Optimizing High-Throughput Workflow Selection for Autonomous Experimentation in 2025
This article provides a comprehensive guide for researchers, scientists, and drug development professionals on selecting and optimizing high-throughput workflows for autonomous experimentation.
Optimizing High-Throughput Workflow Selection for Autonomous Experimentation in 2025
Abstract
This article provides a comprehensive guide for researchers, scientists, and drug development professionals on selecting and optimizing high-throughput workflows for autonomous experimentation. It covers foundational principles, practical methodologies for implementation, strategies for troubleshooting and optimization, and rigorous validation approaches. Drawing on the latest trends in AI, automation, and real-world case studies from pharmaceutical R&D and materials science, this resource is designed to help scientific teams accelerate discovery, improve data quality, and enhance operational efficiency in their labs.
The Foundations of Autonomous Experimentation and High-Throughput Workflows
Autonomous Experimentation (AE), also referred to as Self-Driving Labs (SDLs), represents a transformative paradigm in scientific research that combines artificial intelligence (AI), robotics, and automation to execute iterative research cycles without human intervention. This approach is defined as "an iterative research loop of planning, experiment, and analysis [that is] carried out autonomously" [1]. AE systems are designed to accelerate materials discovery and development—processes that can traditionally take decades—by orders of magnitude through closed-loop operation [2] [3]. Unlike automated systems that simply perform predefined tasks rapidly, genuine AE incorporates AI to dynamically design and select subsequent experiments based on real-time analysis of incoming data, effectively placing the "human on the loop" rather than "in the loop" [3]. This capability allows AE systems to investigate richer, more complex phenomena across high-dimensional parameter spaces that would be intractable for human researchers trained to reduce variables to manageable levels [2].
The value proposition of AE extends beyond mere acceleration. These systems can generate and test scientific hypotheses faster and more effectively than human researchers alone, producing deeper scientific understanding of materials phenomena and enabling rational investigations beyond naïve machine learning approaches [3]. The emerging infrastructure for AE envisions network effects where interconnected research robots collectively multiply the impact of each individual contribution, creating a tipping point in research productivity [2]. As the field advances, AE is poised to revolutionize materials synthesis, characterization, and development across diverse domains including pharmaceuticals, electronics, and energy applications.
Core Principles and Workflow Selection Framework
The Autonomous Experimentation Cycle
The fundamental operating principle of AE systems is a continuous, closed-loop process comprising three core phases: planning, execution, and analysis. In the planning phase, AI algorithms use mathematical models to design the next experiment based on accumulated data and campaign objectives. The execution phase involves robotic systems carrying out the physical experiment, often with in situ monitoring. In the analysis phase, data is processed and interpreted to inform the next planning cycle [1] [3]. This iterative process continues autonomously until the research objective is met or experimental resources are exhausted.
A critical capability of advanced AE systems is balancing exploration (probing unexplored regions of parameter space to discover new phenomena) against exploitation (refining conditions near known optima) [3]. The acquisition function—the algorithm that selects subsequent experiments—determines this balance based on the campaign objectives. For example, Bayesian optimization approaches using Gaussian process models can effectively guide measurement sequences across combinatorial libraries, as demonstrated in the discovery of improved phase-change memory materials [3].
Framework for High-Value Workflow Selection
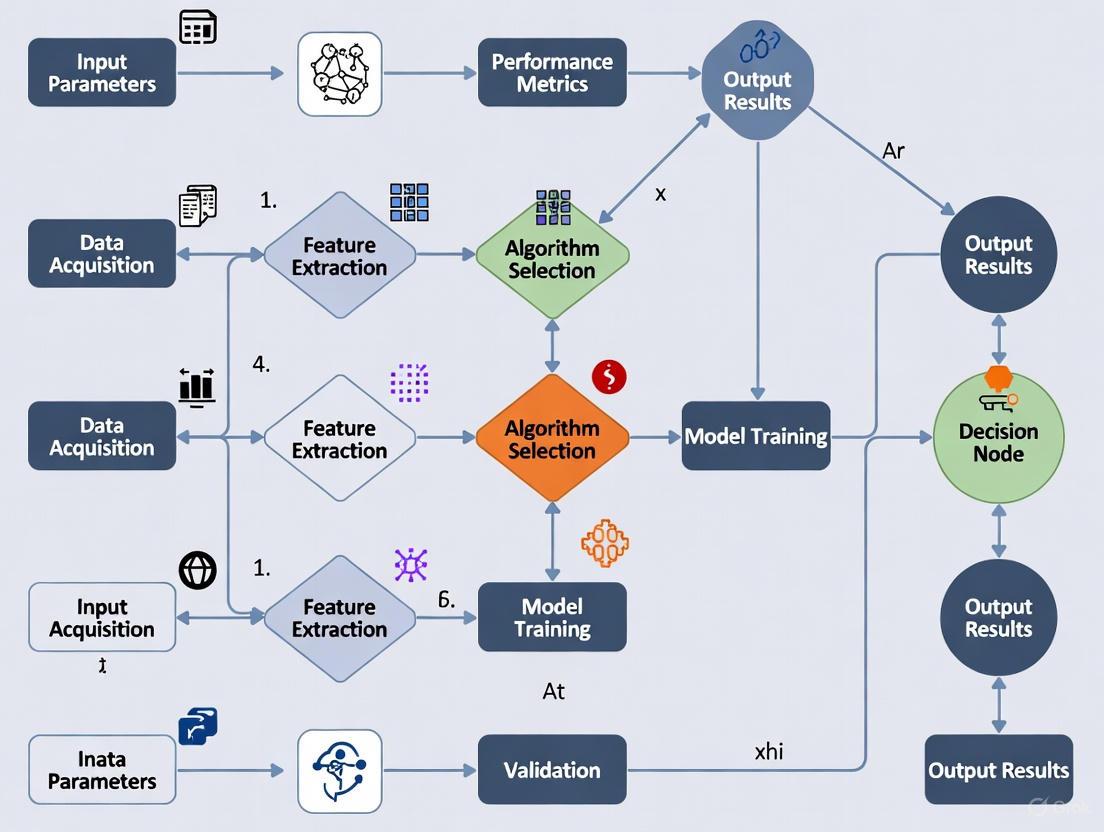
Selecting optimal data collection workflows is essential for AE efficiency. A robust framework enables AE systems to dynamically identify highest-value workflows that generate structured materials information according to user-defined objectives [1]. This framework follows a structured approach:
- Objective Establishment: The user defines the quantitative objective guiding workflow development
- Procedure Enumeration: The user specifies procedures, methods, and models available for workflow consideration
- Fast Search Implementation: The system rapidly filters possible workflows to identify high-quality candidates
- Fine Search Execution: The system selects the optimal workflow from high-quality candidates [1]
This framework conceptualizes that a well-designed Workflow generates relevant Information that delivers measurable Value, expressed as: Workflow → Information → Value [1]. The value of information is proportional to its Quality (accuracy, precision, certainty) and Actionability (utility for achieving objectives) [1]. This relationship enables quantitative workflow evaluation and selection, moving beyond static, human-designed protocols.
Table 1: Workflow Value Determination Factors
| Factor | Sub-Factor | Description | Impact on Value |
|---|---|---|---|
| Quality | Accuracy | Proximity to ground truth | Higher accuracy increases value |
| Precision | Reproducibility of results | Higher precision increases value | |
| Certainty | Confidence in information | Higher certainty increases value | |
| Actionability | Decision Support | Utility for high-value decisions | Critical objectives increase value |
| Cost Efficiency | Resource requirements | Lower cost increases net value | |
| Temporal Efficiency | Time requirements | Faster collection increases value |
Quantitative Performance of Autonomous Experimentation Systems
AE systems have demonstrated remarkable efficiency improvements across multiple materials science domains. The performance gains are quantified through reduced experimentation time, fewer required experiments, and accelerated discovery cycles compared to traditional approaches.
In a case study focusing on characterization workflows for additively manufactured Ti-6Al-4V samples, an AE system employing the workflow selection framework identified an optimal high-throughput workflow that reduced collection time for backscattered electron scanning electron microscopy (BSE-SEM) images by a factor of 85 compared to a previously published study, and by a factor of 5 compared to the case study's benchmark workflow [1]. This dramatic improvement was achieved through the integration of a deep-learning based image denoiser that enabled faster data acquisition without compromising information quality.
In materials synthesis, autonomous systems have demonstrated similar efficiencies. In the determination of eutectic phase diagrams for Sn-Bi binary thin-film systems, an AE campaign achieved accurate phase mapping with a six-fold reduction in the number of required experiments compared to conventional approaches [3]. This was accomplished through real-time, self-driving cyclical interaction between experiments and computational predictions, with the system autonomously guiding the sampling of composition-temperature space.
Table 2: Quantitative Performance Improvements in Autonomous Experimentation
| Application Domain | Traditional Approach | AE Approach | Performance Improvement |
|---|---|---|---|
| Image Characterization(Ti-6Al-4V BSE-SEM) | 85X time requirement(previous study) | Deep-learning denoising | 85X faster than previous study5X faster than benchmark [1] |
| Phase Diagram Mapping(Sn-Bi thin films) | Comprehensive samplingof parameter space | Gaussian process-guided sampling | 6X reduction in number ofexperiments required [3] |
| Material Discovery(Ge-Sb-Te system) | Full compositional rangemeasurement | Targeted sampling of promising regions | Identified optimal material after measuringonly a fraction of full range [3] |
| Carbon Nanotube Synthesis(CVD growth optimization) | One-variable-at-a-timeor full factorial | Iterative optimal experimental design | Rapid probing of 500°C temperature windowand 8-10 orders of magnitude pressure [3] |
Experimental Protocols and Methodologies
Protocol: Autonomous Chemical Vapor Deposition of Carbon Nanotubes
The ARES (Autonomous Research System) protocol for carbon nanotube synthesis represents a pioneering implementation of AE for materials synthesis [3].
Objective Definition: Define campaign goal, which may be either (1) Blackbox optimization to maximize target properties (e.g., CNT growth rate, minimize diameter variation) or (2) Hypothesis testing to confirm/reject scientific hypotheses (e.g., catalyst activity dependence on oxidation state) [3].
Workflow Setup:
- Equipment Configuration: Cold-wall CVD system with precursor gas introduction system, microreactor silicon pillars with pre-deposited catalysts, high-power laser heating system, and in situ Raman spectroscopy capability [3].
- Parameter Definition: Define adjustable parameters including temperature (adjustable over 500°C range), gas flow rates (hydrocarbon, hydrogen, oxidants), and partial pressure ratios (spanning 8-10 orders of magnitude) [3].
- Acquisition Function Selection: Choose appropriate algorithm (e.g., Bayesian optimization) to balance exploration and exploitation based on campaign objectives [3].
Execution Cycle:
- Planning Phase: AI planner selects growth conditions for next experiment based on all previous results and campaign objectives [3].
- Synthesis Phase: Focus laser on single silicon pillar microreactor to reach target temperature, introduce growth gases to initiate CNT synthesis [3].
- In Situ Characterization: Monitor CNT growth in real time using Raman spectroscopy of scattered laser light [3].
- Analysis Phase: Analyze spectral data to determine CNT characteristics (growth rate, quality, dimensions) [3].
- Iteration Decision: Assess if campaign objective is met; if not, return to planning phase for next iteration [3].
Validation: Compare final optimized conditions or hypothesis conclusions with literature values and physical models. For hypothesis testing campaigns, design experiments specifically to probe contrasting predictions of competing hypotheses.
Protocol: High-Throughput Workflow Selection for Material Characterization
This protocol enables AE systems to autonomously select optimal characterization workflows for extracted information [1].
Objective Establishment: Define the characterization goal (e.g., grain size measurement, defect density quantification, phase identification) and value metric (time minimization, information quality maximization, or balanced objective) [1].
Workflow Space Definition:
- Procedure Enumeration: List all available characterization techniques (e.g., SEM, TEM, XRD), operational modes (e.g., accelerating voltage, magnification, detector type), and data processing methods (e.g., deep-learning denoising, conventional filtering) [1].
- Constraint Specification: Define resource constraints (time, cost, computational resources) and minimum quality thresholds [1].
Workflow Selection Process:
- Fast Search Implementation: Rapidly screen workflow space to eliminate low-quality candidates that fail to meet minimum information quality thresholds [1].
- Fine Search Execution: Evaluate high-quality workflow candidates using multi-objective optimization that balances information quality, actionability, and resource consumption [1].
- Optimal Workflow Selection: Identify workflow that delivers highest value according to user-defined objective function [1].
Execution and Validation:
- Workflow Implementation: Execute selected workflow on target sample(s) [1].
- Performance Monitoring: Track actual information quality, resource utilization, and actionability compared to predictions [1].
- Database Update: Incorporate performance results into workflow knowledge base for future selection improvements [1].
- Iterative Refinement: Return to workflow selection if objectives are not met or new information needs emerge [1].
Diagram 1: Autonomous Workflow Selection Process (87 characters)
Essential Research Reagent Solutions and Materials
Successful implementation of AE requires both physical components and computational infrastructure. The table below details essential resources for establishing autonomous experimentation capabilities.
