–Mass Spectrometer | Provides orthogonal data on molecular weight and purity of reaction products. |
| Mobile Robotic Agents | Physically link discrete modules by transporting samples between synthesizers and analyzers. |
| Heuristic Decision-Making Software | Processes multimodal UPLC-MS and NMR data to autonomously determine subsequent experimental steps. |
The evidence from deployed systems confirms that modular platforms and mobile robotics effectively overcome the historical limitations of hardware rigidity. By enabling shared use of orthogonal analytical tools and introducing dynamic physical connectivity, this architecture brings the flexibility of human researcher behavior into the automated laboratory. The resulting systems are not only more efficient but also more capable of tackling the open-ended challenges of modern exploratory chemistry and drug development. As the market for modular robotics continues to grow, projected to reach USD 26.13 billion by 2030, and as AI decision-making becomes more sophisticated, this agile approach is poised to become the standard for the high-impact, discovery-driven research labs of the future [59] [60].
Building Robust Error Detection and Fault Recovery Mechanisms
In autonomous workflows, particularly within advanced fields like drug development and materials science, robust error detection and fault recovery are not merely beneficial—they are fundamental to operational viability. These "self-driving" systems integrate artificial intelligence (AI), robotic experimentation, and continuous data analysis into a closed-loop cycle, aiming to conduct scientific research with minimal human intervention [28]. The core challenge lies in their inherent complexity; unexpected failures in hardware, software, or AI model outputs can disrupt experiments, waste invaluable resources, and derail discovery timelines. Therefore, evaluating these systems requires an orthogonal characterization approach, where error resilience is not an afterthought but a primary, independent dimension of performance, assessed alongside traditional metrics like throughput and success rate.
This guide provides a comparative analysis of contemporary error-handling paradigms, from traditional rule-based methods to modern AI-driven and agentic systems. By presenting experimental data, detailed methodologies, and key research tools, we aim to equip researchers and scientists with the framework necessary to critically evaluate and implement fault-tolerant autonomous workflows in their own laboratories.
Comparative Analysis of Error Handling Paradigms
The landscape of fault tolerance can be divided into three main paradigms, each with distinct capabilities and limitations. The following table provides a high-level comparison of their core characteristics.
Table 1: Comparison of Error Handling and Fault Recovery Paradigms
| Characteristic | Traditional Rule-Based Methods | AI-Driven Recovery Systems | Agentic AI Frameworks |
|---|---|---|---|
| Core Principle | Predefined rules and static thresholds [61] | Machine learning for anomaly detection and pattern recognition [61] | LLM-powered agents that reason, plan, and act autonomously [62] |
| Error Detection Accuracy | Struggles with novel, unpredictable errors [61] | High accuracy (71.5% to 99%) in detecting complex anomalies [61] | Emerging capability; can reason about complex, novel failures [63] |
| Adaptability | Limited to scenarios envisioned by developers [61] | Learns and adapts to new error patterns over time [61] | High; can formulate new plans and use tools in response to failures [62] |
| Scalability | Requires manual configuration and more staff [61] | Scales automatically with minimal intervention [61] | Designed for complex, multi-step workflows across distributed systems [62] |
| Operational Efficiency | Slower, manual processes prone to human error [61] | Processes data instantly, reduces long-term operational costs [61] | Aims to fully automate complex tasks, but requires oversight for accuracy [62] |
| Best-Suited For | Simple, predictable environments with well-defined failure modes | Complex, multi-modal workflows with dynamic data and known anomaly types | Exploratory research and complex workflows requiring high-level reasoning |
Performance Benchmarking and Experimental Data
Theoretical comparisons must be grounded in empirical performance data. Benchmarking studies provide critical insights into how different systems behave under failure conditions.
Performance of Stream Processing Frameworks
A 2024 benchmarking analysis of cloud-native, open-source stream processing frameworks—critical for handling data flows in autonomous systems—evaluated their fault recovery performance using chaos engineering principles. The key metrics were recovery time (speed to regain normal performance) and stability (consistency of performance after recovery) [64].
Table 2: Benchmarking Fault Recovery in Stream Processing Frameworks (2024) [64]
| Framework | Fault Recovery Performance | Stability After Failure | Key Finding |
|---|---|---|---|
| Apache Flink | One of the best recovery times | Most stable | Recommended for applications requiring high stability and efficient recovery. |
| Kafka Streams | Performance instabilities post-recovery | Less stable | Current rebalancing strategy can be suboptimal for load balancing after a fault. |
| Spark Structured Streaming | Suitable recovery performance | Stable | Exhibits higher event latency compared to other frameworks. |
Efficacy of AI and Autonomous Systems
In the realm of AI-driven laboratories, performance is measured by success rates in real-world scientific tasks. The following table summarizes the documented performance of several pioneering systems.
Table 3: Performance of Autonomous and AI-Driven Research Systems
| System / Approach | Domain | Reported Performance / Efficacy | Source |
|---|---|---|---|
| A-Lab | Solid-state materials synthesis | Synthesized 41 of 58 target materials (71% success rate) over 17 days. | [28] |
| Coscientist | Organic chemistry | Successfully optimized palladium-catalyzed cross-coupling reactions. | [28] |
| AI-Driven Error Recovery | Multi-modal workflows | Error detection accuracy rates between 71.5% and 99%. | [61] |
| Devin (AI Software Engineer) | Software engineering | Resolved nearly 14% of GitHub issues (2x better than LLM chatbots). | [62] |
| Multi-Level Fault Detection | IoT & System Monitoring | Achieved ~92% accuracy in fault detection using a multi-level model. | [63] |
Experimental Protocols for Fault Recovery Assessment
To ensure the reproducibility and rigorous orthogonal characterization of autonomous workflows, detailing the experimental methodology for fault injection and recovery assessment is essential.
Protocol 1: Chaos Engineering for Distributed Workflows
This methodology, adapted from modern benchmarking studies, assesses the low-level infrastructure of distributed data systems [64].
- System Setup: Deploy the stream processing framework (e.g., Flink, Kafka Streams, Spark) in a containerized, cloud-native environment (e.g., Kubernetes). A standard data stream with constant event generation is established.
- Baseline Measurement: Under stable conditions, measure key performance indicators (KPIs) for a defined period (e.g., 30 minutes). KPIs include:
- Throughput: Events processed per second.
- Latency: End-to-end event processing time in milliseconds.
- Resource Utilization: CPU and memory consumption.
- Failure Injection (Chaos): Introduce a controlled failure into the running cluster. A critical, representative fault is the termination of a specific number of worker instance pods (e.g., 1 out of 4, or 2 out of 4 for a correlated failure). This simulates a common node crash.
- Recovery Monitoring: Continuously monitor the KPIs from the moment of failure until the system fully stabilizes. The primary metric is Recovery Time, defined as the duration from fault injection until throughput and latency return to within 10% of their pre-failure baseline values.
- Stability Assessment: After recovery, continue monitoring KPIs for a period equal to the baseline. Stability is quantified as the coefficient of variation (standard deviation/mean) of the throughput during this post-recovery window.
Protocol 2: Multi-Modal AI Workflow Fault Injection
This protocol evaluates the resilience of higher-level AI agents and laboratory automation systems [28] [61].
- Workflow Definition: Design a multi-step autonomous experiment, such as the synthesis and characterization of a target molecule. The workflow involves sequential steps: liquid handling for reagent dispensing, reaction control, sample collection, and product analysis via UPLC-MS or NMR [28].
- Baseline Establishment: Execute the workflow multiple times without faults to establish a baseline success rate and product yield.
- Controlled Fault Introduction: Introduce a specific, plausible fault into the workflow. Examples include:
- Hardware Fault: Software command to a robotic liquid handler to pick up a wrong labware or simulate a clogged tip.
- Data Fault: Introducing anomalous noise or a calibration drift signal into the output of an analytical instrument (e.g., NMR).
- LLM/Logic Fault: Providing an AI planner with an incorrect reagent property, leading to a flawed synthesis recipe.
- Recovery Evaluation: Activate the system's error detection and recovery mechanisms. The evaluation criteria are:
- Detection Time: Time from fault introduction to its identification.
- Diagnosis Accuracy: Correct identification of the fault's root cause.
- Recovery Success: Whether the system can autonomously execute a corrective action (e.g., recalculating a recipe, retrying a step with a different tool, or safely aborting the experiment) and still produce a valid result.
Workflow Architecture and Signaling Pathways
The resilience of an autonomous laboratory is determined by its underlying architecture. The following diagram illustrates the logical flow of a robust, self-healing system that integrates detection, diagnosis, and recovery.
Autonomous Fault Recovery Loop
The Scientist's Toolkit: Key Reagents for Autonomous Research
Building and operating a fault-tolerant autonomous laboratory requires a suite of hardware, software, and algorithmic "reagents." This toolkit is essential for implementing the robust workflows described in this guide.
Table 4: Essential Toolkit for Autonomous Workflow Research
| Tool / Component | Category | Function in Autonomous Workflows | Representative Examples |
|---|---|---|---|
| Robotic Liquid Handler | Hardware | Automates precise dispensing of reagents and samples, a foundational step in chemical or biological workflows. | Chemspeed ISynth synthesizer [28] |
| Analytical Instruments | Hardware | Provides orthogonal characterization data for product identification and yield estimation, critical for feedback. | UPLC–MS, benchtop NMR [28] |
| Stream Processing Framework | Software | Manages continuous data flows from instruments and sensors, enabling real-time monitoring and fault detection. | Apache Flink, Kafka Streams, Spark [64] |
| AI/ML Models for Characterization | Algorithm | Automates the interpretation of complex analytical data, such as phase identification from XRD patterns. | Convolutional Neural Networks (CNNs) [28] |
| Large Language Model (LLM) Agent | Algorithm | Serves as the "brain" for planning, reasoning about failures, and orchestrating recovery actions across tools. | Systems like Coscientist, ChemCrow [28] |
| Optimization Algorithm | Algorithm | Drives experimental optimization and iterative route improvement based on characterization results. | Bayesian Optimization, Active Learning [28] |
The evolution from brittle, rule-based error handling to adaptive, intelligent fault recovery marks a pivotal shift in autonomous workflow research. As demonstrated by the performance data and architectures presented, modern AI-driven and agentic paradigms offer significant improvements in resilience, adaptability, and overall operational efficiency. For researchers in drug development and materials science, the orthogonal characterization of these error-handling mechanisms is not a secondary concern but a core requirement for deploying reliable and truly autonomous discovery platforms. The future of this field lies in self-evolving ecosystems where workflows and their recovery mechanisms can adapt in real-time, further closing the gap between automated experimentation and genuine autonomous discovery.
The adoption of autonomous workflows in scientific research, particularly in drug discovery, represents a paradigm shift toward accelerated and more efficient experimentation. However, the efficacy of these closed-loop systems is fundamentally governed by the quality of their decision-making, which relies on robust data characterization and analysis. This guide evaluates three core computational strategies—transfer learning, uncertainty analysis, and standardized data formats—for enhancing autonomous workflows. The thesis central to this evaluation is that orthogonal characterization, the practice of using multiple, independent data sources to inform decisions, is critical for reliable outcomes in exploratory research. This objective comparison analyzes the performance of these strategies based on experimental data, detailing their implementation protocols and role in creating more intelligent and adaptable research platforms.
Transfer Learning for Overcoming Data Scarcity
Transfer learning (TL) is a machine learning paradigm that leverages knowledge from a related source domain to enhance model performance in a target domain, especially when data is scarce [65]. In drug discovery, where labeled datasets are often small, TL has emerged as a powerful solution to a major barrier for artificial-intelligence-assisted research [66]. Its application extends beyond image analysis to structured clinical and biomedical data, such as electronic health records (EHRs) and traditional cohort studies [65].
A recent scoping review of TL with structured clinical data highlights its growing adoption, with 78 of 86 reviewed papers published in 2020 or later [65]. The performance of TL is often measured by the Area Under the Curve (AUC) of the Receiver Operating Characteristic curve. For instance, the SmallML framework, a Bayesian transfer learning approach, demonstrated a 96.7% AUC on synthetic customer churn data with just 100 observations per business entity [67]. This represents a +24.2 percentage point improvement over independent logistic regression (72.5% AUC) and a +14.6 point improvement over complete pooling (82.1% AUC) [67]. The key to this performance is the framework's ability to extract informative priors from large public datasets and perform hierarchical Bayesian pooling across multiple small entities, effectively increasing the usable sample size.
Table 1: Comparison of Transfer Learning Framework Performance
| Framework / Model | Data Size | Performance (AUC) | Comparative Advantage |
|---|---|---|---|
| SmallML (Bayesian TL) | 100 observations | 96.7% ± 4.2% | +24.2 pts vs. standalone logistic regression [67] |
| Independent Logistic Regression | 100 observations | 72.5% ± 8.1% | Baseline performance [67] |
| Complete Pooling | 100 observations | 82.1% ± 9.3% | +9.6 pts vs. baseline [67] |
Experimental Protocol for Transfer Learning
Implementing a transfer learning framework like SmallML involves a structured, multi-layered protocol [67]:
- Bayesian Prior Extraction: A novel procedure using SHAP (SHapley Additive exPlanations) values extracts informative prior distributions from a gradient boosting model (e.g., XGBoost) pre-trained on a large, public source dataset. This transfers knowledge without requiring the source and target data to have identical distributions.
- Hierarchical Modeling: A hierarchical Bayesian model is implemented, which performs "partial pooling" across multiple related but distinct target entities (e.g., 5–50 different small businesses). This layer automatically balances population-level patterns from the source with entity-specific characteristics from the small target datasets, adapting the shrinkage of parameters accordingly.
- Uncertainty Quantification: The final layer wraps predictions using conformal prediction, a distribution-free method that provides finite-sample coverage guarantees (e.g., ℙ(y ∈ C(x)) ≥ 0.90). This ensures reliable uncertainty quantification even with very small datasets.
This protocol validates the thesis on orthogonal characterization by integrating multiple knowledge sources: the pre-trained model on public data (source domain), the small local datasets (target domains), and the hierarchical structure that creates an informational bridge between them.
Figure 1: A Bayesian transfer learning workflow for small-data scenarios, integrating knowledge from large public datasets and multiple small target entities.
Uncertainty Quantification for Reliable Decision-Making
In autonomous workflows, decisions are made without human intervention. Therefore, accurately quantifying the uncertainty of predictions is critical for prioritizing experiments and managing risk. This is particularly true in drug discovery, where experimental resources are limited and costly [68]. Uncertainty can arise from model parameters (epistemic uncertainty) and inherent noise in the data (aleatoric uncertainty).
Advanced uncertainty quantification (UQ) methods have been developed to handle real-world data challenges, such as censored labels—experimental observations that only provide a threshold value rather than a precise measurement [68]. In pharmaceutical settings, it is common for one-third or more of experimental labels to be censored. Research shows that adapting ensemble-based, Bayesian, and Gaussian models with tools from survival analysis (like the Tobit model) is essential for reliably estimating uncertainties in this context [68]. Without these methods, standard UQ approaches cannot utilize the partial information from censored labels, leading to overconfident and potentially misleading predictions.
The performance of UQ is often evaluated by its empirical coverage—the percentage of true values that fall within the predicted uncertainty interval. A well-calibrated model achieving 92% empirical coverage against a 90% target demonstrates high reliability [67]. In translational dose-prediction, uncertainty for parameters like human clearance is often quantified using Monte Carlo simulation, which propagates all sources of input uncertainty into a distribution of the predicted dose. Evaluations suggest that high-performance prediction methods for parameters like clearance and volume of distribution still carry an uncertainty factor of about three (meaning a 95% chance the true value falls within a threefold range of the prediction) [69].
Table 2: Uncertainty Quantification Methods and Their Applications
| Method | Primary Use Case | Key Strength | Supporting Evidence |
|---|---|---|---|
| Tobit Model for Censored Data | Drug discovery assays with censored labels | Utilizes partial information from thresholds for reliable UQ [68] | Essential when >30% of labels are censored [68] |
| Conformal Prediction | General small-data prediction | Provides distribution-free, finite-sample coverage guarantees [67] | Achieved 92% empirical coverage vs. 90% target [67] |
| Monte Carlo Simulation | Translational PK/PD dose prediction | Integrates all uncertain inputs into a final dose distribution [69] | Quantifies ~3-fold uncertainty in human clearance prediction [69] |
| Bayesian Inference with MCMC | Numerical model calibration | Accounts for epistemic uncertainty in model parameters [70] | Calibrated FE model for bridge monitoring without undamaged data [70] |
Experimental Protocol for Uncertainty Workflow
A protocol for integrating sophisticated UQ into an autonomous drug discovery workflow, particularly one handling censored data, would proceed as follows [68]:
- Data Preparation and Censoring Identification: Assemble the dataset from experimental assays and systematically identify censored labels, which indicate activity or potency values above or below a certain detection threshold rather than exact figures.
- Model Adaptation for Censoring: Select an appropriate base model (e.g., Gaussian process, ensemble, or Bayesian neural network) and adapt its loss function using the Tobit model framework. This modification allows the model to learn from both precise and censored observations.
- Temporal Evaluation and Validation: Evaluate the model's performance and uncertainty calibration on data collected from a different time period. This tests the model's robustness to natural distribution shifts that occur in real-world settings, a crucial step for validating practical utility.
- Decision-Making Integration: Feed the model's predictions and their associated uncertainty intervals into the autonomous workflow's decision-making algorithm. This allows the system to prioritize compounds with high potential but also high uncertainty for further testing, optimally balancing exploration and exploitation.
This protocol directly supports the thesis by ensuring that the single, often imperfect, data stream from an assay is characterized not just by a value, but by a rigorously calculated measure of confidence. This orthogonal perspective on the data—what we know versus how sure we are—is fundamental to robust autonomous decision-making.
Figure 2: An uncertainty quantification workflow integrating censored data analysis to guide autonomous decision-making.
Standardized Data Formats as a Foundational Enabler
Data standards are the foundational, often overlooked, strategy that makes advanced analytics like transfer learning and multi-site uncertainty quantification possible. A data standard is a set of rules defining how a particular type of data should be structured, defined, formatted, or exchanged [71]. In clinical and biomedical research, standardization is no longer a best practice but a regulatory requirement, with agencies like the U.S. FDA and Japan's PMDA mandating standards such as CDISC (SDTM, SEND, ADaM) for submissions [71] [72].