Table 3: Essential Research Reagent Solutions for Autonomous Experimentation
| Category | Item | Function | Application Examples |
|---|---|---|---|
| Sample Management | Universal Sample Holders | Standardized interface for handling diverse sample form factors (thin films, bulk samples, powders) [4] | Multi-material platformsHigh-throughput screening |
| Instrument Control | SiLA/EPICS/MQTT Protocols | Standardized communication for instrument control and data acquisition [4] | Robotics integrationReal-time monitoring |
| Data Management | FAIR Data Standards | Ensure machine-actionable, AI-Ready data (Findable, Accessible, Interoperable, Reusable) [4] | Knowledge graphsMeta-data management |
| AI/ML Infrastructure | Scientific AI Software Stack(PyTorch, TensorFlow, scikit-learn) | Physics-aware machine learning specialized for scientific data [4] | Bayesian optimizationDeep learning denoising |
| Synthesis Reagents | CVD Precursor Gases(e.g., ethylene, hydrogen) | Feedstock materials for vapor phase deposition processes [3] | Carbon nanotube growthThin film deposition |
| Catalyst Systems | Metal Nanoparticle Catalysts(e.g., Fe, Co, Ni) | Seed and template nanostructure growth [3] | CNT synthesisNanomaterial fabrication |
| Characterization Tools | In Situ Monitoring Systems(e.g., Raman spectroscopy) | Real-time material characterization during synthesis [3] | Process optimizationGrowth mechanism studies |
| Computational Frameworks | Autonomous Experimentation Environment(e.g., BlueSky, ChemOS) | High-level abstraction layer for experimental control [4] | Method portabilityAlgorithm comparison |
Standards and Infrastructure Requirements
The development of robust AE ecosystems depends on establishing standards across multiple domains. The National Institute of Standards and Technology (NIST) is leading efforts to develop standards for modular and autonomous laboratory ecosystems [4].
Sample Management Standards: Universal sample holder standards are needed to handle diverse materials forms including thin films, bulk samples, and powders. These standards would define physical form factors, size specifications, temperature ranges, and atmospheric control requirements, similar to the USB-C standard which defines multiple aspects at varying support levels [4].
Instrument Control and Communication Standards: Digital connectivity between AI infrastructure and physical laboratory equipment requires robust communication protocols. Existing frameworks including SiLA (Standardization in Lab Automation), EPICS (Experimental Physics and Industrial Control System), and IoT protocols like MQTT provide foundations, but require adaptation for materials-specific challenges [4].
Data and Knowledge Management Standards: Machine-actionable, AI-ready data are essential for autonomous systems. The FAIR (Findable, Accessible, Interoperable, Reusable) principles must be implemented through standardized data interchange formats and knowledge graphs that prioritize key instrument types [4].
Algorithm and Model Integration Standards: Portable algorithms that can operate across multiple autonomous systems require abstraction layers similar to the Atomic Simulation Environment used in computational materials science. Open-source autonomous experimentation environments (e.g., BlueSky, ChemOS, Hermes, HELAO) provide precursors for these standards [4].
Diagram 2: AE Standards and Infrastructure (58 characters)
In autonomous experimentation research, the strategic selection of high-throughput workflows is paramount for accelerating scientific discovery. The value generated by any experimental workflow is not a direct product of the data collected, but of the quality and actionability of the information extracted from that data [1]. This principle forms the foundation for effective, scalable research, particularly in fields like drug development where resources are precious and the cost of non-actionable data is high. This document outlines the core principles and provides practical protocols for researchers to quantify these concepts, enabling the systematic selection of optimal workflows that maximize informational value.
Core Conceptual Framework
The value-generation pathway of a workflow can be conceptualized as a direct chain: Workflow → Information → Value [1]. The value of the derived information is proportional to its quality and its actionability.
Defining Information Quality
Information Quality is an objective measure of the faithfulness of the extracted information to the true state of the system under investigation. It is proportional to the information's accuracy and precision with respect to a predetermined ground truth or reference [1]. High-quality information reliably reduces uncertainty about the system.
Defining Information Actionability
Information Actionability is a user-defined decision function that quantifies how useful the information is in achieving a specific objective [1]. It is context-dependent. For example:
- High-Actionability Information: The ground-truth defect density of a critical medical implant component for predicting failure probability.
- Lower-Actionability Information: An estimate of area fraction from a 2D image used as a proxy for 3D volume fraction when the latter is too expensive or difficult to measure [1].
A workflow's ultimate value is determined by the intersection of these two properties. A highly accurate measurement (high quality) is of little value if it does not inform the decision at hand (low actionability). Conversely, a highly actionable piece of information must be of sufficient quality to be trusted.
Quantitative Framework for Workflow Selection
To move from concept to practice, the value of a workflow must be quantified. The following table defines the key metrics that form the basis for an optimal workflow selection framework [1].
Table 1: Core Metrics for Quantifying Workflow Value
| Metric | Definition | Measurement Approach | Role in Workflow Selection |
|---|---|---|---|
| Information Quality | Fidelity of the information to the true system state. | Quantified by Accuracy (proximity to ground truth) and Precision (reproducibility) [1]. | Ensures the generated information is trustworthy and reduces epistemic uncertainty. |
| Information Actionability | Usefulness of information for achieving a specific objective. | A user-defined scoring function based on the decision context (e.g., cost of wrong decision, time-sensitivity) [1]. | Aligns the workflow output with the overarching experimental goal. |
| Acquisition Cost | Total resource expenditure for data collection. | Includes time, computational resources, consumables, and labor [1]. | Introduces practical constraints and enables cost-benefit analysis. |
A Protocol for Optimal Workflow Selection
The following protocol, adapted from a framework for autonomous materials characterization, provides a step-by-step methodology for selecting the highest-value workflow [1].
Protocol 1: Optimal Workflow Selection for Autonomous Experimentation
- Objective: To algorithmically select a high-throughput data collection workflow that maximizes information value for a given objective.
- Application Context: This protocol is designed for integration into autonomous experimentation loops, such as high-throughput screening in drug development or materials characterization [1] [5].
- Inputs: User-defined objective; a set of candidate procedures, methods, and models.
- Outputs: A selected optimal workflow with summary statistics of its performance.
| Step | Procedure | Rationale & Notes |
|---|---|---|
| 1. Establish Objective | The user defines a quantifiable objective to guide workflow development. | The objective must be clear and measurable, as it defines the actionability function. Example: "Identify the formulation with the highest binding affinity at a throughput of 100 samples/hour." |
| 2. Define Workflow Space | The user enumerates all potential procedures, methods, and models to be considered. | This creates the universe of possible workflows. Example components: sample preparation methods, imaging techniques (e.g., SEM, fluorescence), and data processing models (e.g., denoising algorithms) [1]. |
| 3. Fast Search | Conduct a broad search over the possible workflows to filter for high-quality candidates. | Uses simplified models or heuristics to quickly eliminate workflows that are clearly suboptimal in terms of quality or cost [1]. |
| 4. Fine Search | Perform a detailed evaluation of the shortlisted high-quality workflows. | The workflows are run and evaluated based on the precise metrics of Information Quality and Acquisition Cost, all measured against the user-defined objective (Actionability) [1]. |
| 5. Select & Deploy | Select the workflow with the highest value score. | The value score is a function of Quality, Actionability, and Cost. The selected workflow is then deployed in the autonomous experimental loop [1]. |
Case Study & Experimental Protocol
A case study on characterizing an additively manufactured Ti-6Al-4V sample illustrates the power of this framework. The objective was to collect high-quality backscattered electron SEM (BSE-SEM) images. The framework was used to select a workflow that incorporated a deep-learning-based image denoiser, allowing for much faster image acquisition times without significant loss of information quality [1].
Table 2: Research Reagent Solutions for High-Throughput Characterization
| Item | Function in the Experiment | Specification Notes |
|---|---|---|
| Ti-6Al-4V Sample | The system under investigation; a model material system. | Additively manufactured; prepared via standard metallographic procedures (cutting, mounting, polishing). |
| Scanning Electron Microscope (SEM) | Primary data collection instrument for high-resolution imaging. | Configured for Backscattered Electron (BSE) imaging to reveal material phase contrast. |
| Deep-Learning Denoiser | Computational model to reduce noise in images acquired with low electron dose or short dwell times. | The key enabling technology for high-throughput; allows for a factor of 85 reduction in collection time [1]. |
| Workflow Selection Software | Executes the framework logic (fast search, fine search) to select the optimal data collection parameters. | Can be custom-built or integrated into AE control software. |
The following DOT script visualizes the experimental workflow selected by the framework, highlighting the critical integration of the denoising model that enabled high-throughput operation.
Protocol 2: High-Throughput BSE-SEM Imaging with Integrated Denoising
- Objective: To acquire high-quality microstructural information from a Ti-6Al-4V sample at a throughput 85 times faster than a conventional workflow [1].
- Materials: Ti-6Al-4V sample, Scanning Electron Microscope, pre-trained deep-learning denoising model.
| Step | Procedure | Parameters & Notes |
|---|---|---|
| 1. Sample Preparation | Prepare the material sample for SEM imaging using standard metallographic techniques. | Ensure a flat, scratch-free surface to avoid imaging artifacts. |
| 2. Workflow Selection | Execute the Workflow Selection Framework (Protocol 1) to identify optimal SEM imaging parameters. | The framework will select a "low dose / fast scan" parameter set that minimizes acquisition time, justifying the use of the denoiser. |
| 3. Data Collection | Acquire the BSE-SEM image using the selected fast-scan parameters. | Results in a noisy image with low signal-to-noise but acquired in a fraction of the time (e.g., 5-85x faster) [1]. |
| 4. Data Processing | Apply the deep-learning-based denoising algorithm to the raw, noisy image. | The model infers and reconstructs a high-quality, denoised image. Model must be pre-validated on similar data. |
| 5. Information Extraction | Analyze the denoised image to extract quantitative microstructural information. | Perform tasks such as phase identification, grain size measurement, or particle counting. |
| 6. Validation | Compare the information extracted from the denoised image against a ground-truth image (e.g., a slow-scan, high-quality image). | Quantify accuracy and precision to confirm that information quality has been maintained despite the faster throughput. |
Results and Interpretation
In the cited case study, the selected workflow reduced the BSE-SEM image collection time by a factor of 85 times compared to a previously published study and by a factor of 5 times compared to the case study's own benchmark workflow [1]. This was achieved because the framework correctly identified that the Deep-Learning Denoiser could compensate for the lower Information Quality of the fast-scan RawData, producing a CleanData output with sufficient Information Quality for the objective. The immense reduction in Acquisition Cost made this workflow the highest-value option, perfectly balancing quality and actionability. This demonstrates a core principle: sometimes, the highest-value workflow is not the one that generates the highest-quality data in an absolute sense, but the one that generates fit-for-purpose quality at a drastically reduced cost.
The Role of AI and Machine Learning as the Central 'Brain' of Autonomous Labs
Autonomous laboratories represent a paradigm shift in scientific research, transitioning from human-directed experimentation to self-driving labs where Artificial Intelligence (AI) and Machine Learning (ML) serve as the central decision-making "brain." These systems integrate robotics, data infrastructure, and AI into a continuous closed-loop cycle, enabling them to conduct scientific experiments with minimal human intervention [6]. Within the context of high-throughput workflow selection for autonomous experimentation, the AI brain is responsible for learning from data, designing experiments, and dynamically allocating resources to optimize the research process. This approach accelerates discovery timelines and enhances the reproducibility and scalability of scientific research. Industry leaders are already seeing dramatic results—cutting development cycles by up to 70%, reducing testing costs by 50%, and accelerating materials discovery by 10x [7]. In drug discovery, this shift enables a faster understanding of biological mechanisms and allows prospective drug candidates to be tested more quickly and efficiently [8].
Core Architecture of the Autonomous Lab 'Brain'
The intelligence of an autonomous laboratory is not a single monolithic system but a layered architecture where different AI components specialize in specific cognitive functions. This multi-agent structure enables the lab to perform complex, multi-stage experiments autonomously.
Hierarchical AI Decision-Making Framework
A modern implementation of this architecture uses a hierarchical multi-agent system. For example, the ChemAgents framework features a central Task Manager that coordinates four role-specific agents:
- Literature Reader: Searches and synthesizes existing scientific knowledge
- Experiment Designer: Formulates testable hypotheses and designs experimental procedures
- Computation Performer: Runs simulations and predictions to inform experimental plans
- Robot Operator: Translates digital plans into executable commands for physical laboratory hardware [6]
The Closed-Loop Workflow
This AI brain operates through a continuous, self-optimizing workflow. The diagram below illustrates this closed-loop operation, which forms the core functional circuit of an autonomous laboratory.
This continuous loop minimizes downtime between experiments, eliminates subjective decision points, and enables rapid exploration of novel materials and optimization strategies [6]. The AI system's ability to adapt based on incoming data distinguishes it from simple automation, creating a truly learning system that improves its experimental strategy with each iteration.
Quantified Impact of AI-Driven Workflows
The integration of AI as the central nervous system of autonomous laboratories has produced measurable performance improvements across multiple industries. The following table summarizes key quantitative benefits observed in real-world implementations.