The performance gain from standardization is not measured in traditional metrics like AUC, but in efficiency, reproducibility, and interoperability. The FDA's CDER Data Standards Program, for instance, was established to simplify a review process that deals with over 300,000 submissions annually, amounting to millions of data points that previously arrived in a wide variety of formats, even on paper [71]. By making submissions predictable and consistent, standards allow reviewers and analytical systems to "focus more on the scientific review rather than spending precious time navigating huge amounts of less-structured data" [71].
The primary performance benefit for autonomous workflows is interoperability. Common Data Models (CDMs) like the OMOP CDM or PCORnet allow data from different sites and electronic health record (EHR) systems to be represented consistently [73]. This enables a single query or analytical model to be executed across a distributed network with little modification, directly enabling the large-scale data aggregation required for effective transfer learning. Without this, the "orthogonal" data from multiple sources cannot be meaningfully combined.
Implementation Protocol for Data Standardization
Implementing data standards in a research organization or for a specific autonomous workflow involves a multi-stage process [73] [72]:
- Standard Selection and Mapping: Identify the required or most suitable standards for the research domain (e.g., CDISC SDTM/SEND for clinical/nonclinical trial data, FHIR for EHR data exchange). Create a detailed mapping document that defines how each data element from local source systems (e.g., "Gender" coded as "1"/"0") corresponds to the target standard's structure and controlled terminology (e.g., "Sex" coded as "M"/"F").
- ETL (Extract, Transform, Load) Process Development: Build and validate automated pipelines that extract raw data from source systems, apply the transformation rules defined in the mapping, and load the standardized data into a target database or CDM. This step often requires significant investment in infrastructure and expertise.
- Validation and Quality Control: Execute rigorous quality checks to ensure the transformed data is accurate, complete, and compliant with the standard. This includes checking for errors introduced during mapping and verifying that the data retains its scientific meaning. Tools like Define-XML, which provides metadata for a dataset, are generated to support this process and regulatory review [72].
- Integration with Analytical Workflows: Configure autonomous workflow platforms and analytical models to directly consume the standardized data. The predictable structure allows for the development of reusable code and models, drastically reducing the setup time for new studies and enabling cross-study learning.
This protocol is the practical implementation of the thesis: it is the mechanism that makes diverse, orthogonal data sources technically and semantically compatible, thereby unlocking their collective power for more robust and generalizable autonomous research.
The Scientist's Toolkit: Essential Research Reagents and Solutions
The experimental strategies discussed rely on a foundation of specific tools, models, and data standards. The following table details key "research reagents" essential for implementing these advanced workflows.
Table 3: Essential Reagents for Advanced Autonomous Workflow Strategies
| Item Name | Type | Function in the Workflow |
|---|---|---|
| CDISC SDTM/SEND | Data Standard | Provides the required structure for organizing clinical and nonclinical study data, enabling regulatory review and cross-study analysis [72]. |
| CDISC ADaM | Data Standard | Defines a standardized method for creating analysis-ready datasets from SDTM data, ensuring traceability and reproducibility for statistical analysis [72]. |
| HL7 FHIR API | Data Exchange Standard | A modern, web-friendly interface for exchanging discrete healthcare data between systems, enabling real-time data access for decision support and precision medicine algorithms [73]. |
| SmallML Framework | Software Model | A Bayesian transfer learning framework designed to achieve high-accuracy predictions with very small datasets (50-200 observations), democratizing AI for resource-constrained settings [67]. |
| Tobit Model | Statistical Model | Adapts standard regression models to learn from censored data, enabling accurate uncertainty quantification in drug discovery assays where precise values are often unavailable [68]. |
| OMOP CDM | Common Data Model | Allows for the systematic analysis of distributed observational health data, enabling large-scale network studies and serving as a rich source domain for transfer learning [73]. |
| Conformal Prediction | Statistical Framework | Wraps around any prediction model to provide distribution-free, finite-sample guarantees for prediction intervals, crucial for risk-aware autonomous decision-making [67]. |
| Mobile Robot Agents | Laboratory Hardware | Enable modular autonomous laboratories by physically transporting samples between unmodified, specialized instruments (e.g., synthesizers, LC-MS, NMR), facilitating orthogonal characterization [2]. |
Integrated Workflow: Orthogonal Characterization in Action
A pioneering example that integrates all three strategies—modular data acquisition, multi-technique characterization, and algorithmic decision-making—is found in a 2024 modular autonomous platform for exploratory synthetic chemistry [2]. This platform uses mobile robots to operate an automated synthesis platform, a liquid chromatography–mass spectrometer (UPLC-MS), and a benchtop NMR spectrometer, allowing robots to share existing lab equipment without monopolizing it.
The critical element supporting our thesis is its heuristic decision-maker, which processes this orthogonal measurement data (UPLC-MS and NMR) to autonomously select successful reactions. In this workflow, reactions are characterized by both techniques, and the decision-maker assigns a binary pass/fail grade for each analysis based on expert-defined criteria. The results from each orthogonal analysis are combined to determine the subsequent synthetic steps [2]. This approach mimics human protocols by not relying on a single, potentially misleading, data stream. It explicitly uses orthogonal characterization to mitigate the uncertainty inherent in either technique alone, demonstrating a practical implementation of the core thesis for genuine exploratory discovery, such as in the identification of diverse supramolecular host-guest assemblies [2].
Figure 3: An autonomous exploratory workflow leveraging orthogonal data from LC-MS and NMR for heuristic decision-making.
Proving Efficacy: Benchmarking Autonomous Systems Against Conventional Research
Autonomous workflows are revolutionizing scientific discovery across fields from materials science to drug development. Their success hinges on robust evaluation using orthogonal characterization—the integration of multiple, independent measurement techniques. This guide compares current autonomous platforms by dissecting their performance on the critical metrics of accuracy, efficiency, and replicability.
Autonomous Platforms at a Glance
The table below provides a high-level comparison of representative autonomous platforms, highlighting their primary domains and characterization methodologies.
| Platform / Workflow Name | Primary Domain | Core Autonomous Technology | Orthogonal Characterization Methods |
|---|---|---|---|
| SEEK (Scientific Exploration with Expert Knowledge) [74] | Materials Science / Microscopy | Deep Kernel Learning (DKL) with active learning | High-resolution structural imaging (e.g., AFM, PFM) combined with localized spectroscopy (e.g., piezoresponse, current-voltage) |
| Modular Robotic Chemistry Platform [14] | Synthetic Chemistry | Mobile robots with heuristic decision-maker | Ultrahigh-performance liquid chromatography-mass spectrometry (UPLC-MS) and Benchtop Nuclear Magnetic Resonance (NMR) spectroscopy |
| Fluidic Self-Driving Labs (SDL) [75] | Chemical & Materials Synthesis | AI-driven optimization of flow chemistry | In-line/on-line monitoring (e.g., optical spectroscopy, chromatography, MS, NMR) |
Decoding the Experimental Protocols
A core principle of autonomous science is the closed-loop workflow, where experimentation, analysis, and decision-making are seamlessly integrated. The following diagram illustrates this universal cycle, which is instantiated in different ways across various platforms.
Detailed Methodologies in Practice
The generalized workflow is implemented with specific tools and processes in different scientific domains.
1. SEEK in Autonomous Microscopy [74] This protocol enhances the discovery of structure-property relationships at the nanoscale.
- Workflow: The process begins with acquiring a full structural image (e.g., topography). Image patches centered on each pixel are extracted to form a structure library. A pre-trained Deep Kernel Learning (DKL) model then predicts a "physical descriptor" (a scalar property of interest derived from spectral data) for all unmeasured locations. An acquisition function, such as expected improvement, uses the DKL's prediction and uncertainty to select the most informative location for the next spectroscopic measurement. This measurement is taken, the DKL model is retrained with the new data, and the loop repeats.
- Key Enhancement (SEEK): The SEEK framework incorporates prior expert knowledge by applying constraints. For example, a machine learning model can first identify specific structures of interest (like domain walls), and the DKL exploration is then focused only on this pre-filtered library, significantly improving efficiency [74].
2. Autonomous Exploratory Synthesis [14] This protocol is designed for open-ended chemical discovery where multiple products are possible.
- Workflow: A robotic synthesizer (e.g., Chemspeed ISynth) performs parallel chemical reactions. Upon completion, a mobile robot transports aliquots of the reaction mixtures to different analytical instruments, including a UPLC-MS and a benchtop NMR spectrometer. The data from these orthogonal techniques are processed by a heuristic decision-maker.
- Decision Logic: The decision-maker applies expert-defined rules to assign a binary "pass" or "fail" grade to the data from each analytical technique. A reaction must typically pass both analyses to be considered a "hit" and selected for further investigation or scale-up. This autonomous verification mimics human expert judgment and ensures only promising reactions are pursued [14].