Table 1: Performance Metrics of AI-Driven Autonomous Laboratories
| Application Domain | Reported Efficiency Gains | Key Performance Indicators | Reference Implementation |
|---|---|---|---|
| Battery Materials Development | Development cycles reduced by up to 70% | 50% cost reduction in testing; 10x acceleration in materials discovery | BASF, Samsung SDI, Wildcat Discovery Technologies [7] |
| Pharmaceutical Research | Significant acceleration in understanding biological mechanisms | Faster testing of prospective drug candidates; Improved reproducibility | AstraZeneca, Evotec, Bayer [8] |
| Inorganic Materials Synthesis | 71% success rate in synthesizing predicted materials | 41 of 58 target materials successfully created in continuous operation | A-Lab autonomous synthesis platform [6] |
| Proteomics Workflow | 5x faster sequence identification | High-throughput analysis of 100+ sequences enabled by semi-automated tools | PeptoidSeq workflow for 20mer peptidomimetics [9] |
| Antibody Purification Process | Accelerated development timeframe | Minimized resource consumption; Automated data manipulation | High Throughput Process Development (HTPD) workflow [10] |
These performance improvements stem from the AI system's ability to optimize experimental plans, reduce redundant testing, and identify promising research directions that might elude human researchers. For instance, in battery engineering, AI-driven laboratories can conduct hundreds of parallel experiments, continuously analyzing results and adjusting parameters in real-time [7]. This represents a fundamental shift from sequential testing approaches that dominated traditional laboratories.
Implementation Protocols for AI-Driven Workflow Selection
Protocol: AI-Optimized High-Throughput Experimental Design
Objective: Systematically explore a multi-parameter experimental space to identify optimal conditions for material synthesis or biological response using AI-guided design.
Materials and Equipment:
- Robotic liquid handling system (e.g., Chemspeed ISynth synthesizer)
- Analytical instruments (UPLC-MS, benchtop NMR, or XRD)
- AI/ML software platform (Monolith AI, ChemOS, or custom Python implementation)
- Centralized data management system
Procedure:
- Define Parameter Space: Identify critical variables (temperature, concentration, pH, reaction time) and their feasible ranges based on literature and prior knowledge [6].
- Initial DoE Setup: Implement a Design of Experiments (DoE) with AI-generated initial points, leveraging Latin Hypercube Sampling or similar space-filling algorithms for maximum coverage [10].
- Active Learning Loop:
- Execute first batch of experiments using robotic systems
- Collect analytical data (spectra, yields, performance metrics)
- Train surrogate models (Gaussian Process Regression) on accumulated data
- Use acquisition functions (Expected Improvement, Upper Confidence Bound) to select next most informative experiments [6]
- Multi-Fidelity Optimization: Incorporate computational predictions and historical data to prioritize expensive experimental trials [4].
- Termination Criteria: Continue until performance targets met, budget exhausted, or convergence criteria reached (minimal improvement over 3 iterations).
Validation:
- Confirm optimal conditions through triplicate validation experiments
- Compare AI-derived optimum with traditional approaches
- Characterize resulting materials/products with orthogonal analytical methods
Protocol: Autonomous Discovery of Functional Materials
Objective: Discover and optimize new energy storage materials through fully autonomous synthesis and characterization.
Materials and Equipment:
- Powder handling robotics for solid-state synthesis
- High-temperature furnaces with automated loading/unloading
- X-ray diffractometer (XRD) with automated sample changer
- ML models for phase identification from XRD patterns
- Active-learning driven optimization algorithm (e.g., ARROWS3) [6]
Procedure:
- Target Selection: Identify novel theoretically stable materials using large-scale ab initio phase-stability databases (Materials Project, Google DeepMind) [6].
- Synthesis Recipe Generation: Use natural-language models trained on literature data to propose precursor combinations and synthesis temperatures [6].
- Robotic Synthesis: Execute solid-state synthesis recipes using automated powder handling and furnace systems.
- Phase Identification: Analyze XRD patterns with convolutional neural networks to identify successful synthesis and quantify phase purity [6].
- Iterative Optimization: Use active learning to modify synthesis routes based on results:
- Adjust precursor ratios
- Modify temperature profiles
- Explore alternative precursors
- Validation: Characterize successful materials for application-specific properties (electrochemical performance for battery materials).
Key Considerations:
- Implement sample tracking through standardized sample holders [4]
- Ensure FAIR (Findable, Accessible, Interoperable, Reusable) data principles throughout workflow [4]
- Maintain synthesis failure logs to improve AI decision-making
Essential Research Reagent Solutions
The implementation of AI-driven autonomous laboratories requires specialized materials and informatics tools. The following table details key research reagent solutions that enable high-throughput experimentation and data generation.
Table 2: Essential Research Reagents and Materials for Autonomous Laboratories
| Category | Specific Examples | Function in Workflow | Implementation Example |
|---|---|---|---|
| Specialized Linkers & Handles | Charged C-terminal lysine linker with ivDde protection | Enables sequencing of uncharged oligomers by amplifying y-ion detection in MS/MS | Peptoid sequencing with MALDI-TOF MS [9] |
| Solvatochromic Probes | Reichardt's dye | Colorimetric conformational analysis of immobilized macromolecules through environmental polarity sensing | High-throughput screening of peptoid library conformations [9] |
| Standardized Sample Holders | Universal holders for thin films, bulk samples, powders | Enables automated handling and transfer of diverse material formats between instruments | NIST sample management standards for modular labs [4] |
| Chromatography Resins | CEX resin candidates for antibody purification | High-throughput screening of purification conditions using minimal resources | HTPD workflow for antibody purification [10] |
| Characterization Standards | Peptide standards for LC-MS retention time calibration | Enables transfer of peptide target information between different instrument types | Rapid development of targeted proteomic assays [11] |
Integration and Standardization Frameworks
The full potential of AI-driven autonomous laboratories can only be realized through robust integration frameworks and standardization. The National Institute of Standards and Technology (NIST) is leading efforts to develop standards for a modular and autonomous laboratory ecosystem, addressing four critical areas [4]:
Sample Management Standards: Universal sample holders that handle different sample form factors (thin films, bulk samples, powders) with defined specifications for size, temperature range, and atmospheric control [4].
Instrument Control and Communication Standards: Evaluation of existing protocols (SiLA, EPICS, MQTT) to address the unique challenges of materials research hardware, moving beyond "fragile hacks" to robust interfaces [4].
Data and Knowledge Management Standards: Emphasis on FAIR data principles with consensus on data interchange formats and knowledge graphs to ensure AI-ready data [4].
Algorithm and Model Integration Standards: Development of high-level interfaces (similar to Atomic Simulation Environment) for experimental materials science to enable algorithm portability across different autonomous systems [4].
The relationship between these components creates a foundation for interoperable autonomous research systems, as shown in the following architecture diagram.
This standards-based approach dramatically reduces the cost of engineering an autonomous platform while reducing the risk of obsolescence by ensuring expandability and upgradeability [4]. Just as the internet revolution was enabled by low-level communication standards, the laboratory revolution will be powered by this standards-based modular ecosystem.
Regulatory and Compliance Considerations
As autonomous laboratories become more prevalent, particularly in regulated industries like pharmaceuticals, compliance with emerging AI regulations becomes essential. Key considerations include:
- Algorithmic Impact Assessments: Required before deploying automated decision-making tools, as outlined in Colorado AI Act and California SB 1047 [12].
- AI Governance Structures: Establishment of multidisciplinary ethics committees and bias mitigation strategies throughout the AI lifecycle [12].
- Documentation Standards: Maintaining detailed records of AI system decision-making processes, training data sources, and bias mitigation measures [12].
- Transparency Requirements: Content disclosures under the California AI Transparency Act and adherence to FAIR data principles for regulatory submissions [12].
Companies implementing autonomous laboratories should develop tiered governance structures that align with risk levels while maintaining operational efficiency, incorporating regular audit mechanisms to validate adherence to established guidelines [12].
AI and machine learning have evolved from supportive tools to the central cognitive system of autonomous laboratories, capable of designing experiments, executing them through robotic systems, analyzing results, and iterating based on learned knowledge. This transformation enables unprecedented efficiency gains, with documented reductions in development cycles by up to 70% and cost reductions of 50% in industrial applications [7]. The implementation of standardized interfaces for sample management, instrument control, data management, and algorithm integration [4] will further accelerate adoption across diverse scientific domains.
For researchers selecting high-throughput workflows for autonomous experimentation, success depends on selecting appropriate AI decision architectures, implementing robust data standards, and addressing emerging regulatory requirements. As these systems mature, the role of human scientists will shift from manual execution to creative problem-solving and strategic oversight [8], potentially unlocking new frontiers in materials science, drug discovery, and beyond. The organizations that most effectively integrate AI as the central brain of their research operations will gain significant competitive advantages in the rapidly evolving landscape of scientific discovery.
Application Note
The evolution of high-throughput screening (HTS) into autonomous experimentation represents a paradigm shift in drug discovery and biological research. This transformation is powered by the strategic integration of three core technological pillars: advanced robotic systems for physical task execution, sophisticated AI planning for experimental design and decision-making, and comprehensive automated analysis platforms for data interpretation. Together, these components create closed-loop systems capable of designing, executing, and analyzing experiments with minimal human intervention, dramatically accelerating the pace of scientific discovery while reducing costs and improving reproducibility [13] [14].
Traditional drug discovery has been hampered by extensive timelines (10-15 years), high costs (exceeding $2 billion per therapeutic), and failure rates exceeding 90% before clinical testing [13]. The integration of robotic automation, AI, and automated analysis addresses these inefficiencies by enabling researchers to explore vast chemical spaces—estimated at 10⁶⁰ potential molecules—that were previously inaccessible through manual methods [13]. This application note examines the key components of these integrated systems and provides detailed protocols for their implementation in autonomous research workflows.
System Components and Their Integration
Robotic Systems for Physical Automation
Modern robotic systems for high-throughput experimentation have evolved from fixed automation to modular, adaptable platforms featuring collaborative robots that can safely operate alongside researchers [14]. These systems incorporate multiple specialized components:
- Liquid handling devices capable of dispensing reagents in microliter to nanoliter volumes with precision, minimizing reagent consumption while enabling miniaturization [15].
- Robotic workstations that transfer microplates between different stations (pipetting, incubation, reading) within the automated workflow [16] [15].
- Integrated automation systems that manage sample and reagent transfer, mixing, and final readout with minimal human intervention [15].
- Modular unguarded systems that provide enhanced flexibility and accessibility while maintaining screening productivity [14].
These robotic platforms typically process samples in 96- to 3456-well microplates, with ultra-high-throughput systems capable of analyzing over 100,000 samples daily [15]. The transition to modular systems allows research institutions to adapt quickly to changing experimental demands without replacing entire automation infrastructures.
AI Planning and Experimental Design
Artificial intelligence serves as the cognitive center of autonomous experimentation, dramatically accelerating the design-make-test-analyze (DMTA) cycle through several key capabilities:
- Target Identification and Validation: AI algorithms mine omics datasets, scientific literature, and clinical data to identify novel disease-relevant biological targets. Machine learning models detect patterns invisible to human researchers, such as subtle gene expression correlations or pathway perturbations [13].
- Virtual Screening and Hit Discovery: Instead of experimentally screening millions of compounds, AI models predict which molecules are most likely to interact with target proteins. Generative AI models, including variational autoencoders and diffusion models, can design entirely novel molecular structures optimized for specific binding characteristics [13].
- Lead Optimization: AI predicts absorption, distribution, metabolism, excretion, and toxicity (ADME/Tox) profiles, enabling chemists to modify molecular structures intelligently before synthesis [13].
- Adaptive Experimental Planning: AI systems dynamically redesign experiments based on incoming results, focusing resources on the most promising regions of chemical or experimental space [13].
Companies like Insilico Medicine, Exscientia, and Atomwise have demonstrated the power of AI-driven drug discovery, with examples such as Insilico's fibrosis drug reaching Phase II clinical trials in under three years—an unprecedented timeline compared to traditional approaches [13].
Automated Analysis Systems
Automated analysis platforms transform raw experimental data into actionable insights through multiple interconnected technologies:
- High-throughput detectors and plate readers that assess fluorescence, luminescence, absorption, and other specific parameters for thousands of samples with minimal human input [15].
- Data processing software that handles the enormous data volumes generated by HTS systems, employing quality control measures to identify issues such as pipetting errors and edge effects caused by evaporation [15].
- Machine learning-powered data quality tools that automatically detect anomalies and ensure data reliability before analysis [17].
- Cloud-based data integration that connects instrument data, AI-driven analytics, and molecular design databases through laboratory information management systems (LIMS) and electronic lab notebooks (ELNs) [13].
These automated analysis systems incorporate sophisticated quality control measures, including plate-based controls that characterize assay performance and sample-based controls that measure variability in biological responses [15].
Performance Metrics and Applications
Table 1: Performance Metrics of Integrated Autonomous Experimentation Systems
| Metric Category | Traditional Approach | AI-Automation Integrated System | Improvement Factor |
|---|---|---|---|
| Discovery Timeline | 10-15 years (drug development) | 3 years (INS018_055 example) | 3-5x faster [13] |
| Screening Throughput | Limited by manual processes | >100,000 samples per day | >10x improvement [15] [18] |
| Sample Preparation | Hours to days for 96 samples | 2.5 hours for 96 samples | ~10x faster [18] |
| Data Processing | Manual analysis with high error rate | Automated analysis with ML-powered QC | Significantly improved accuracy [17] [15] |
| Hit Identification | Low hit rates due to limited exploration | AI-predicted binding affinities | Dramatically increased hit rates [13] |
Integrated autonomous systems have demonstrated remarkable success across multiple application domains:
- Drug Discovery: Identification of biologically active compounds against therapeutic targets, such as the use of high-throughput screening to identify small molecules that bind to cardiac MyBP-C for heart failure treatment [15].
- Precision Medicine: Screening of anticancer drug libraries against patient-derived tumor samples to identify optimal treatment strategies [15].
- Toxicology Assessment: Utilization of model organisms like C. elegans in high-throughput assays to evaluate compound toxicity across multiple lifecycles [15].
- Target Identification: Automated proteomics platforms that identify both primary targets and off-target effects of drug candidates, as demonstrated by the autoSISPROT platform's analysis of kinase inhibitors [18].
Implementation Challenges and Solutions
Despite their transformative potential, implementing integrated autonomous experimentation systems presents several challenges:
- Data Quality and Integration: Incomplete or biased datasets can skew AI predictions. Solution: Implement curated, standardized assay databases and cloud-based workflow orchestration [13].
- System Interoperability: Legacy instruments and software often lack interoperability. Solution: Utilize modular systems with API-driven integration capabilities [13] [14].
- Cultural Resistance: Researchers may fear job displacement. Solution: Develop training programs focused on AI-human collaboration [13].
- Interpretability: Deep learning models often function as "black boxes." Solution: Incorporate explainable AI (XAI) tools to enhance transparency [13].
Protocols
Protocol 1: Implementation of an Integrated Screening Workflow for Compound Identification
Purpose
To establish a complete autonomous workflow for identifying biologically active compounds against a specific therapeutic target through the integration of robotic systems, AI planning, and automated analysis.
Materials and Equipment
Research Reagent Solutions and Essential Materials
Table 2: Essential Research Reagents and Materials for Autonomous Screening
| Item | Function | Specifications |
|---|---|---|
| Compound Libraries | Source of potential active molecules | Thousands to millions of compounds; commercially available or custom-synthesized [16] |
| Assay Plates | Platform for biochemical reactions | 96- to 3456-well microplates; type selected based on assay requirements [15] |
| Biological Targets | Disease-relevant proteins or pathways | Purified proteins or cell lines expressing target of interest [16] |
| Detection Reagents | Enable measurement of interactions | Fluorescent, luminescent, or absorption-based markers [16] [15] |
| Liquid Handling Consumables | Precision delivery of reagents | Disposable tips, reservoirs, tubing compatible with automated systems [16] |
Equipment
- Modular robotic platform with collaborative robots [14]
- Automated liquid handling systems [15]
- High-capacity microplate incubators and storage systems [16]
- Multi-mode plate readers (fluorescence, luminescence, absorption) [15]
- High-performance computing infrastructure for AI/ML processing [13]
- Laboratory Information Management System (LIMS) [13]
Procedure
Target Selection and Validation
- Utilize AI algorithms to mine omics datasets and scientific literature for disease-relevant targets [13]
- Validate selected targets through pathway analysis and expression profiling
- Document target selection rationale in electronic lab notebook (ELN)
Assay Development and Optimization
- Develop either cell-based or biochemical assays sensitive to target-compound interactions
- Optimize assay conditions for automation compatibility and miniaturization
- Implement appropriate controls (positive, negative, vehicle) for quality assessment
- Validate assay performance using known ligands or modulators if available
AI-Driven Compound Selection and Library Design
- Employ virtual screening to prioritize compounds from existing libraries [13]
- Utilize generative AI models to design novel compounds if needed
- Apply QSAR models to estimate binding affinities and ADME properties
- Curate final compound set for experimental testing
Automated Sample Preparation and Screening
- Program liquid handlers to transfer compounds and reagents to assay plates
- Implement robotic systems to manage plate movement between stations
- Execute screening runs with appropriate sample randomization
- Monitor system performance through integrated sensors and cameras
Automated Data Collection and Analysis
- Collect readouts using appropriate detectors (fluorescence, luminescence, etc.)
- Process raw data using automated analysis pipelines
- Apply quality control metrics to identify and exclude problematic assays
- Identify "hits" based on predetermined activity thresholds
AI-Powered Iterative Optimization
- Feed experimental results back to AI models for continuous learning
- Design subsequent rounds of compounds based on structure-activity relationships
- Prioritize confirmed hits for secondary assays and counter-screens
Timing
- Steps 1-2: 2-4 weeks (initial setup)
- Steps 3-5: 1-3 days per screening cycle
- Step 6: Continuous iterative process
Protocol 2: Automated Proteomics Sample Preparation for Target Deconvolution
Purpose
To implement a fully automated proteomics workflow for identifying drug targets and off-target interactions using the autoSISPROT platform or equivalent system.
Materials and Equipment
- Automated proteomics sample preparation platform (e.g., autoSISPROT) [18]
- Thermal proteome profiling (TPP) reagents and buffers
- Isobaric labeling tags (TMT) if required [18]
- Mass spectrometry-grade solvents and digestion enzymes
- High-resolution mass spectrometer with data-independent acquisition (DIA) capability [18]
Procedure
Sample Processing
- Program automated platform to process up to 96 samples in parallel
- Implement all-in-tip operations for protein digestion and desalting
- Optional: Incorporate TMT labeling for multiplexed quantification
Thermal Proteome Profiling
- Treat samples with compounds of interest at relevant concentrations
- Perform heat denaturation at controlled temperatures
- Separate soluble fractions for subsequent analysis
Automated Sample Preparation
- Execute protein digestion using the automated platform (achieving >94% efficiency)
- Perform TMT labeling if applicable (>98% efficiency)
- Cleanup and concentrate samples for mass spectrometry analysis
Data Acquisition and Analysis
- Acquire proteomics data using data-independent acquisition (DIA) mode
- Process raw data using automated quantification pipelines
- Identify stabilized and destabilized proteins across temperature ranges
- Annotate known targets and potential off-targets based on melting curves
Timing
- Total processing time: <2.5 hours for 96 samples (additional 1 hour if TMT labeling required) [18]
Workflow Visualization
Autonomous Experimentation Workflow
Integrated System Architecture
Data Analysis Pipeline
Implementing High-Throughput Workflows: From Design to Real-World Application
In autonomous experimentation research, the selection of a high-throughput workflow is a critical strategic decision that directly impacts the pace and reliability of scientific discovery. An optimal workflow functions as an integrated system that transforms experimental inputs into high-value information, a relationship defined by the core principle: Workflow → Information → Value [1]. The value of the generated information is proportional to its quality and its actionability for achieving specific research objectives [1].
The modern experimental landscape is characterized by multi-fidelity models and complex, automated pipelines. The design and operation of these systems often rely on expert intuition, which can lead to suboptimal performance and inefficient use of computational and physical resources [19]. This article outlines a systematic framework for selecting and optimizing high-throughput workflows to maximize the return on computational investment (ROCI) without compromising data quality, enabling researchers to navigate the inherent trade-offs between speed, cost, and accuracy [19].
Core Principles of the Optimal Workflow Selection Framework
The proposed framework is built on a two-stage selection process designed to efficiently navigate the vast space of possible workflows [1].
Stage 1: Fast Search for High-Quality Workflows
The first stage involves a rapid screening of user-defined possible workflows to quickly filter for those capable of generating high-quality information relevant to the established objective. This broad search prioritizes identification of workflows with the fundamental potential for success.
Stage 2: Fine Search for the Highest-Value Workflow
The second stage performs a more rigorous, fine-grained evaluation of the shortlisted high-quality workflows from Stage 1. The goal is to select the single optimal workflow that generates the highest-value information, as defined by a user-specified objective function, such as maximizing ROCI [1] [19].
Table 1: Key Performance Indicators for Benchmarking Workflows
| Key Performance Indicator | Definition | Impact on Autonomous Experimentation |
|---|---|---|
| Throughput Speed | The number of experimental iterations or data points processed per unit time. | A 5x faster throughput enables significantly faster model iteration cycles [20]. |
| Data Quality & Accuracy | Measured by error rates, signal-to-noise ratio, or conformity to ground-truth data. | A 30% increase in annotation accuracy can directly translate to a 15% improvement in downstream task performance (e.g., robotic grasping precision) [20]. |
| Cost per Experiment | The total resource expenditure (computational, material, time) per experimental unit. | Intelligent data selection and automation can reduce dataset annotation requirements by 35% and cut associated costs by over 33% [20]. |
| Automation Capability | The degree to which the workflow can operate with minimal human intervention. | Hybrid AI-human workflows reduce repetitive manual effort and can lead to a 60-95% reduction in time spent on repetitive tasks [20] [21]. |
Quantitative Metrics for Workflow Benchmarking
To implement the framework, workflows must be benchmarked using quantifiable metrics. The following table summarizes critical metrics for evaluating workflow performance in the context of autonomous experimentation.
Table 2: Workflow Performance Metrics from Real-World Case Studies
| Experimental Domain | Metric Category | Baseline Performance | Optimized Performance | Key Enabling Factor |
|---|---|---|---|---|
| Materials Characterization (BSE-SEM) [1] | Collection Time | Benchmark Workflow | 5x reduction vs. benchmark | Optimal HTVS workflow selection |
| Computer Vision Data Labeling [20] | Data Throughput | Legacy Annotation Platform | 5x improvement | AI-assisted pre-labeling (e.g., SAM2) |
| Computer Vision Data Labeling [20] | Project Setup Time | Legacy Platform (2 months) | 4x faster (2 weeks) | User-friendly interfaces & workflow templates |
| Robotic Grasping Precision [20] | Task Accuracy | Outsourced Labeling | 15% boost | High-precision data pipeline & nested ontologies |
| Business Process Automation [21] | Repetitive Task Time | Manual Execution | 60-95% reduction | Workflow automation software |
Figure 1: The two-stage Optimal Workflow Selection Framework. This process systematically moves from a broad set of user-defined workflows to the selection of a single, optimal workflow designed to maximize Return on Computational Investment (ROCI) [1] [19].
Experimental Protocols for Workflow Implementation
Protocol: Deployment of a Hybrid AI-Human Labeling Workflow
This protocol is adapted from successful implementations in computer vision for physical AI and robotics [20].
4.1.1 Research Reagent Solutions
- AI-Assisted Labeling Platform (e.g., Encord): A platform integrating models like SAM2 for smart pre-labeling. Its function is to automate repetitive annotation tasks, drastically reducing manual effort [20].
- Nested Ontology Management System: A structured hierarchy of labels and classes. Its function is to ensure labeling consistency and accuracy for complex objects [20].
- Analytics Dashboard: A real-time monitoring tool. Its function is to track annotator throughput, label accuracy, and project progress [20].
4.1.2 Step-by-Step Procedure
- Workflow Setup: Import raw data and configure the nested ontology within the labeling platform. Define project-specific guidelines.
- AI Pre-labeling: Run the AI-assisted labeling model to generate initial annotations on the entire dataset.
- Human-in-the-Loop Review: Direct human annotators to review and correct AI-generated labels, focusing on complex edge cases and low-confidence model predictions.
- Quality Assurance: Implement a review pipeline where a second annotator or project lead audits a subset of corrected labels.
- Model Retraining: Use the human-corrected labels to fine-tune the AI pre-labeling model, creating a feedback loop for continuous improvement.
4.1.3 Expected Outcomes: Following this protocol can result in a 5x improvement in data throughput, a 30-35% reduction in labeling costs, and a significant increase in annotation accuracy, as demonstrated by companies like Pickle Robot [20].
Protocol: Bayesian Optimization for Medium Conditioning in Bioproduction
This protocol is adapted from an autonomous lab system used to optimize medium conditions for a glutamic acid-producing E. coli strain [22].
4.2.1 Research Reagent Solutions
- Modular Autonomous Lab System: A system comprising culturing, preprocessing, and analysis modules. Its function is to autonomously execute a closed loop from culture to analysis [22].
- Bayesian Optimization Algorithm: A machine learning algorithm. Its function is to model the relationship between input parameters and objective variables to intelligently suggest the next best experiment [22].
- M9 Minimal Medium: A defined growth medium. Its function is to serve as a base for optimization, allowing for the exclusive quantification of target metabolites without background interference [22].
4.2.2 Step-by-Step Procedure
- Initial Dataset Construction: Conduct a preliminary experiment to measure objective variables against a wide range of component concentrations.
- Algorithmic Setup: Input the initial dataset into the Bayesian optimization algorithm, defining the objective variables.
- Autonomous Experimentation Loop: a. The algorithm proposes the next set of component concentrations to test. b. The autonomous lab system prepares the medium, cultures the cells, and measures the outcomes. c. The new data is fed back into the algorithm.
- Iteration: Repeat Step 3 until a convergence criterion is met or the objective is satisfactorily achieved.
4.2.3 Expected Outcomes: This protocol allows an autonomous system to efficiently navigate a complex multi-parameter space to find optimal conditions for cell growth or product yield, significantly accelerating the bioproduction strain development process [22].
Figure 2: The Autonomous Experimentation Loop. This workflow, powered by Bayesian optimization, enables closed-loop, high-throughput experimentation for domains like bioproduction [22].
The Scientist's Toolkit: Essential Research Reagents & Materials
The following table details key solutions and materials essential for implementing high-throughput workflows in autonomous experimentation.