Quantifying Performance: Accuracy, Efficiency & Replicability
The ultimate value of an autonomous platform is measured by its performance. The following table summarizes quantitative and qualitative metrics for evaluating these systems.
| Metric | Evaluation Approach | Representative Data from Platforms |
|---|---|---|
| Accuracy | Validation against known standards or human experts; statistical performance on defined tasks. | AI Nanoparticle Analysis [76]: Achieved an average F1 score of 0.91±0.01 for segmentation, with Hausdorff distance errors within 0.4±0.1 nm to 1.4±0.6 nm.Modular Chemistry Platform [14]: Uses orthogonal UPLC-MS and NMR to unambiguously identify chemical species, providing a high-confidence accuracy check. |
| Efficiency | Experiment throughput; reduction in time or resources to discovery; learning speed in active loops. | SEEK Framework [74]: Demonstrates more efficient exploration by incorporating structural constraints, reducing wasted measurements on uninteresting areas.Fluidic SDLs [75]: Offer heightened throughput and resource efficiency via reaction miniaturization, continuous processing, and real-time analytics, outperforming human-led workflows. |
| Replicability | Consistency of results across multiple experimental runs; robustness of the workflow to minor perturbations. | Modular Chemistry Platform [14]: The decision-maker includes a function to automatically check the reproducibility of any screening hits before they are scaled up.Fluidic SDLs [75]: The precise control and automated nature of flow chemistry reactors enhance experimental reliability and reproducibility compared to traditional manual batch processes. |
The Scientist's Toolkit: Essential Research Reagents & Solutions
Beyond software and robots, the physical tools for characterization are the bedrock of reliable data.
| Tool / Solution | Primary Function in Autonomous Workflows |
|---|---|
| Benchtop NMR Spectrometer | Provides structural elucidation of synthesized molecules; integrated modularly for autonomous decision-making in chemistry [14]. |
| UPLC-MS (Ultrahigh-Performance Liquid Chromatography-Mass Spectrometry) | Separates complex reaction mixtures (chromatography) and identifies components by molecular weight and fragmentation (mass spectrometry) [14]. |
| In-line Spectrophotometer | Integrated into flow chemistry reactors for real-time, continuous monitoring of reaction progress and product formation [75]. |
| Atomic Force Microscope (AFM) | Provides high-resolution structural imaging at the nanoscale, forming the structural library for active learning loops in microscopy [74]. |
| Segment Anything Model (SAM) | A foundation vision transformer model used for zero-shot segmentation of complex images, such as nanoparticles in TEM micrographs, without need for retraining [76]. |
Visualizing a Specific Workflow: Autonomous Nanoparticle Analysis
The diagram below details the two-stage AI workflow for high-throughput nanoparticle analysis, a specific instance of the generalized autonomous loop.
Rock mass characterization is a fundamental process in geotechnical engineering, critical for evaluating slope stability, designing underground excavations, and assessing geological risks. The accuracy and efficiency of this process directly impact the safety and success of engineering projects. Traditionally, characterization has relied on conventional field methods conducted by geologists and engineers using direct physical measurements. However, recent technological advancements have introduced semi-automatic approaches that leverage remote sensing and computational algorithms. This article provides a comparative analysis of these methodologies, examining their performance, experimental protocols, and integration into modern autonomous workflows. The evolution from conventional to semi-automatic methods represents a significant shift towards data-driven, orthogonal characterization—a core theme in autonomous systems research where multiple, independent measurement techniques are combined to enhance the robustness and reliability of outcomes [77] [2].
Quantitative Performance Comparison
The following tables summarize key performance metrics from comparative studies, highlighting the operational strengths and limitations of each characterization method.
Table 1: Key Performance Metrics from a Comparative Slope Study [77]
| Performance Metric | Conventional Field Survey | Digital Manual Measurement | Semi-Automatic Analysis |
|---|---|---|---|
| Coverage | 19% | 19% | 81% |
| Number of Discontinuities Identified | Not specified (baseline) | Not specified | 586 |
| Execution Time | ~10 hours | Not specified | Not specified |
| Orientation RMSE | Baseline | 3.27° | 2.58° |
| Spacing RMSE | Baseline | 0.012 m | 0.087 m |
| Persistence RMSE | Baseline | 0.063 m | 2.05 m |
| Replicability | Low (High dependence on expert judgment) | Moderate | High |
Table 2: General Comparative Analysis of Characterization Methods
| Aspect | Conventional Methods | Semi-Automatic Methods |
|---|---|---|
| Data Coverage & Safety | Limited to accessible areas; potential safety risks in unstable or high slopes [77] [78]. | Extensive coverage of inaccessible/hazardous slopes; enhanced personnel safety [77] [79]. |
| Operational Efficiency | Time-consuming data acquisition and processing [77] [80]. | Rapid data acquisition; processing speed varies with algorithm and dataset size [77] [78]. |
| Objectivity & Replicability | Subjective, highly dependent on surveyor's experience and judgment [77]. | Highly objective and reproducible results, minimizing human bias [77]. |
| Primary Limitations | Low spatial coverage, safety risks, subjectivity [77] [78]. | Sensitivity to point cloud quality (e.g., noise, vegetation); computational cost [77]. |
Experimental Protocols in Detail
To understand the data presented above, it is essential to consider the detailed experimental protocols for each method.
Conventional Field Survey Protocol
The conventional method serves as the established baseline in comparative studies. The standard protocol involves:
- Toolkit: Geological compass, clinometer, and measuring tape [77] [78].
- Procedure: Geologists or engineers physically access the rock face to take direct measurements of discontinuity parameters. This includes orienting the compass/clinometer on discontinuity planes and using the tape to measure spacing and persistence [77].
- Data Handling: All data is recorded manually in field notebooks. This method is constrained by the accessibility of the rock exposure and requires significant expert judgment, introducing subjectivity. The protocol is inherently time-consuming and can pose safety risks in unstable or steep slopes [77] [78].
Semi-Automatic Analysis Protocol
The semi-automatic method represents a technological leap, combining remote sensing with machine learning.
Data Acquisition:
- Toolkit: An Unmanned Aerial Vehicle (UAV) equipped with a high-resolution camera is typically used [77].
- Procedure: The UAV performs a pre-planned flight over the slope, capturing hundreds of overlapping images. To ensure high geometric accuracy (±5 cm or better), the process often integrates Real-Time Kinematic (RTK) GPS or Ground Control Points (GCPs) [77].
3D Model Generation:
- Algorithm: The overlapping images are processed using Structure from Motion (SfM) and Multi-View Stereo (MVS) algorithms. These algorithms reconstruct the 3D geometry of the rock surface, generating a dense point cloud and a Digital Surface Model (DSM) [77].
Discontinuity Extraction:
Diagram 1: Improved Regional Growing Algorithm Workflow.
- Advanced Machine Learning: Some studies employ K-Nearest Neighbors (K-NN) or other clustering algorithms for point cloud segmentation to further automate the identification of discontinuity sets [77]. Recent research also explores using tabular foundation models for generatively predicting the statistical distribution of discontinuities from limited measurements, showing superior accuracy and robustness [81].
The Scientist's Toolkit: Essential Research Reagents & Solutions
The following table lists key hardware, software, and algorithms that form the essential "reagents" for modern rock mass characterization.
Table 3: Key Research Reagents and Solutions for Rock Mass Characterization
| Tool/Reagent | Type | Primary Function |
|---|---|---|
| UAV (Drone) with RTK | Hardware | Captures high-resolution aerial imagery for 3D model generation with high geospatial accuracy [77]. |
| Terrestrial Laser Scanner (TLS) | Hardware | Collects high-density 3D point cloud data from a ground-based perspective [79]. |
| CloudCompare | Software | Open-source platform for 3D point cloud visualization, processing, and analysis [77] [79]. |
| Discontinuity Set Extractor (DSE) | Software/Plugin | A specialized plugin for semi-automatic identification and statistical analysis of discontinuity sets from point clouds [77]. |
| SfM-MVS Algorithms | Algorithm | Core photogrammetric processing to generate 3D models from 2D images [77]. |
| Regional Growing (RG) Algorithm | Algorithm | Segments point clouds by grouping points with similar surface normals to identify planar structures [78]. |
| Digital Drilling Process Monitoring (DPM) | Hardware/Software System | Provides a direct, in-situ method for evaluating rock mass quality and mechanical properties by monitoring drilling parameters [82]. |
The comparative analysis clearly demonstrates that semi-automatic methods outperform conventional surveys in key areas such as data coverage, operational safety, efficiency, and objectivity. While conventional methods provide valuable ground-truthed data, their limitations in challenging terrains are significant. The integration of UAV photogrammetry and robust algorithms like improved regional growing represents a move towards orthogonal characterization in autonomous workflows. This approach, where multiple independent data streams (e.g., imagery, point clouds, and drilling data) are fused, creates a more comprehensive and reliable understanding of rock mass behavior. This principle is fundamental to advancing autonomous research systems, not only in geotechnics but across scientific disciplines, enabling more robust and data-driven decision-making [77] [2] [80].