Table 3: Essential Research Reagent Solutions for Autonomous Experimentation
| Tool Category | Specific Tool Example | Function in Workflow |
|---|---|---|
| No-Code Data Automation | Mammoth Analytics [23] | Provides an intuitive, drag-and-drop interface for cleaning and analyzing large datasets without coding, enabling non-technical researchers to automate data pipelines. |
| AI-Powered Data Labeling | Encord [20] | Integrates AI models for pre-labeling data (e.g., with SAM2), reducing manual annotation effort by up to 75% and accelerating the creation of training data for machine learning. |
| Cloud-Based Workflow Automation | CloudPipe [23] | Offers a serverless, pay-per-use architecture for running data workflows, providing auto-scaling capabilities and minimizing infrastructure management overhead. |
| Modular Autonomous Lab Hardware | Autonomous Lab (ANL) System [22] | A system of modular, movable devices for culturing, preprocessing, and analysis that can be reconfigured for different biological experiments. |
| Bayesian Optimization Software | Custom Algorithm [22] | Models the relationship between experimental parameters and outcomes to intelligently propose the next highest-value experiment, maximizing the efficiency of resource allocation. |
The Framework for Optimal Workflow Selection provides a systematic, value-driven methodology for designing and operating high-throughput experimental pipelines. By moving beyond static, human-designed workflows and adopting a dynamic, metrics-based approach, researchers can significantly accelerate their ROCI. The integration of hybrid AI-human workflows and Bayesian optimization loops, as demonstrated in the accompanying protocols, offers a tangible path toward more efficient, reliable, and scalable autonomous experimentation in scientific research and drug development.
The adoption of high-throughput experimentation (HTE) in pharmaceutical research marks a paradigm shift towards autonomous experimentation, enabling the rapid exploration of complex biological and chemical spaces. This article details practical applications and standardized protocols for two transformative automation technologies: a fully automated workflow for 3D cell culture and the CHRONECT XPR system for automated solid dosing. These case studies provide a framework for researchers selecting and implementing high-throughput workflows, highlighting measurable gains in reproducibility, efficiency, and data quality essential for autonomous research pipelines.
Case Study: Fully Automated 3D Midbrain Organoid Generation & Screening
Application Note
The manual generation and analysis of complex 3D cell cultures, such as organoids, present significant challenges for reproducible, high-throughput screening. A fully automated workflow was developed to address this, enabling the production of highly homogeneous human midbrain organoids in a standard 96-well format [24]. This integrated system automates the entire process from generation to high-content analysis.
Key quantitative outcomes from the automated workflow demonstrate its precision and robustness [24]:
Table 1: Performance Metrics of Automated Organoid Workflow
| Performance Metric | Result | Implication for HTE |
|---|---|---|
| Sample Retention (over 30 days) | 99.7% (SD ± 0.7%) | Enhanced reliability and reduced material waste in long-term studies. |
| Post-Analysis Sample Retention | 96.5% (SD ± 3.1%) | High process stability for complex, multi-step protocols. |
| Sample Rejection Rate (Imaging) | 6.1% (SD ± 1.3%) | Low incidence of imaging artifacts, ensuring high-quality data output. |
| Intra-batch Size Variability (CV) | 3.56% (min 2.2%, max 5.6%) | Exceptional morphological homogeneity, critical for screening consistency. |
This workflow allows for assessing drug effects at single-cell resolution within a complex 3D environment, providing a more physiologically relevant model for neurodegenerative diseases like Parkinson's disease in a scalable, HTS-compatible format [24].
Experimental Protocol
Aim: To generate, maintain, and analyze homogeneous human midbrain organoids in a fully automated, high-throughput manner. Starting Material: Small molecule neural precursor cells (smNPCs) derived from pluripotent stem cells [24].
Key Methodological Details:
- Automation Platform: All steps are performed using an Automated Liquid Handling System (ALHS) with a 96-channel pipetting head [24].
- Culture Format: Organoids are generated and maintained one-per-well in standard 96-well plates to minimize batch effects from paracrine signaling, unless such signaling is desired [24].
- Critical Omission: The protocol intentionally omits Matrigel embedding to reduce batch-to-batch variability [24].
- Quality Control: The workflow includes automated steps for fixation, whole-mount immunostaining, and tissue clearing, culminating in high-content imaging that provides quantitative data at the single-cell level [24].
Case Study: Automated Powder Dispensing with CHRONECT XPR
Application Note
In pharmaceutical development, accurate and reproducible handling of solid materials is a major bottleneck. Manual weighing of powders, especially in the milligram range, is time-consuming and prone to human error. The CHRONECT XPR workstation is an integrated system designed to fully automate powder dosing and subsequent liquid addition, enabling high-throughput experimentation for applications like formulation development and compound library management [25] [26] [27].
Table 2: Technical Specifications of the CHRONECT XPR Workstation
| Feature | Specification | Benefit for Pharmaceutical HTE |
|---|---|---|
| Dosing Precision | Sub-milligram to several grams [26] | Reduces variability, increases reproducibility for sensitive assays. |
| Powder Handling Capacity | Up to 32 different powders per run [26] | Enables many-to-many formulation strategies from many starting materials [25]. |
| Vial Handling | Automatic decapping, sealing, and transfer of 1 mL to 20 mL vials [26] | Minimizes manual intervention and exposure to hazardous compounds. |
| Software & Traceability | Chronos software; RFID tracking of dosing heads [26] | Ensures data integrity, full traceability, and integration with LIMS. |
| Footprint | Compact, benchtop design [26] | Fits into standard lab spaces or safety cabinets. |
This system enhances productivity by automating repetitive tasks such as capping, vortexing, and liquid addition, freeing valuable scientist time for data analysis and experimental design [26].
Experimental Protocol
Aim: To perform automated, precise dispensing of multiple solid powders and prepare them for subsequent liquid addition and reaction. Starting Materials: Up to 32 different powder compounds; appropriate solvent vials [26].
Key Methodological Details:
- Dosing Principle: The system uses gravimetric dosing, leveraging a high-precision balance isolated from environmental vibration for maximum accuracy [26].
- Workflow Integration: The CHRONECT XPR platform follows a "many-to-many" approach, allowing numerous formulations to be created from many starting materials quickly and reproducibly without manual interaction [25].
- Operational Environment: The system can support inert gas environments for the safe handling of oxygen- or moisture-sensitive compounds [26].
- Software Control: The Chronos software provides intuitive, sample-based control without the need for complex robot programming, facilitating integration with existing data management systems [26].
The Scientist's Toolkit: Essential Research Reagent Solutions
The successful implementation of the aforementioned automated workflows relies on a suite of specialized materials and equipment.
Table 3: Essential Materials for Automated HTE in Pharmaceuticals
| Item | Function/Description | Example in Use |
|---|---|---|
| Automated Liquid Handler | A robotic system for precise, high-volume liquid transfers. | Pipetting medium changes and reagents in 3D organoid workflow [24]. |
| Robotic Powder Dispenser | A system for accurate, hands-free dispensing of solid materials. | CHRONECT XPR for sub-milligram solid dosing [26] [27]. |
| High-Content Imaging System | An automated microscope with analytical software for detailed cellular analysis. | Quantitative whole-mount analysis of organoids with single-cell resolution [24]. |
| Standard Multi-Well Plates | Industry-standard plasticware for cell culture and assays. | 96-well plates used for organoid generation and screening [24]. |
| Specialized Cell Culture Media | Chemically defined media supporting specific cell types and 3D growth. | Differentiation and maintenance of midbrain organoids [24]. |
| Tissue Clearing Reagents | Chemical solutions that render biological samples optically transparent. | Enabling deep imaging of whole, intact organoids [24]. |
| Primary & Secondary Antibodies | For specific detection of proteins via immunostaining. | Characterizing protein expression and cellular composition in organoids [24]. |
| Laboratory Information Management System (LIMS) | Software for tracking samples and experimental data. | Integrating with Chronos software for complete data traceability [26]. |
Leveraging Low-Code Platforms and Modular Systems for Accessible Workflow Design
The paradigm of scientific research, particularly in fields like chemistry and drug development, is shifting from manual, sequential experimentation towards autonomous, high-throughput systems. This transition is largely driven by the integration of two powerful concepts: low-code platforms for orchestrating complex decision-making and modular systems for physical execution. Together, they create a framework for accessible workflow design that accelerates the cycle of hypothesis, experimentation, and analysis.
Low-code workflow automation uses visual tools and pre-built components to automate processes with minimal manual coding, making powerful automation accessible to researchers who are domain experts but not necessarily software developers [28] [29]. This agility is critical for Autonomous Experimentation (AE) systems, defined as iterative research loops of planning, experiment, and analysis carried out autonomously [1]. When combined with modular hardware systems—discrete, interchangeable units for tasks like synthesis, purification, and analysis—these digital platforms enable the creation of robust, self-driving laboratories (SDLs) capable of rapidly exploring vast experimental spaces [30] [6].
Core Concepts and Definitions
Low-Code/No-Code Platforms
- Low-Code Platform: A software development environment that enables the creation of applications and workflows through visual interfaces, drag-and-drop components, and configuration, significantly reducing the need for hand-written code [28] [31]. They offer more flexibility than no-code platforms but have a steeper learning curve [29].
- No-Code Platform: A subset of low-code platforms that allows users with no coding experience to build applications and automate processes entirely through visual tools [28].
- Citizen Developer: A business user or, in this context, a researcher with domain expertise but limited formal coding skills, who is empowered to create and manage automated workflows [28] [29].
Modular Systems in Science
- Modular Bioprocessing Platform: A system composed of discrete, interchangeable units (modules) engineered for integration, rapid deployment, and scalability. Instead of rebuilding for every new product, operators mix and match modules, building on a flexible backbone [30].
- Self-Driving Lab (SDL): A system that combines robotic automation with artificial intelligence (AI) to conduct high-throughput scientific experiments with minimal human intervention [32] [6].
The Workflow Selection Framework
A critical process for AE systems involves selecting the optimal data collection workflow. This can be framed as [1]: Workflow → Information → Value The value of the information generated is proportional to its Quality and Actionability. A well-designed workflow generates high-quality, actionable information that adds significant value to the broader scientific objective.
Quantitative Comparison of Enabling Technologies
The following tables summarize key low-code platforms and modular system components relevant to autonomous research.
Table 1: Comparison of Low-Code Automation Platforms for Scientific Workflows
| Platform | Primary Use Case | Technical Proficiency Required | Key Strengths | Scalability & Governance |
|---|---|---|---|---|
| Vellum AI [33] | AI-native workflow orchestration | Low (No-code prompting) | Built-in evaluations, versioning, AI-native primitives (retrieval, semantic routing) | Strong versioning, dev/stage/prod environments, RBAC, VPC/on-prem deployment |
| Appian [34] | Enterprise process automation | Medium (Steeper learning curve) | Powerful BPMN-compliant process modeling, deep legacy system integration, high-security standards | Enterprise-grade, ideal for regulatory-heavy industries (finance, healthcare) |
| AppSheet [34] | Data-driven internal apps | Low (Business-user-friendly) | Quick deployment for internal tools, integrates with Google Sheets/Excel, offline functionality | Scalable via Google Workspace SSO & permissions |
| OutSystems [35] | Enterprise-grade application development | Medium (Basic coding knowledge) | High scalability, built-in support for microservices and containers, versatile for various app types | Scalable for all application sizes, strong security and governance features |
| n8n [33] | Technical workflow automation | High (Developer-focused) | Open-source/self-host option, flexible for technical teams | Self-hosted option provides control, suitable for technical teams |
Table 2: Typical Modules in a Modular Bioprocessing or SDL Platform [30]
| Module Type | Core Function | Scale Options | Example Research & Development Use Cases |
|---|---|---|---|
| Upstream Processing | Sterile growth of cells/microbes | Pilot to Large Scale | Vaccine cell culture, fermentation for bio-therapeutics |
| Downstream Processing | Purification and isolation of products | Bench to Production | Protein harvest, enzyme extraction, purification of synthesized compounds |
| Formulation/Fill | Final product preparation | Lab to Commercial | Sterile vial filling for drug candidates, media blends |
| Quality Control (QC) | Real-time analytics and sampling | Any Scale | On-line monitoring (e.g., pH, metabolites), release testing for product quality |
| Synthesis | Chemical reaction execution | Micro-scale to Production | Solid-state synthesis, organic molecule construction, nanoparticle fabrication |
Application Notes: Implementation in Autonomous Research
Enabling Closed-Loop Experimentation
The core of an SDL is the closed-loop cycle, where AI plans an experiment, robotics execute it, data is analyzed, and results inform the next AI-driven decision [6]. Low-code platforms act as the orchestration layer that manages this cycle, while modular systems provide the physical means. For instance, a platform like Vellum can manage a workflow that involves a mobile robot transporting a sample from a synthesis module (e.g., Chemspeed ISynth) to an analysis module (e.g., UPLC-MS or benchtop NMR), then process the analytical data to decide the next experimental step [6].
Enhancing Robustness with Real-Time Inspection
A significant challenge in SDLs is that robotic manipulation often operates in an open-loop, assuming flawless execution. Integrating vision-based inspection modules like LIRA (Localization, Inspection, and Reasoning) can close this loop. LIRA uses Vision-Language Models (VLMs) to provide real-time error detection and correction [32]. A low-code workflow can be designed to trigger a LIRA inspection at critical points, such as after a robot attempts to place a vial into an NMR spectrometer. If LIRA detects a misalignment, it can signal the workflow to execute a recovery procedure before proceeding, thereby preventing failed experiments and instrument damage.
Facilitating Rapid Prototyping and Scale-Up
Modular platforms allow a research team to start with a small-scale upstream processing module for initial discovery and optimization. Once a promising candidate is identified (e.g., a new therapeutic enzyme), the workflow can be seamlessly scaled by integrating larger-capacity upstream and downstream processing modules without a complete system redesign [30]. A low-code workflow automating the process at the small scale can often be adapted and replicated to control the larger-scale system, dramatically reducing process development time.