Validation Frameworks for AI-Generated Discoveries and Novel Syntheses
The integration of artificial intelligence (AI) into scientific discovery has catalyzed a paradigm shift, compressing traditional research timelines from years to months. AI-designed therapeutics are now progressing through human trials, and autonomous laboratories can conduct exploratory chemistry with minimal human intervention [6] [14]. However, this acceleration introduces a fundamental challenge: ensuring the reliability and validity of AI-generated discoveries. As these systems increasingly operate in open-ended exploratory environments—where the outcome is not a single optimized metric but a range of potential products—traditional validation methods are insufficient [14]. This guide examines the emerging validation frameworks that address this challenge, focusing on the critical practice of orthogonal characterization: the use of multiple, independent analytical techniques to verify results. We objectively compare leading platforms and methodologies, providing researchers with the data needed to evaluate these transformative technologies.
Comparative Analysis of AI Discovery Platforms and Their Validation Metrics
The efficacy of an AI-driven discovery platform is determined by its core AI approach, its integration of validation, and its demonstrated success in advancing candidates. The following table compares leading platforms that have successfully advanced novel candidates into the clinic or demonstrated robust autonomous operation.
Table 1: Performance Comparison of Leading AI-Driven Discovery Platforms
| Platform/ Company | Core AI Approach | Key Validation & Characterization Methods | Reported Discovery Speed | Clinical/Experimental Progress (as of 2025) |
|---|---|---|---|---|
| Exscientia | Generative AI for small-molecule design [6] | Patient-derived phenotypic screening, AI-designed target product profiles (potency, selectivity, ADME) [6] | Design cycles ~70% faster; 10x fewer compounds synthesized [6] | Multiple Phase I/II candidates; CDK7 & LSD1 inhibitors in trials [6] |
| Insilico Medicine | Generative chemistry for target and drug design [6] | AI-predicted target validation; progression to in-vivo and clinical studies [6] | Target-to-Phase I in 18 months for IPF drug [6] | Phase IIa results for TNIK inhibitor (ISM001-055) in IPF [6] |
| Schrödinger | Physics-enabled ML design [6] | Physics-based simulations (free energy perturbation) combined with experimental data [6] | Not specified | TYK2 inhibitor (zasocitinib) originated from platform now in Phase III [6] |
| A-Lab (Autonomous Lab) | AI-driven synthesis planning & active learning [28] | Powder X-ray diffraction (XRD) with ML analysis; active-learning-driven route optimization [28] | Continuous operation synthesizing 41 materials in 17 days [28] | 71% success rate in synthesizing predicted inorganic materials [28] |
| Modular Robotic Platform (Nature 2024) | Heuristic decision-maker [14] | Orthogonal UPLC-MS & NMR analysis with heuristic, expert-defined pass/fail criteria [14] | Mimics human protocols for exploratory synthesis [14] | Successfully applied to structural diversification and supramolecular host-guest chemistry [14] |
Experimental Protocols for Orthogonal Validation
A validation framework is only as strong as the experimental protocols that underpin it. Below, we detail the methodologies from two key platforms that exemplify rigorous, orthogonal characterization.
Protocol: Modular Robotic Workflow for Exploratory Synthesis
This protocol, detailed in Nature (2024), emphasizes orthogonal analysis and human-like decision-making for open-ended discovery [14].
- 1. Objective: To autonomously perform exploratory synthetic chemistry, identify successful reactions, and verify reproducibility using multiple characterization techniques.
- 2. Experimental Workflow:
- Synthesis: Reactions are performed in a Chemspeed ISynth automated synthesizer.
- Sample Reformating: The synthesizer takes an aliquot of each reaction mixture and reformats it separately for MS and NMR analysis.
- Sample Transport: Mobile robots transport the samples to the respective, unmodified analytical instruments located elsewhere in the lab.
- Orthogonal Analysis:
- UPLC-MS Analysis: Runs autonomously after sample delivery.
- Benchtop NMR Spectroscopy: 80-MHz ( ^1 \text{H} ) NMR spectra are acquired autonomously.
- 3. Data Integration & Decision-Making:
- A heuristic decision-maker, programmed with criteria defined by domain experts, processes the data from both techniques.
- Each analysis (MS and NMR) is assigned a binary pass/fail grade based on experiment-specific criteria (e.g., presence of expected masses, characteristic spectral changes).
- The results are combined, and reactions that pass both orthogonal analyses are selected for the next steps, such as scale-up or functional assay.
- 4. Validation Outcome: The system can autonomously navigate complex chemical spaces, such as supramolecular assembly, by relying on a multifaceted verification process that mirrors human judgment, thereby reducing the risk of false positives from any single analytical method [14].
Protocol: A-Lab for Autonomous Materials Discovery
This protocol focuses on the closed-loop synthesis and validation of inorganic materials [28].
- 1. Objective: To autonomously synthesize and verify theoretically predicted inorganic materials.
- 2. Experimental Workflow:
- Target Selection: Novel materials are selected from ab initio phase-stability databases (e.g., Materials Project).
- Recipe Generation: Natural-language models trained on literature data propose initial synthesis recipes.
- Robotic Synthesis: A robotic system handles solid-state precursor powders and executes the synthesis.
- Primary Characterization: The synthesized product is analyzed using X-ray diffraction (XRD).
- 3. Data Integration & Decision-Making:
- A machine learning model analyzes the XRD pattern for phase identification.
- If the synthesis fails to produce the target material, an active learning algorithm (ARROWS3) uses the characterization data to propose and test a modified synthesis route with new precursors or conditions.
- 4. Validation Outcome: The primary validation metric is the match between the measured XRD pattern and the theoretical pattern of the target material. The success rate of 71% (41 of 58 targets) demonstrates the effectiveness of this iterative, characterization-driven validation loop [28].
Workflow Visualization of Validation Frameworks
The following diagrams, generated with Graphviz, illustrate the logical flow of two dominant validation paradigms in autonomous discovery.
Orthogonal Analysis Workflow
Active Learning Validation Loop
The Scientist's Toolkit: Essential Research Reagents & Materials
The implementation of these validation frameworks relies on a suite of physical instruments and computational tools. The table below catalogs key solutions used in the featured experiments.
Table 2: Key Research Reagent Solutions for Autonomous Discovery and Validation
| Item Name | Function in Workflow | Specific Application in Validation |
|---|---|---|
| Chemspeed ISynth Synthesizer | Automated synthesis module [14] | Precisely executes reaction protocols and prepares aliquots for analysis, ensuring reproducibility [14]. |
| UPLC-MS (Ultraperformance Liquid Chromatography–Mass Spectrometry) | Orthogonal analytical technique [14] | Provides separation (chromatography) and molecular weight/identity (mass spec) for reaction mixture analysis [14]. |
| Benchtop NMR Spectrometer | Orthogonal analytical technique [14] | Provides structural information (( ^1 \text{H} ) NMR) to complement MS data, enabling confident product identification [14]. |
| Mobile Robotic Agents | Sample transport and instrument operation [14] | Creates a flexible, modular lab by linking separate instruments (synthesizer, MS, NMR) without bespoke engineering [14]. |
| Powder X-Ray Diffraction (XRD) | Primary characterization for solid-state materials [28] | Identifies crystalline phases in synthesized materials by comparing patterns to theoretical databases [28]. |
| Heuristic Decision-Maker Software | Algorithmic data interpretation [14] | Applies expert-defined rules to orthogonal data (MS & NMR), mimicking human pass/fail decisions for exploratory synthesis [14]. |
| Active Learning Algorithms (e.g., ARROWS3) | Iterative experimental optimization [28] | Uses characterization results from failed syntheses to intelligently propose new recipes, creating a closed validation-optimization loop [28]. |
The maturation of AI-driven discovery hinges on robust validation frameworks that extend beyond simple optimization to enable verifiable exploration. As evidenced by the platforms and protocols compared here, the consensus points toward multi-modal data integration and human-expert-informed heuristics as the cornerstones of reliable validation. The use of orthogonal characterization techniques, such as the combined application of UPLC-MS and NMR, is no longer a best practice but a necessity for confirming AI-generated syntheses in complex chemical spaces [14]. While AI and robotics provide scale and speed, the critical role of human domain expertise is simply shifting—from manual operation to the design of intelligent validation criteria and the interpretation of complex, multi-faceted results. The future of autonomous discovery will be built by platforms that can most effectively and transparently integrate this human wisdom into a continuous, self-improving cycle of experimentation and validation.
The research landscape in fields like chemistry and drug development is undergoing a profound transformation, moving from manual, time-intensive processes to AI-driven, automated workflows. This shift is central to the emerging paradigm of Agentic Science, where artificial intelligence (AI) systems function not merely as tools but as autonomous research partners capable of independent hypothesis generation, experimental planning, and execution [83]. The core of this transformation lies in the creation of closed-loop systems that integrate artificial intelligence, robotic experimentation, and advanced data analysis into a continuous, self-optimizing cycle [28]. This article evaluates the performance of these autonomous platforms against traditional and alternative research methods, with a specific focus on quantifying the radical compression of experimental setup and execution timelines—from weeks to hours. This acceleration is critically enabled by robust orthogonal characterization methodologies, which use multiple, non-redundant analytical techniques to provide a comprehensive and reliable understanding of experimental outcomes within these high-speed automated environments.
Performance Comparison of Autonomous Research Platforms
The following table summarizes the quantitative performance data of several pioneering autonomous and automated research platforms, highlighting their achieved acceleration factors and key performance metrics.