Experimental Protocols
Protocol: Automated Workflow for High-Throughput Material Characterization
This protocol is adapted from the A-Lab and LIRA frameworks for autonomous solid-state materials characterization [32] [6].
I. Objective To autonomously synthesize and characterize a set of proposed inorganic materials, using computer vision for error recovery and active learning to improve synthesis recipes.
II. Research Reagent Solutions & Essential Materials Table 3: Key Materials for Autonomous Solid-State Synthesis Workflow
| Item | Function / Rationale |
|---|---|
| Precursor Powders | (e.g., Metal oxides, carbonates). Starting materials for solid-state reactions. |
| Mortar and Pestle | For manual or automated grinding and mixing of precursor powders. |
| Ceramic Crucibles | Containers for powder reactions; must withstand high-temperature furnaces. |
| High-Temperature Furnace | Module for heating powder mixtures to induce solid-state reaction and crystallization. |
| X-ray Diffractometer (XRD) | Analysis module for determining the crystalline phase of the synthesized product. |
| Mobile Robot with Robotic Arm | For transporting samples between workstations (e.g., from furnace to XRD). |
| Fiducial Markers (e.g., ArUco) | Visual markers used by the LIRA module for precise robot localization in 3D space [32]. |
| Vision-Language Model (VLM) | AI model fine-tuned on chemistry lab images for real-time visual inspection and reasoning [32]. |
III. Methodology
- Workflow Initialization:
- The AI planner (e.g., trained on materials data from the Materials Project) provides a list of target materials and initial synthesis recipes.
- The low-code workflow platform (e.g., Vellum, n8n) receives the first target and its recipe.
Sample Preparation & Synthesis:
- The workflow platform directs the robotic system to a weighing and mixing station.
- Precursors are dispensed and mixed according to the recipe.
- The mixture is transferred to a crucible.
- The mobile robot navigates to the furnace module and places the crucible inside.
- The furnace heats the sample according to the recipe-specified temperature and duration.
Post-Synthesis Inspection (LIRA Integration):
- After synthesis, the robot retrieves the crucible and moves to a predefined imaging position.
- The low-code workflow triggers the LIRA inspection client. A prompt such as "Inspect the crucible for spillage or cracking" is sent with a camera image [32].
- LIRA's VLM server processes the request and returns a result (e.g., "No errors detected").
- Based on the result, the
InspectionHandlerin the workflow decides the next step (proceed to characterization or initiate error recovery).
Material Characterization & Data Analysis:
- The robot transports the sample to the XRD module for phase identification.
- The XRD pattern is collected and analyzed by a machine learning model (e.g., a convolutional neural network) to identify the present phases and estimate yield [6].
- The analysis results are fed back to the AI planner.
Closed-Loop Learning & Iteration:
- If the synthesis was unsuccessful or the yield was low, the AI planner (e.g., using Bayesian optimization or an active learning algorithm) uses the data to propose a modified synthesis recipe for the same target.
- The low-code workflow platform manages this iterative loop, initiating a new synthesis with the updated recipe until the target is successfully synthesized or a termination criterion is met.
- The workflow then proceeds to the next target material on the list.
Protocol: Autonomous Exploration of Reaction Conditions
This protocol is based on modular systems using mobile robots for synthetic chemistry [6].
I. Objective To autonomously screen and optimize reaction conditions for a given organic synthesis, using heuristic analysis of orthogonal analytical data (MS and NMR) to guide the exploration.
II. Methodology
- Workflow Setup in Low-Code Platform:
- A workflow is built to coordinate a Chemspeed ISynth synthesizer, a UPLC-MS, a benchtop NMR, and mobile transport robots.
- The workflow defines the decision logic based on a heuristic reaction planner that assigns a "pass" or "fail" to MS and NMR results [6].
Reaction Execution:
- The mobile robot delivers starting materials to the synthesizer module.
- The synthesizer executes the reaction under a set of initial conditions (e.g., solvent, temperature, catalyst).
Analysis and Decision Making:
- The robot transports the reaction mixture to the UPLC-MS for analysis.
- The MS data is analyzed (e.g., using a precomputed m/z lookup table). The result is passed to the heuristic planner within the workflow.
- If the MS result is a "pass," the workflow may direct the robot to transport the sample to the NMR for further structural confirmation.
- The heuristic planner processes both MS and NMR data (using techniques like dynamic time warping to detect changes) to make a human-like judgment on the reaction's success [6].
Multi-Campaign Workflow:
- Based on the decision, the workflow autonomously branches into different campaigns:
- Screening: Tests new reaction conditions.
- Replication: Repeats promising reactions for verification.
- Scale-up: Scales a successful reaction.
- Functional Assays: Subjects a successful product to further biological or chemical testing.
- This entire multi-day exploration runs autonomously, guided by the workflow's logic.
- Based on the decision, the workflow autonomously branches into different campaigns:
Workflow Visualization
The following diagram, generated using Graphviz DOT language, illustrates the integrated closed-loop workflow for autonomous experimentation, highlighting the synergy between the low-code digital orchestrator and the modular physical systems.
The integration of High-Throughput Experimentation (HTE) specialists with domain scientists, such as medicinal chemists, is a critical success factor for modern autonomous experimentation research. This collaborative model moves beyond a traditional service-led approach, fostering a cooperative environment that significantly accelerates discovery cycles and enhances innovation [36]. In pharmaceutical research, this integration has proven particularly valuable, enabling teams to tackle complex, multidimensional optimization challenges that are common in drug development [36] [37]. The synergy between specialized HTE knowledge and deep domain expertise creates a powerful framework for addressing the pressing challenges of modern scientific discovery, from catalyst design to radiochemistry optimization [37] [38]. Effective cross-functional collaboration leverages diverse skills, expertise, and working styles, which contributes to a more comprehensive understanding of problems and increases the likelihood of reaching optimal solutions [39].
Quantitative Benefits of Integration
Data from implemented cross-functional teams demonstrates substantial improvements in research efficiency and output. The following table summarizes key performance metrics observed after successful integration of HTE specialists with domain scientists:
Table 1: Measured Performance Improvements from HTE Integration
| Metric | Pre-Integration Performance | Post-Integration Performance | Timeframe |
|---|---|---|---|
| Average Screen Size [36] | ~20-30 reactions per quarter | ~50-85 reactions per quarter | 6-7 quarters post-implementation |
| Conditions Evaluated [36] | <500 conditions per quarter | ~2000 conditions per quarter | 6-7 quarters post-implementation |
| Weighing Time per Vial [36] | 5-10 minutes manually | <30 minutes for entire 96-well plate (automated) | Case study |
| Powder Dosing Accuracy [36] | Significant human error at small scales | <10% deviation (sub-mg); <1% deviation (>50 mg) | Case study |
These quantitative improvements are complemented by qualitative benefits observed in cross-functional settings, including enhanced innovation, more comprehensive problem-solving, and reduced handoff delays [39]. The colocation of HTE specialists with medicinal chemists at AstraZeneca's oncology departments in Boston and Cambridge, for instance, was specifically noted as "highly beneficial to the HTE model within Oncology, enabling a co-operative rather than service-led approach" [36].
Implementation Protocol
Successful implementation requires careful planning and execution. The following protocol outlines a systematic approach for establishing effective cross-functional teams integrating HTE specialists with domain scientists.
Preparation Phase (Weeks 1-4)
3.1.1 Team Composition and Goal Definition
- Identify Team Members: Form a core team comprising HTE specialists (2-3), domain scientists (3-4), and a project manager with cross-functional experience [39]. HTE specialists should bring expertise in automation, robotics, and data analysis, while domain scientists contribute subject matter expertise (e.g., medicinal chemistry, radiochemistry) [36] [37].
- Define Objectives and KPIs: Clearly articulate primary objectives (e.g., "increase reaction screening throughput by 50% within 6 months") and establish key performance indicators aligned with project goals [39]. These should include both output metrics (reactions per quarter) and outcome metrics (successful candidate identification).
3.1.2 Infrastructure Assessment
- Evaluate Physical Workspace: Ensure collocation of team members in shared laboratory and office spaces to facilitate spontaneous interaction and knowledge sharing [36].
- Audit HTE Capabilities: Assess existing automation equipment (liquid handlers, powder dosing systems), analytical instrumentation, and data infrastructure. The CHRONECT XPR system for powder dispensing has demonstrated particular utility in pharmaceutical HTE applications [36].
Execution Phase (Weeks 5-12)
3.2.1 Workflow Integration Protocol
- Conduct Joint Workflow Mapping Sessions: Document current experimental processes from both HTE and domain science perspectives, identifying integration points and potential bottlenecks.
- Develop Standard Operating Procedures (SOPs): Create detailed protocols for parallel reaction setup, automated solid and liquid handling, and rapid analysis techniques. For radiochemistry applications, this includes specific procedures for handling short-lived isotopes [37].
- Implement Collaborative Analysis Framework: Establish regular data review sessions (2-3 times weekly) where HTE specialists and domain scientists jointly interpret results and plan subsequent experiments.
Table 2: Essential Research Reagent Solutions for HTE Integration
| Reagent Category | Specific Examples | Function in HTE Workflow |
|---|---|---|
| Catalyst Libraries [36] | Transition metal complexes, organocatalysts | Enable rapid screening of catalytic reactions across diverse chemical space |
| Building Block Sets [36] | (Hetero)aryl boronate esters, diverse pharmacophores | Provide chemical diversity for library synthesis and reaction scope investigation |
| Solvent/Additive Systems [37] | Pyridine, n-butanol in CMRF optimization | Modulate reaction conditions to enhance yields and selectivity |
| Radioisotope Reagents [37] | [18F]fluoride for PET tracer development | Serve as limiting reagents in radiochemistry optimization studies |
3.2.2 Cross-Training Initiative
- HTE Fundamentals for Domain Scientists: Provide 3-5 training sessions covering automation capabilities, experimental design constraints, and data generation workflows.
- Domain Introduction for HTE Specialists: Conduct 2-3 sessions on relevant scientific context, key challenges in the domain, and critical parameters for success.
Optimization Phase (Months 4-6)
3.3.1 Process Refinement
- Establish Regular Retrospectives: Conduct bi-weekly team meetings to discuss collaboration challenges, communication gaps, and workflow inefficiencies.
- Implement Iterative Refinement: Use feedback from retrospectives to adjust protocols, communication channels, and resource allocation.
3.3.2 Performance Monitoring
- Track Quantitative Metrics: Monitor screening throughput, reaction success rates, and cycle times compared to pre-integration baselines.
- Assess Qualitative Factors: Evaluate team satisfaction, communication effectiveness, and problem-solving capabilities through anonymous surveys.
Collaborative Workflow Architecture
The integrated workflow between HTE specialists and domain scientists follows a structured yet iterative process that enables continuous optimization. The diagram below illustrates this collaborative workflow:
This workflow emphasizes the critical collaboration points where HTE specialists and domain scientists must coordinate most closely, particularly during joint data analysis and iteration decisions. The integration of artificial intelligence and machine learning algorithms at the analysis stage can further enhance this collaborative process by providing data-driven insights for optimization [6] [38].
Team Composition and Roles
Effective cross-functional collaboration requires clear definition of responsibilities and expertise areas. The following table outlines the complementary roles in an integrated HTE-domain science team:
Table 3: Cross-Functional Team Composition and Responsibilities
| Role | Core Expertise | Primary Responsibilities | Collaboration Points |
|---|---|---|---|
| HTE Specialist [36] | Automation systems, robotics programming, high-throughput data analysis | Design and execute parallel experiments, maintain automated platforms, ensure data quality | Protocol development, results interpretation, troubleshooting technical issues |
| Domain Scientist [36] [37] | Medicinal chemistry, radiochemistry, specific application knowledge | Define scientific objectives, select target compounds, interpret results in domain context | Experimental design, data prioritization, result validation |
| Project Manager [39] | Cross-functional coordination, timeline management, conflict resolution | Facilitate communication, track milestones, allocate resources, remove blockers | All team interactions, stakeholder reporting, resource negotiation |
This team structure deliberately breaks down traditional silos, creating a cooperative environment where "team members can brainstorm ideas, challenge conventional thinking, and develop novel solutions that might not be possible in teams with a more limited focus" [39].
Challenges and Mitigation Strategies
While the benefits of integration are significant, several challenges commonly arise in cross-functional team implementation:
- Communication Barriers: Differences in technical jargon and work approaches between specialists and domain scientists can cause friction [39]. Mitigation includes establishing a shared glossary of terms and implementing structured communication protocols.
- Resource Allocation Conflicts: Team members often report to different departmental managers, creating competing priorities [39]. This can be addressed through clear reporting structures and shared performance metrics aligned with collaborative goals.
- Resistance to Change: Specialists from both domains may be uncomfortable leaving traditional working styles [39]. Gradual implementation with strong leadership support and early demonstration of success can help overcome this resistance.
The integration of HTE specialists with domain scientists represents a powerful organizational model for accelerating research in autonomous experimentation environments. By following structured implementation protocols and establishing clear collaborative workflows, research organizations can achieve significant improvements in throughput, efficiency, and innovation capacity.
Hyperautomation is a business-driven discipline that orchestrates multiple technologies to rapidly identify, vet, and automate as many business and IT processes as possible [40]. It represents an evolutionary step beyond traditional automation by integrating complementary technologies including Robotic Process Automation (RPA), artificial intelligence (AI), machine learning (ML), process mining, and analytics to create end-to-end automated processes [41] [42] [43]. Within the context of high-throughput autonomous experimentation for drug development and materials research, hyperautomation provides the framework to transform fragmented, manual workflows into integrated, intelligent systems capable of autonomous decision-making and optimization.
The core premise of hyperautomation is moving beyond automating individual tasks to optimizing entire operational processes. In scientific research, this means creating a seamless flow from experimental planning through execution, data collection, analysis, and iterative hypothesis refinement. This approach is particularly valuable for autonomous experimentation systems, which require dynamic workflow selection and execution to efficiently navigate complex experimental spaces [1].
Core Technological Components of Hyperautomation
The Hyperautomation Technology Stack
Hyperautomation relies on the orchestrated integration of several core technologies, each playing a distinct role in creating intelligent automated systems:
Robotic Process Automation (RPA): Serves as the foundational layer, automating repetitive, rule-based tasks by mimicking human interactions with digital systems [43]. In research environments, RPA can handle data entry, instrument control, and report generation tasks.
Artificial Intelligence and Machine Learning: Enable systems to handle unstructured data, make predictions, and adapt to new information [41]. ML algorithms can predict drug efficacy and toxicity, analyze large datasets to identify patterns, and suggest new experimental directions [44].
Process Mining and Discovery: Tools automatically analyze digital footprints to identify processes suitable for automation, providing detailed views of operational activities and highlighting bottlenecks and improvement areas [41].
Intelligent Document Processing (IDP): Leverages AI and ML to automate processing complex documents, extracting, classifying, validating, and integrating data from unstructured sources [41].
Integration Technologies (APIs and iPaaS): Provide the connectivity backbone, enabling different systems, instruments, and software platforms to communicate seamlessly [41].
The Relationship Between Hyperautomation Components
The following diagram illustrates how these technologies interact within a hyperautomation framework:
Hyperautomation Technology Integration
Hyperautomation for High-Throughput Workflow Selection
A Framework for Autonomous Workflow Selection
In autonomous experimentation research, hyperautomation enables the implementation of sophisticated frameworks for selecting optimal data collection workflows. Niezgoda et al. (2022) proposed a systematic approach where autonomous systems dynamically identify high-value workflows based on user-defined objectives [1]. This framework operates on the principle that a well-designed Workflow generates relevant Information that delivers measurable Value, with value being proportional to information quality and actionability [1].
The framework implements a two-stage selection process:
- Fast Search: Rapidly filters possible workflows to identify high-quality candidates
- Fine Search: Selects the optimal workflow from high-quality candidates based on specific value metrics [1]
Implementation in Materials Characterization
In a case study applying this framework to materials characterization, researchers achieved an 85-fold reduction in data collection time for backscattered electron scanning electron microscopy (BSE-SEM) images compared to previously published methods [1]. The autonomous system leveraged deep-learning based image denoising to identify workflows that maintained information quality while dramatically accelerating throughput.
Table 1: Workflow Performance Comparison in Materials Characterization Case Study
| Workflow Type | Data Collection Time | Information Quality | Speed Improvement |
|---|---|---|---|
| Traditional Workflow (Previous Study) | Reference (100%) | Baseline | 1x |
| Ground-Truth Benchmark | 20% of traditional | Equivalent to baseline | 5x |
| AI-Optimized Workflow | 1.2% of traditional | Equivalent to baseline | 85x |
Application Notes: Hyperautomation in Drug Discovery
Accelerating Drug Discovery and Development
The pharmaceutical industry has emerged as a prime beneficiary of hyperautomation technologies, with the FDA's Center for Drug Evaluation and Research (CDER) reporting a significant increase in drug application submissions incorporating AI components [45]. Hyperautomation enables several critical improvements in drug discovery:
Enhanced Predictive Modeling: AI and ML algorithms can predict drug efficacy and toxicity with greater accuracy than traditional methods by analyzing large datasets of known compounds and their properties [44]. Deep learning models have demonstrated high accuracy in predicting the biological activity of novel compounds [44].
Accelerated Compound Design: AI-based approaches enable rapid design of novel compounds with specific properties and activities, moving beyond the slow, labor-intensive process of modifying existing compounds [44]. DeepMind's AlphaFold represents a breakthrough in predicting protein structures, significantly advancing target identification and drug design capabilities [44].
Streamlined Clinical Operations: Hyperautomation orchestrates complex processes across clinical operations, from patient recruitment and monitoring to data collection and regulatory reporting [45].
Quantitative Benefits in Pharmaceutical Applications
Table 2: Hyperautomation Impact Metrics in Drug Discovery and Development
| Application Area | Reported Improvement | Key Technologies | Data Source |
|---|---|---|---|
| Financial Operations (Lyft) | 50% reduction in time to close revenue books | RPA, Process Automation | [46] |
| Financial Operations (Lyft - Projected) | 75% reduction in full financial close time | RPA, Process Automation | [46] |
| Supply Chain Reconciliation (Chipotle) | Millions of dollars annually saved | Automated tracking, forecasting | [46] |
| Toxicity Prediction | High accuracy using large compound databases | Machine Learning | [44] |
| Drug-Drug Interaction Prediction | Accurate identification of novel drug pairs | Machine Learning | [44] |
Experimental Protocols for Autonomous Experimentation
Protocol: Implementation of Autonomous Workflow Selection Framework
Objective: To enable autonomous experimentation systems to dynamically select optimal data collection workflows for materials characterization or drug discovery applications.
Materials and Equipment:
- Automated instrumentation (e.g., SEM, HPLC, robotic synthesizers)
- Data processing infrastructure with ML capabilities
- Workflow management software platform
- Integration middleware (iPaaS)
Procedure:
Objective Definition Phase
- Define quantifiable experimental objectives and constraints
- Establish value function incorporating information quality, actionability, and cost metrics [1]
Workflow Space Characterization
- Catalog available experimental procedures, methods, and models
- Define parameter spaces for each workflow component
- Establish quality metrics for output information
Fast Search Implementation
- Execute broad screening of possible workflow combinations
- Apply constraints to eliminate non-viable workflows
- Identify candidate workflows meeting minimum quality thresholds [1]
Fine Search Optimization
- Execute detailed evaluation of high-quality candidate workflows
- Apply multi-objective optimization to maximize value function
- Select optimal workflow based on user-defined priorities [1]
Execution and Validation
- Implement selected workflow through integrated automation platform
- Collect data and extract relevant information
- Validate information quality against established metrics
Iterative Refinement
- Analyze results and process performance data
- Refine workflow selection parameters based on outcomes
- Return to Step 3 if objectives are not met [1]
Protocol: AI-Enhanced Compound Screening for Drug Discovery
Objective: To automate the process of compound screening and efficacy prediction using hyperautomation technologies.
Materials and Equipment:
- Compound libraries (physical or virtual)
- High-throughput screening automation
- AI/ML platforms with predictive modeling capabilities
- Data integration infrastructure
Procedure:
Data Collection and Preparation
- Assemble diverse compound libraries with associated structural and property data
- Curate historical data on compound efficacy and toxicity
- Preprocess data for AI/ML model training [44]
Predictive Model Development
- Train machine learning models on existing compound data
- Validate model predictions against known outcomes
- Optimize models for specific therapeutic targets [44]
Virtual Screening Implementation
- Deploy trained models to screen virtual compound libraries
- Prioritize candidates based on predicted efficacy and toxicity profiles
- Identify lead compounds for experimental validation [44]
Experimental Validation
- Automate synthesis of prioritized compounds using robotic systems
- Execute high-throughput biological testing
- Collect experimental data on compound performance [47]
Model Refinement
- Incorporate experimental results into training datasets
- Retrain AI/ML models with expanded data
- Improve prediction accuracy through iterative refinement [44]
Reporting and Documentation
- Automate generation of experimental reports
- Update compound databases with new results
- Document processes for regulatory compliance [45]
The Scientist's Toolkit: Essential Research Reagents and Solutions
Key Research Reagent Solutions for Hyperautomation
Table 3: Essential Research Reagents and Solutions for Automated Experimentation
| Reagent/Solution | Function | Application Context |
|---|---|---|
| Deep Learning-Based Image Denoisers | Enhance data quality from accelerated acquisition | Materials characterization (e.g., SEM, TEM) [1] |
| Intelligent Document Processing (IDP) | Extract, classify, validate data from unstructured documents | Regulatory submissions, lab notebooks [41] |
| Process Mining Tools | Analyze digital footprints to identify automation opportunities | Workflow optimization across research domains [41] |
| Machine Learning Models for QSAR | Predict compound activity based on structural features | Drug discovery, materials informatics [44] |
| Integration Platform as a Service (iPaaS) | Connect disparate instruments and software systems | Cross-platform research automation [41] |
| Low-code/No-code Automation Platforms | Enable domain experts to create automations without programming | Custom workflow development by scientists [40] |
| AI Agents and Cognitive Automation | Execute cognitive tasks and adapt in real-time | Autonomous experiment design and optimization [41] |
Implementation Framework and Process Flow
The Autonomous Experimentation Hyperautomation Cycle
The implementation of hyperautomation in research environments follows a systematic cycle that transforms traditional workflows into autonomous experimentation systems:
Autonomous Experimentation Cycle
Implementation Considerations
Successful implementation of hyperautomation in research environments requires addressing several critical considerations:
- Technology Integration: Legacy systems must be integrated with modern automation platforms through APIs and middleware [46]
- Data Management: Robust data governance ensures quality inputs for AI/ML algorithms [44]
- Change Management: Researchers need training and support to transition to automated workflows [40]
- Regulatory Compliance: Automated processes must maintain compliance with relevant regulations [45]
- Validation and Documentation: Automated systems require rigorous validation and comprehensive documentation [45]
Hyperautomation represents a paradigm shift in how scientific research is conducted, moving from manual, segmented workflows to integrated, intelligent systems capable of autonomous operation. By connecting AI, RPA, and analytics within a cohesive framework, research organizations can achieve unprecedented levels of throughput, reproducibility, and efficiency. The protocols and applications outlined in this document provide a foundation for implementing hyperautomation in drug discovery and materials research, enabling scientists to focus on high-value creative tasks while automated systems handle routine operations and complex data analysis. As these technologies continue to evolve, hyperautomation will play an increasingly central role in accelerating scientific discovery and innovation.
Overcoming Challenges and Optimizing High-Throughput Workflow Performance
Identifying and Eliminating Common Bottlenecks in Automated Workflows
In high-throughput autonomous experimentation, a bottleneck is a point of congestion where workload input exceeds processing capacity, causing delays that slow the entire experimental pipeline [48]. These bottlenecks magnify inefficiency when automated systems are applied to flawed operations [49]. They exist regardless of how well individual components function and can profoundly impact research throughput by sharply increasing time and costs [50].
Bottlenecks manifest in two primary forms: short-term bottlenecks caused by temporary issues like equipment failure or staff absence, and long-term bottlenecks resulting from fundamental process design flaws that recur consistently [51]. In drug development workflows, eliminating these constraints is crucial for maintaining experimental velocity and data integrity.
Quantitative Framework for Bottleneck Analysis
Effective bottleneck management requires systematic measurement and classification. The following metrics provide researchers with standardized assessment criteria.
Table 1: Key Quantitative Metrics for Bottleneck Identification
| Metric Category | Specific Measurement | Threshold Indicator | Data Collection Method |
|---|---|---|---|
| Temporal Analysis | Wait times between workflow steps | Exceeds expected range by >15% | Process mining, timestamp analysis |
| Throughput Capacity | Workload volume vs. processing capacity | Input >85% of design capacity | System monitoring, load testing |
| Backlog Accumulation | Pending tasks at specific stages | Consistent growth over 3+ cycles | Queue monitoring, work-in-progress tracking |
| Error Rates | Process-specific failures | >5% failure rate at any stage | Quality control checks, exception reporting |
| Resource Utilization | Equipment or personnel usage | Sustained >90% utilization | Performance monitoring, workload assessment |
Statistical analysis of these metrics should employ descriptive statistics (mean, median, mode) to understand central tendencies and inferential statistics (hypothesis testing, ANOVA) to determine significant differences between operational states [52] [53]. For example, comparing mean processing times across different experimental batches using t-tests can identify statistically significant slowdowns.
Systematic Bottleneck Identification Methodologies
Process Mapping and Analysis
Complete workflow auditing requires creating detailed swim lane diagrams that visualize each process step, decision point, and handoff [51]. Researchers should:
- Document every stage from experimental design to data analysis
- Measure cycle times for each activity
- Identify dependencies between parallel processes
- Map information flows across laboratory information management systems (LIMS)
Table 2: Bottleneck Identification Approaches
| Method | Application Context | Implementation Protocol | Key Outputs |
|---|---|---|---|
| Process Flow Analysis | New workflow implementation | 1. Outline all process stages2. Measure throughput at each stage3. Analyze lead times4. Identify existing backlogs | Throughput capacity model, constraint identification |
| KPI Monitoring | Ongoing workflow optimization | 1. Establish baseline metrics2. Implement real-time monitoring3. Set threshold alerts4. Regular performance review | Performance dashboards, early warning systems |
| Staff Engagement | Performer-based bottlenecks | 1. Conduct structured interviews2. Survey workload perception3. Identify skill gaps4. Map communication patterns | Resource allocation insights, training needs assessment |
Diagnostic Visualization
The following diagnostic algorithm provides a systematic approach for bottleneck identification:
Bottleneck Resolution Framework
Strategic Intervention Approaches
Once identified, researchers can apply multiple strategies to eliminate workflow constraints:
- Increase Process Capacity: Enhance bottleneck resource capability through equipment upgrades, additional staffing, or performance optimization [50]
- Minimize Downtime: Implement preventive maintenance schedules, reduce changeover times, and maintain replacement parts inventory [50]
- Optimize Performance: Protect bottlenecks from upstream/downstream issues and implement optimized scheduling [50]
- Reassign Tasks: Balance workload by transferring tasks from bottlenecked stages to team members with available capacity [48]
- Extend Operation Timeline: Adjust workflow timing to distribute processing load more evenly [48]
Automation Solutions
Workflow automation specifically targets bottleneck elimination through:
- Rule-based automation using if-then logic for predefined scenarios [49]
- Multi-step orchestration connecting sequential tasks across systems [49]
- Adaptive intelligence employing AI/ML to optimize workflows based on historical patterns [49]
- Autonomous operation implementing self-optimizing systems with minimal intervention [49]
AI-powered technologies can predict bottleneck occurrence through pattern recognition in process data and suggest optimal resolutions through prescriptive analytics [50].