Table 1: Quantitative Performance Comparison of Research Platforms
| Platform / System | Reported Time Reduction / Acceleration Factor | Key Performance Metrics | Comparative Baseline (Traditional Methods) |
|---|---|---|---|
| A-Lab (Solid-State Materials) | 17 days of continuous operation to synthesize 41 target materials [28] | Successfully synthesized 71% (41 of 58) of target materials with minimal human intervention [28] | Traditional manual synthesis and characterization of a single material can take weeks to months. |
| Modular Robotic Chemistry Platform | Enabled multi-day campaigns for screening, replication, and scale-up [28] | Used dynamic time warping and heuristic decision-making to autonomously explore complex chemical spaces [28] | Manual exploration of similar chemical spaces requires extensive researcher time and effort. |
| Swiss Cat+ RDI (High-Throughput Chemistry) | Generates "large volumes of both synthetic and analytical data, far exceeding what would be feasible through manual experimentation" [84] | Data captured in structured, machine-actionable formats (ASM-JSON, JSON, XML); supports FAIR principles for data reuse [84] | Manual data recording is slow, prone to error, and often lacks standardization, hindering reproducibility and AI-readiness. |
| AI Workflow Automation (Business Context) | Process completion 5-10 times faster than manual processes; error rates decreased by 80-95% [85] | Operational labor costs reduced by 20-40% within 12 months; employees gained 2-4 hours daily [85] | Provides a generalized benchmark for automation efficiency gains applicable to research contexts. |
Experimental Protocols for Autonomous Workflow Evaluation
Core Architecture of an Autonomous Laboratory
The dramatic acceleration in research workflows is made possible by a foundational architecture that creates a closed-loop cycle of computation and experimentation. The general workflow of an autonomous laboratory can be summarized in the following diagram, which illustrates this continuous, iterative process.
This continuous workflow minimizes downtime between experimental cycles and eliminates subjective human decision bottlenecks, enabling rapid, around-the-clock experimentation [28]. The key differentiator from traditional methods is the seamless, automated handoff between each stage, which is responsible for the order-of-magnitude reduction in total setup and execution time.
Detailed Protocol: Multi-Stage Analytical Workflow with Orthogonal Characterization
The following diagram and protocol detail the specific automated workflow for chemical synthesis and analysis implemented at the Swiss Cat+ West hub, which exemplifies the integration of orthogonal characterization.
Protocol Steps:
- Digital Initialization: The workflow begins at a Human-Computer Interface (HCI), where sample and batch metadata (reaction conditions, reagent structures) are input in a standardized JSON format, ensuring traceability from the outset [84].
- Automated Synthesis: Compound synthesis is performed by Chemspeed automated platforms inside gloveboxes. These systems programmatically control parameters like temperature, pressure, and stirring. All synthesis data is automatically logged by ArkSuite software into a structured JSON file [84].
- Orthogonal Characterization & Decision Gates:
- Primary Screening: Samples are first analyzed by Liquid Chromatography (LC) coupled with multiple detectors: Diode Array Detector (DAD), Mass Spectrometry (MS), and Evaporative Light Scattering Detector (ELSD). This provides orthogonal data on retention time, UV-Vis spectra, molecular mass, and presence of non-chromophoric compounds [84].
- Secondary Screening: If no signal is detected in the primary LC analysis, the sample is automatically routed to Gas Chromatography-Mass Spectrometry (GC-MS), which is better suited for volatile or thermally stable species. This provides complementary analytical separation and identification [84].
- Decision Point 1 (Signal Detection): If neither LC nor GC detects a signal, the process is terminated for that compound. Crucially, this "negative data" is retained in the research data infrastructure, providing valuable information for robust AI model training [84].
- Decision Point 2 (Chirality): If a signal is detected, the workflow assesses whether chirality is a property of interest. If so, an automated solvent exchange is performed, followed by analysis using Supercritical Fluid Chromatography (SFC) with the same detector suite. SFC offers high-resolution separation of enantiomers [84].
- Data Unification & AI-Ready Output: All analytical data from the various instruments (Agilent, Bruker) is output in structured, machine-readable formats (ASM-JSON, JSON, XML). This standardized data, encompassing the entire experimental history including failed paths, is then processed and stored in a semantic, FAIR-compliant database (HT-CHEMBORD) for downstream AI analysis and model training [84].
The Scientist's Toolkit: Essential Research Reagent Solutions
The implementation of autonomous workflows relies on a suite of integrated hardware and software solutions. The table below details key components that form the backbone of these advanced research environments.
Table 2: Key Research Reagent Solutions for Autonomous Workflows
| Tool / Solution | Function in Autonomous Workflow |
|---|---|
| Chemspeed Automated Platforms | Robotic systems for programmable, parallel chemical synthesis under controlled conditions (temperature, pressure, stirring) [84]. |
| Allotrope Foundation Ontology | A standardized semantic model (ontology) that transforms experimental metadata into a machine-interpretable format, ensuring data interoperability and reusability [84]. |
| Liquid Chromatography (LC-DAD-MS-ELSD) | An orthogonal analytical instrument used for primary high-throughput screening, providing multiple data dimensions from a single analysis [84]. |
| Supercritical Fluid Chromatography (SFC-DAD-MS-ELSD) | A specialized chromatographic technique integrated for the specific task of chiral separation and analysis within the automated workflow [84]. |
| Argo Workflows | An open-source workflow engine that automates and orchestrates the entire data processing pipeline, from metadata conversion to storage, on a Kubernetes platform [84]. |
| Edge AI / High-Performance Computing (HPC) | Local, on-premises computing resources that enable low-latency, real-time AI inference for immediate feedback to robotic systems, ensuring operational resilience and data security [86]. |
| Large Language Models (LLMs) / AI Agents | Serve as the "brain" of the operation, capable of task decomposition, planning, tool use (e.g., code generation), and autonomous decision-making for experimental design and optimization [28] [83]. |
The quantitative data and experimental protocols presented demonstrate unequivocally that autonomous research platforms are capable of reducing critical setup and experimentation timelines from weeks to mere hours or days. This acceleration is not merely a result of faster equipment but stems from a fundamental architectural shift to closed-loop systems that integrate AI-driven planning, robotic execution, and, most critically, multi-layered orthogonal characterization. The Swiss Cat+ platform exemplifies how embedding multiple analytical techniques within a FAIR data infrastructure creates a powerful, self-learning system. For researchers in drug development and materials science, the adoption of these platforms, along with the standardized tools and protocols that support them, is transitioning from a competitive advantage to a necessity for maintaining leadership in an increasingly rapid-paced scientific landscape.
The Role of Human Oversight in Streamlining Error Handling and Quality Control
In the rapidly evolving field of autonomous scientific workflows, the integration of artificial intelligence and robotics has catalyzed a paradigm shift in experimental throughput and complexity. Platforms such as self-driving laboratories (SDLs) can achieve 10× to 100× acceleration in materials discovery and optimization compared to traditional manual research [87]. However, this acceleration introduces significant challenges in error handling and quality control, as autonomous systems navigate vast, high-dimensional parameter spaces with minimal human intervention. Within this context, human oversight emerges as a critical component for ensuring reliability, interpretability, and translational success. This article evaluates the role of structured human oversight within a broader thesis on orthogonal characterization, comparing its implementation and efficacy across leading autonomous platforms to provide a framework for researchers in drug development and related fields.
Comparative Analysis of Autonomous Platforms and Their Oversight Mechanisms
The design and implementation of human oversight vary significantly across autonomous laboratory platforms, directly influencing their performance and reliability. The following table summarizes the oversight approaches and key performance metrics of three prominent systems.
Table 1: Comparison of Autonomous Laboratory Platforms and Oversight Models
| Platform Name | Primary Domain | Reported Performance | Human Oversight Integration | Key Oversight Challenges |
|---|---|---|---|---|
| A-Lab [28] | Solid-state materials synthesis | Synthesized 41 of 58 target materials (71% success) over 17 days. | Minimal human intervention; oversight primarily in target selection and initial recipe generation. | Handling unexpected synthesis failures; generalization beyond training data. |
| Rainbow [87] | Perovskite nanocrystal optimization | Autonomous navigation of 6-dimensional input/3-dimensional output parameter space. | AI-driven experimental planning with human-defined objectives; human review of Pareto-optimal formulations. | Managing discrete and continuous parameters simultaneously; robust error detection. |
| Coscientist & ChemCrow [28] | Organic chemical synthesis | Successful optimization of palladium-catalyzed cross-couplings; synthesis of insect repellents. | LLM agents with tool-using capabilities (e.g., code execution, robotic control); human oversight in tool design and task specification. | LLM "hallucinations" generating incorrect procedures; confident-sounding but erroneous outputs; safety hazards. |
A critical insight from this comparison is that oversight must be designed, not merely delegated [88]. Simply placing a human "in the loop" without a structured model is a common but flawed approach. Effective systems integrate oversight into the core product design and pair it with robust testing and evaluation frameworks. For instance, Rainbow's hardware and AI agent are co-designed, enabling efficient human review of its Pareto-optimal findings [87]. In contrast, LLM-based systems like Coscientist, while powerful, highlight a unique oversight challenge: mitigating the risk of plausible but chemically impossible or dangerous procedures generated by the AI [28].
Experimental Protocols and Data Underpinning Oversight Efficacy
The performance data cited in Table 1 are derived from rigorous, published experimental campaigns. The methodologies below detail the protocols that generated this data, providing a blueprint for replicating such comparisons.
Protocol 1: Autonomous Solid-State Synthesis (A-Lab)
- Target Selection: Novel, theoretically stable materials are selected from large-scale ab initio phase-stability databases (e.g., Materials Project, Google DeepMind) [28].
- Recipe Generation: Natural-language models, trained on extensive literature data, propose initial synthesis recipes.
- Robotic Execution: A robotic system automatically handles precursor powders, executes solid-state reactions in furnaces, and manages sample collection.
- Orthogonal Characterization: X-ray diffraction (XRD) patterns are collected automatically and analyzed by machine learning models (convolutional neural networks) for phase identification.
- Active Learning: An optimization algorithm (ARROWS3) uses characterization results to propose improved synthesis routes for the next iteration, creating a closed loop [28].
Protocol 2: Multi-Robot Nanocrystal Optimization (Rainbow)
- Hardware Integration: The platform integrates a liquid-handling robot for precursor preparation and synthesis, a characterization robot for UV-Vis and photoluminescence spectroscopy, and a mobile robot for sample transfer [87].
- AI-Driven Workflow: For a human-defined target (e.g., maximizing PLQY at a specific emission energy), an AI agent uses a global Bayesian Optimization (BO) algorithm to select initial experimental conditions from a mixed-variable space (ligands, precursors, temperatures).
- Real-Time Analysis: The robotic system synthesizes NCs in parallelized, miniaturized batch reactors and conducts real-time spectroscopic characterization.
- Iterative Optimization: The AI agent analyzes the results and proposes the next set of experiments, systematically exploring and exploiting the parameter space to identify Pareto-optimal formulations [87].
Protocol 3: LLM-Driven Organic Synthesis (Coscientist/ChemAgents)
- Task Decomposition: A central LLM (e.g., GPT-4) decomposes a high-level command (e.g., "synthesize an insect repellent") into sub-tasks [28].
- Tool Utilization: The LLM leverages integrated tools, which may include web search for literature, computational modules for property prediction, and code generation for robotic control.
- Execution: Generated code is executed to operate robotic liquid handlers, synthesizers, and analytical instruments like UPLC-MS and NMR [28].
- Heuristic Validation: A separate module (e.g., a heuristic reaction planner) analyzes orthogonal analytical data (MS, NMR) using expert-defined criteria to assign a "pass/fail" before determining subsequent steps [28].
Visualizing the Human-AI Workflow in Autonomous Research
The following diagram illustrates the integrated workflow of an autonomous laboratory, highlighting the critical checkpoints for human oversight and the flow of information between AI, robotics, and human researchers.
Diagram 1: Autonomous Laboratory Workflow with Human Oversight
This workflow demonstrates that human oversight is not a single point of intervention but is integrated at multiple stages: defining the initial objective, validating the AI's proposed experimental direction, and approving the final outputs. This structured integration is essential for managing risks and ensuring the research remains aligned with its scientific goals [88] [89].
The Scientist's Toolkit: Essential Research Reagents and Materials
The successful operation of autonomous laboratories depends on a suite of specialized reagents, hardware, and software. The following table details key components and their functions within these integrated systems.
Table 2: Essential Research Reagent Solutions for Autonomous Workflows
| Item Category | Specific Examples | Function in Autonomous Workflow |
|---|---|---|
| Precursor Materials | Metal salts (e.g., CsPbX₃ precursors), Organic ligands (acids/bases), Solvents [87] | Raw materials for robotic synthesis of target molecules or nanomaterials, with diversity enabling exploration of a vast chemical space. |
| Automated Synthesis Hardware | Chemspeed ISynth synthesizer, Miniaturized parallel batch reactors, Solid-state furnaces [28] [87] | Modular, robotic platforms that perform precise dispensing, mixing, and reaction control without manual intervention. |
| Orthogonal Analytical Instruments | UPLC–MS, Benchtop NMR, XRD, UV-Vis/PL Spectrometers [28] [87] | Provide complementary (orthogonal) data on product identity, purity, yield, and functional properties for closed-loop decision-making. |
| AI/ML Software Agents | Bayesian Optimization algorithms, Active Learning frameworks, Convolutional Neural Networks, LLMs (e.g., in ChemAgents) [28] | The "brain" of the SDL; plans experiments, analyzes complex data, and iteratively updates the scientific model based on outcomes. |
| Robotic Sample Management | Free-roaming mobile robots, Automated liquid handlers, Robotic arms [28] [87] | Physically connect modules by transporting samples between synthesizers, analytical instruments, and storage. |
The evolution of autonomous workflows in scientific research does not diminish the role of the researcher but rather redefines it. The comparative data and experimental protocols presented herein demonstrate that the highest-performing systems are those that strategically integrate structured human oversight into their core design. This oversight is paramount for validating AI-generated hypotheses, interpreting complex results within a broader scientific context, managing unforeseen errors, and ensuring ethical compliance. As these platforms become more pervasive in critical fields like drug development, the frameworks for human-AI collaboration will become as vital as the algorithms and robotics that power the experiments themselves. The future of accelerated discovery lies not in full automation, but in synergistic human-AI teams where oversight is the linchpin of quality, reliability, and breakthrough innovation.
Conclusion
The fusion of orthogonal characterization with autonomous workflows represents a paradigm shift, moving AI from a specialized tool to a full research partner capable of robust and reproducible discovery. This synthesis confirms that leveraging multiple, independent analytical techniques is not merely an enhancement but a fundamental requirement for trustworthy autonomous science, particularly in high-stakes fields like drug development. The key takeaways—the critical need for data quality, modular hardware, robust error handling, and rigorous validation—provide a clear roadmap. Future progress hinges on developing more advanced AI foundation models, creating standardized interfaces, and fostering human-agent collaboration. As these systems mature, they promise to dramatically accelerate the translation of research from the bench to clinical application, ultimately reshaping the landscape of biomedical innovation.
References
- 1. A Survey on Autonomous Scientific Discovery [https://arxiv.org/html/2508.14111v2]
- 2. Autonomous mobile robots for exploratory synthetic chemistry [https://pmc.ncbi.nlm.nih.gov/articles/PMC11602721/]
- 3. Agentic AI vs. AI Agents vs. Autonomous AI: Key Differences [https://testrigor.com/blog/agentic-ai-vs-ai-agents-vs-autonomous-ai/]
- 4. AI Agents vs. Agentic AI: A Conceptual taxonomy, ... [https://www.sciencedirect.com/science/article/pii/S1566253525006712]
- 5. Measuring the Impact of Early-2025 AI on Experienced ... [https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/]
- 6. Leading AI-Driven Drug Discovery Platforms [https://www.sciencedirect.com/science/article/abs/pii/S0031699725075118]
- 7. The 2025 AI Index Report | Stanford HAI [https://hai.stanford.edu/ai-index/2025-ai-index-report]
- 8. Artificial Intelligence for Drug Development [https://www.fda.gov/about-fda/center-drug-evaluation-and-research-cder/artificial-intelligence-drug-development]
- 9. How AI will reshape pharma in 2025 [https://www.drugtargetreview.com/article/154981/how-ai-will-reshape-pharma-by-2025/]
- 10. What is a Particle Analysis "Orthogonal Method"? [https://www.fluidimaging.com/blog/orthogonal-method-particle-analysis]
- 11. Orthogonal Measurements | NIST [https://www.nist.gov/programs-projects/orthogonal-measurements]
- 12. Orthogonal method in pharmaceutical product analysis [https://alphalyse.com/orthogonal-method/]
- 13. Use of Orthogonal Methods During Pharmaceutical ... [https://www.chromatographyonline.com/view/use-orthogonal-methods-during-pharmaceutical-development-case-studies]
- 14. Autonomous mobile robots for exploratory synthetic chemistry [https://www.nature.com/articles/s41586-024-08173-7]
- 15. Enhancing therapeutic antibody profiling: orthogonal ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12510943/]
- 16. Orthogonal experimental-based thermal management ... [https://www.nature.com/articles/s41598-025-19098-0]
- 17. Determination of similar material proportions based on ... [https://www.frontiersin.org/journals/earth-science/articles/10.3389/feart.2025.1582941/full]
- 18. The future of AI regulation in drug development: a comparative ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12598624/]
- 19. Autonomous Self‐Evolving Research on Biomedical Data [https://pmc.ncbi.nlm.nih.gov/articles/PMC12165099/]
- 20. ORFit: One-Pass Learning via Bridging Orthogonal ... [https://arxiv.org/html/2207.13853v3]
- 21. Critical Quality Attributes Challenge Biologics Development [https://www.biopharminternational.com/view/critical-quality-attributes-challenge-biologics-development-0]
- 22. Critical Quality Attributes (CQAs) in Biologics Manufacturing [https://53biologics.com/blog/cqa-in-biologics/]
- 23. Biologics Characterization for Ensuring Quality and Consistency [https://www.mabion.eu/science-hub/articles/biologics-characterization-for-ensuring-product-quality-and-consistency/]
- 24. Analytical Methods to Determine the Stability of ... [https://www.chromatographyonline.com/view/analytical-methods-to-determine-the-stability-of-biopharmaceutical-products]
- 25. Biologics developability data analysis using hierarchical ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12068344/]
- 26. Simplified kinetic modeling for predicting the stability of ... [https://www.nature.com/articles/s41598-025-07037-y]
- 27. Orthogonal approach and critical quality attributes for gene ... [https://rrpharmacology.ru/index.php/journal/article/view/738/629]
- 28. Artificial intelligence-driven autonomous laboratory for ... [https://www.oaepublish.com/articles/cs.2025.66]
- 29. A Q&A on Viral Vector Integrity Analysis: Advancements in ... [https://www.isctglobal.org/telegrafthub/blogs/francheska-juliano/2025/10/08/a-qa-on-viral-vector-integrity-analysis-advancemen]
- 30. Computationally accelerated experimental materials ... [https://arxiv.org/html/2212.04804v2]
- 31. Comprehensive UPLC-MS/MS Method for Quantifying Four ... [https://www.mdpi.com/1420-3049/30/17/3477]
- 32. Recent Advances in Liquid Chromatography–Mass ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12204688/]
- 33. nano-Differential Scanning Fluorimetry (nanoDSF) [https://nanotempertech.com/nanodsf/]
- 34. Dark nanodiscs for evaluating membrane protein ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10808023/]
- 35. Comparison of ultra-performance liquid chromatography ... [https://www.sciencedirect.com/science/article/pii/S240584402309223X]
- 36. AI system learns from many types of scientific information ... [https://news.mit.edu/2025/ai-system-learns-many-types-scientific-information-and-runs-experiments-discovering-new-materials-0925]
- 37. AI-driven mobile robots team up to tackle chemical synthesis [https://news.liverpool.ac.uk/2024/11/06/ai-driven-mobile-robots-team-up-to-tackle-chemical-synthesis/]
- 38. LLMs and Multi-Agent Systems: The Future of AI in 2025 [https://www.classicinformatics.com/blog/how-llms-and-multi-agent-systems-work-together-2025]
- 39. Multi-Agent Multi-LLM Systems: The Future of AI ... [https://collabnix.com/multi-agent-multi-llm-systems-the-future-of-ai-architecture-complete-guide-2025/]
- 40. Multi-agent LLMs in 2025 [+frameworks] [https://www.superannotate.com/blog/multi-agent-llms]
- 41. The State of AI Agent Platforms in 2025: Comparative Analysis [https://www.ionio.ai/blog/the-state-of-ai-agent-platforms-in-2025-comparative-analysis]
- 42. Language Model Agents in 2025:. Society Mind Revisited [https://isolutions.medium.com/language-model-agents-in-2025-897ec15c9c42]
- 43. Breakthrough technology enables faster and cheaper ... [https://www.news-medical.net/news/20250904/Breakthrough-technology-enables-faster-and-cheaper-antibody-analysis.aspx]
- 44. Key Trends Shaping Therapeutic Antibodies in 2025 and ... [https://www.diatheva.com/key-trends-shaping-therapeutic-antibodies-in-2025-and-beyond/]
- 45. Technological advancements in antibody-based therapeutics ... [https://jbiomedsci.biomedcentral.com/articles/10.1186/s12929-025-01190-2]
- 46. Past, Present, and Future of Viral Vector Vaccine Platforms [https://pmc.ncbi.nlm.nih.gov/articles/PMC12115715/]
- 47. Running Out Of Data: It's A Strange Problem [https://www.forbes.com/sites/johnwerner/2025/10/15/running-out-of-data-its-a-strange-problem/]
- 48. Synthetic data for ML: the game-changer in training for 2025 [https://cleverx.com/blog/synthetic-data-for-ml-the-game-changer-in-training-for-2025]
- 49. Deep learning-based noise reduction method for the ... [https://pubmed.ncbi.nlm.nih.gov/41166879/]
- 50. Deep learning-based Generative Fixed-Filter Active Noise ... [https://www.sciencedirect.com/science/article/abs/pii/S0888327025009082]
- 51. LLM Hallucinations in 2025: How to Understand and ... [https://www.lakera.ai/blog/guide-to-hallucinations-in-large-language-models]
- 52. [2505.02151] Large Language Models are overconfident ... [https://arxiv.org/abs/2505.02151]
- 53. Mitigating Hallucination in Large Language Models (LLMs) [https://arxiv.org/html/2510.24476v1]
- 54. LLM Hallucination Detection and Mitigation: Best Techniques [https://www.deepchecks.com/llm-hallucination-detection-and-mitigation-best-techniques/]
- 55. Mitigating Overconfidence in Large Language Models [https://openreview.net/forum?id=y9UdO5cmHs]
- 56. Large Language Modeling of Hallucinatory Problem ... [https://www.sciencedirect.com/science/article/abs/pii/S0893608025008779]
- 57. LLM benchmarks in 2025: What they prove and what your ... [https://www.lxt.ai/blog/llm-benchmarks/]
- 58. Modular unit design and energy consumption ... [https://www.nature.com/articles/s41598-025-94070-6]
- 59. Modular Robotics Market Size and Share | Statistics 2025 [https://www.nextmsc.com/report/modular-robotics-market]
- 60. The Rise of Autonomous Labs in Life Science [https://www.sartorius.com/en/company/newsroom/blog/the-rise-of-autonomous-labs-in-life-science-1771962]
- 61. AI-Driven Error Recovery in Multi-Modal Workflows [https://www.prompts.ai/en/blog/ai-driven-error-recovery-in-multi-modal-workflows]
- 62. Autonomous generative AI agents: Under development [https://www.deloitte.com/us/en/insights/industry/technology/technology-media-and-telecom-predictions/2025/autonomous-generative-ai-agents-still-under-development.html]
- 63. Designing Self-Healing Systems for LLM Platforms - Ghost [https://latitude-blog.ghost.io/blog/designing-self-healing-systems-for-llm-platforms/]
- 64. A Comprehensive Benchmarking Analysis of Fault ... [https://arxiv.org/html/2404.06203v3]
- 65. A Scoping Review of Transfer Learning in Structured Data ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12408193/]
- 66. Transfer Learning for Drug Discovery [https://pubmed.ncbi.nlm.nih.gov/32672961/]
- 67. SmallML: Bayesian Transfer Learning for Small-Data ... [https://arxiv.org/html/2511.14049v1]
- 68. Enhancing uncertainty quantification in drug discovery with ... [https://www.sciencedirect.com/science/article/pii/S2667318525000042]
- 69. Quantifying and Communicating Uncertainty in Preclinical ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4429578/]
- 70. Transfer learning and Bayesian calibration addressing ... [https://www.sciencedirect.com/science/article/pii/S0888327025005461]
- 71. CDER Data Standards Program [https://www.fda.gov/drugs/electronic-regulatory-submission-and-review/cder-data-standards-program]
- 72. CDISC Data Standards Explained: CDASH, SDTM, SEND, ... [https://www.allucent.com/resources/blog/what-cdisc-and-what-are-cdisc-data-standards]
- 73. Data Formats - Rethinking Clinical ... [https://rethinkingclinicaltrials.org/chapters/conduct/acquiring-real-world-data/data-formats/]
- 74. Scientific exploration with expert knowledge (SEEK) in ... [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d4dd00277f]
- 75. The role of flow chemistry in self-driving labs [https://www.sciencedirect.com/science/article/abs/pii/S2590238525002486]
- 76. A versatile machine learning workflow for high-throughput ... [https://www.sciencedirect.com/science/article/abs/pii/S0304399125000154]
- 77. Comparative Analysis of Rock Mass Characterization ... [https://www.mdpi.com/2076-3417/15/21/11388]
- 78. Semi-automatic recognition of rock mass discontinuity ... [https://link.springer.com/article/10.1007/s42452-024-05876-4]
- 79. Semi-Automated rock block volume extraction from high ... [https://www.sciencedirect.com/science/article/pii/S1365160924003472]
- 80. An Approach to Rapidly Evaluating Rock Mass Quality in ... [https://link.springer.com/article/10.1007/s00603-024-04185-x]
- 81. [2511.13339] Statistically Accurate and Robust Generative Prediction... [https://arxiv.org/abs/2511.13339]
- 82. Evaluation of rock mass quality and its mechanical ... [https://www.sciencedirect.com/science/article/pii/S1674775525000678]
- 83. A Survey on Autonomous Scientific Discovery [https://arxiv.org/html/2508.14111v1]
- 84. A FAIR research data infrastructure for high-throughput digital ... [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d5dd00297d]
- 85. How AI Workflow Automation Saves Time Across Every ... [https://precallai.com/ai-workflow-automation-tools-save-time]
- 86. The Data-Driven Revolution: What the Lab of the Future ... [https://www.autonomous.ai/ourblog/the-data-driven-revolution-what-the-lab-of-the-future-looks-like]
- 87. Autonomous multi-robot synthesis and optimization of ... [https://www.nature.com/articles/s41467-025-63209-4]
- 88. You Won't Get GenAI Right if Human Oversight is Wrong [https://www.bcg.com/publications/2025/wont-get-gen-ai-right-if-human-oversight-wrong]
- 89. Ultimate Guide to Human Oversight in AI Workflows [https://magai.co/guide-to-human-oversight-in-ai-workflows/]