Implementation Protocol for Bottleneck Elimination
The following structured protocol ensures comprehensive bottleneck resolution:
Experimental Protocol: Systematic Bottleneck Resolution
Objective: Implement a comprehensive strategy to identify and eliminate bottlenecks in automated experimentation workflows.
Materials:
- Process mapping software (Lucidchart, Microsoft Visio)
- Workflow automation platform (Xurrent, Workato, Gravity Flow)
- Performance monitoring tools (Quadratic, ChartExpo, custom scripts)
- AI-based predictive analytics tools
Procedure:
Bottleneck Identification Phase
- Create detailed process maps documenting each workflow step
- Instrument all process steps to collect performance metrics
- Analyze cycle times, queue lengths, and error rates
- Interview technical staff to identify perceived constraints
Root Cause Analysis
Solution Implementation
- Select appropriate resolution strategy based on bottleneck classification
- Configure automation rules to address identified constraints
- Reassign tasks or extend operational timelines as needed
- Implement AI-based prediction and prevention systems [50]
Validation and Monitoring
- Establish baseline performance metrics pre-implementation
- Monitor key indicators post-implementation
- Conduct statistical analysis of performance changes
- Document resolution effectiveness and lessons learned
Quality Control:
- Verify all instrumentation before data collection
- Ensure statistical significance in performance comparisons
- Validate automation rules through controlled testing
- Confirm that resolution of one bottleneck doesn't create new constraints
Research Reagent Solutions for Workflow Optimization
Table 3: Essential Research Reagent Solutions for Workflow Optimization
| Reagent/Tool | Function | Application Context |
|---|---|---|
| Process Mining Software | Automated discovery of process flows from system logs | Identifying deviations from planned workflows |
| Statistical Analysis Packages | Quantitative analysis of performance metrics | Determining significant performance variations |
| AI-Based Predictive Tools | Forecasting potential bottlenecks using historical data | Proactive bottleneck prevention |
| Workflow Automation Platforms | Implementing rule-based and adaptive automation | Executing bottleneck resolution strategies |
| Real-Time Monitoring Dashboards | Visualizing workflow performance metrics | Continuous bottleneck detection |
| Integration Middleware | Connecting disparate laboratory systems | Resolving data transfer bottlenecks |
Effective bottleneck management in high-throughput autonomous experimentation requires systematic identification, quantitative analysis, and strategic resolution. By implementing the protocols and methodologies outlined in this document, researchers can significantly enhance workflow efficiency, reduce operational costs, and accelerate drug development timelines. The integration of AI-powered automation technologies provides increasingly sophisticated capabilities for predictive bottleneck prevention and autonomous optimization, representing the future of streamlined experimental workflows.
Addressing Data Scarcity, Noise, and Generalization Limits in AI Models
In autonomous experimentation research, particularly within drug development and materials science, the efficacy of artificial intelligence (AI) is fundamentally constrained by data quality and availability. AI-driven high-throughput workflows demand robust, generalizable models, yet these are often undermined by three pervasive challenges: data scarcity (insufficient labeled data for training), data noise (inconsistencies and errors in experimental data), and generalization limits (model failure when faced with novel conditions or out-of-distribution samples) [6] [32]. This document details practical protocols and reagent solutions to overcome these bottlenecks, accelerating the pace of discovery in self-driving laboratories.
Application Notes & Protocols
The following application notes provide targeted strategies for mitigating core data-related challenges in AI for autonomous research.
Application Note AN-01: Mitigating Data Scarcity via Few-Shot Learning and Synthetic Data
Objective: To enable accurate AI model performance when real, labeled experimental data is limited or costly to acquire.
Background: Traditional supervised learning requires thousands of labeled data points, creating a bottleneck in experimental domains. Two paradigms address this: Few-Shot Learning (FSL), which allows models to learn from a very small number of examples and Synthetic Data Generation, which creates artificial, statistically valid datasets to augment training [54] [55].
Quantitative Comparison of Data-Efficient Learning Techniques:
Table 1: Comparative analysis of techniques for managing data scarcity.
| Technique | Principle | Data Samples Needed | Best-Suited Application in Autonomous Labs | Reported Performance Gain |
|---|---|---|---|---|
| Few-Shot Learning (FSL) | Leverages prior knowledge to learn new tasks from few examples [54]. | 2-5 per category [54] | Rapid adaptation to new material synthesis or defect detection [54]. | Reduced training cycle from 3 weeks to hours in a sales training model [54]. |
| One-Shot Learning | A subset of FSL using a single example per category [54]. | 1 per category [54] | Employee identification from a single photo; adapting to a new chemical reaction with one example [54]. | Not specified in search results. |
| Zero-Shot Learning | Relies on prior knowledge and task description without examples [54]. | 0 [54] | Answering industry-specific questions or generating hypotheses for novel compound synthesis [54]. | Not specified in search results. |
| Synthetic Data (GANs/VAEs) | Algorithmically generates data mimicking real-world statistics [55]. | Scales infinitely from base model. | Simulating rare cyber-attack patterns or generating virtual chemical reaction data [55]. | Improved detection of emerging threats and generalization to unseen scenarios [55]. |
Protocol P-01: Implementing Few-Shot Learning for a New Defect Detection Task
This protocol outlines the steps to quickly adapt a pre-trained visual inspection model to identify a new type of manufacturing defect using only a handful of labeled images.
Pre-training & Model Selection:
- Begin with a convolutional neural network (CNN) pre-trained on a broad dataset of industrial images (e.g., general product assemblies, common defects).
- This model has already learned general feature representations like edges, textures, and shapes.
Support Set Preparation:
- Collect a small, well-annotated "support set" of 2-5 images containing the new defect. Ensure these examples are high-quality and representative of the defect's variation [54].
- For the corresponding "query set," gather unlabeled images from the production line on which the model will make predictions.
Model Adaptation (Metric-Based Approach):
- Feature Embedding: Use the pre-trained CNN to transform all images in the support and query sets into high-dimensional feature vectors (embeddings).
- Similarity Metric Calculation: Employ a metric like cosine similarity or Euclidean distance to compare the embedding of a query image to the embeddings of all images in the support set [54].
- Classification: Classify the query image based on the class of its nearest neighbors in the support set. For instance, if a query image's embedding is most similar to the support set embeddings of "defective" samples, it is classified as defective.
Validation:
- Test the adapted model on a separate, held-out validation set of images containing the new defect to measure its few-shot performance.
Protocol P-02: Generating Synthetic Data for Cybersecurity Threat Simulation
This protocol describes generating synthetic data to train AI models for detecting rare cyber-threats in a research network, where real attack data is scarce and sensitive.
Tool Selection:
- Choose a generative model architecture such as a Generative Adversarial Network (GAN) or a Variational Autoencoder (VAE) [55].
Data Preparation & Scoping:
- Gather and anonymize available real network traffic data. Define the statistical characteristics (e.g., packet size distributions, connection frequencies) that the synthetic data must replicate.
Model Training:
- Train the generative model on the pre-processed real data. The model learns the underlying probability distribution of the normal and malicious network traffic features.
Synthetic Data Generation:
- Use the trained generator to create novel, synthetic network logs that mimic real data. This data can be engineered to include specific, rare attack signatures that are underrepresented in the original dataset [55].
Validation & Fusion:
- Statistical Validation: Ensure the synthetic data statistically mirrors the real data's properties.
- Performance Validation: Augment the original training dataset with the generated synthetic data. Re-train the threat detection model on this combined dataset and validate its performance on a held-out test set of real network data to confirm improved detection rates for rare attacks [55].
Application Note AN-02: Correcting for Data Noise and Enhancing Generalization
Objective: To improve AI model robustness and reliability in the presence of noisy, inconsistent data and to ensure performance generalizes to new, unseen experimental conditions.
Background: Experimental data from high-throughput platforms is often noisy due to instrumental variability, environmental fluctuations, or human error. Furthermore, models trained on narrow datasets fail to generalize, a critical limitation for autonomous discovery [6] [32]. The LIRA module exemplifies a closed-loop approach to this problem [32].
Quantitative Analysis of Generalization and Noise-Reduction Techniques:
Table 2: Strategies for managing data noise and improving model generalization.
| Challenge | Technique | Principle | Impact on Autonomous Workflows |
|---|---|---|---|
| Data Noise | Vision-Language Models (VLMs) for Inspection | Uses AI (e.g., LIRA module) for real-time visual error detection and reasoning during robotic operations [32]. | Achieved 97.9% error inspection success rate; 34% reduction in manipulation time [32]. |
| Generalization Limits | Meta-Learning | Models are trained across many tasks to "learn how to learn," enabling rapid adaptation to new tasks with limited data [54]. | Ideal for labs frequently switching between different types of synthesis or analysis [54]. |
| Generalization Limits | Transfer Learning | A pre-trained model (a "foundation model") is fine-tuned on a small, specific dataset from a new domain [6]. | Reduces data and computational resources needed for new experiments. |
| Generalization Limits | Multi-Modal Data Integration | Combines diverse data types (e.g., spectral, visual, textual) to build a richer, more robust contextual model [32]. | Improves reasoning and failure recovery in complex workflows, as seen in the LIRA module [32]. |
Protocol P-03: Implementing Real-Time Error Inspection with the LIRA Module
This protocol integrates the LIRA (Localization, Inspection, and Reasoning) module to create a closed-loop, error-resistant workflow for a mobile robotic manipulator in a self-driving lab [32].
System Setup:
- Hardware: Integrate a camera on a robotic manipulator. Ensure an edge computing device is available to host the LIRA server for low-latency VLM processing [32].
- Software: Deploy the LIRA client-server architecture. The client runs on the robot's control system, while the server runs the fine-tuned VLM on the edge device [32].
Workflow Integration:
- Navigation & Localization: The mobile robot navigates to a work station (e.g., an LCMS vial holder). LIRA uses its camera and a visual marker (e.g., an ArUco marker) to precisely localize the robot arm relative to the target [32].
- Initial Manipulation: The arm executes its primary task (e.g., picking up a vial and attempting to place it into the LCMS instrument).
Closed-Loop Inspection & Reasoning:
- Image Capture & Prompting: At a critical point (e.g., after placement), the robot captures an image. The LIRA client sends this image with a text prompt (e.g., "Is the vial correctly seated in the LCMS sampler?") to the LIRA server [32].
- VLM Processing: The server processes the image and prompt through its fine-tuned VLM, which reasons about the scene.
- Action Handling: The server returns a decision (e.g., "Success," "Vial is tilted," or "Vial is missing") to the robot client. An
InspectionHandlerfunction interprets this result and decides the next action: proceed to the next task, or execute a recovery procedure [32].
Recovery Execution:
- If an error is detected, the robot can attempt a corrective action, such as re-localizing and re-attempting the insertion, or alerting a human operator for intervention.
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Key software and hardware "reagents" for building resilient autonomous research platforms.
| Research Reagent | Type | Function in Addressing Data Challenges | Example Tools / Frameworks |
|---|---|---|---|
| Vision-Language Models (VLMs) | Software Model | Provides real-time visual reasoning for error detection and recovery, mitigating data noise from failed experiments. | LIRA module [32] |
| Generative Adversarial Networks (GANs) | Software Model | Generates high-quality synthetic data to overcome data scarcity for rare events or to protect privacy. | Used in synthetic data generation for cybersecurity [55]. |
| Large Language Models (LLMs) | Software Model | Acts as a "brain" for autonomous labs, planning experiments, retrieving knowledge, and operating robotics, enhancing generalization [6]. | Coscientist, ChemCrow, ChemAgents [6] |
| Meta-Learning Algorithms | Software Algorithm | Enables models to adapt quickly to new tasks with limited data, directly tackling data scarcity and generalization limits [54]. | Not specified in search results. |
| Edge Computing Device | Hardware | Provides the necessary computational power for real-time, low-latency processing of AI models (e.g., LIRA's VLM) at the data source [32]. | Not specified in search results. |
| Mobile Robotic Manipulator | Hardware | Provides the physical actuator for autonomous experiments, often integrated with vision systems like LIRA for closed-loop control [32]. | Platforms integrated with LIRA [32]. |
Workflow Visualizations
Data Scarcity Solution Workflow
Closed Loop Error Inspection with LIRA
Autonomous experimentation systems represent a paradigm shift in scientific research, integrating artificial intelligence (AI), robotic systems, and high-throughput workflows to accelerate discovery. The performance of these systems is critically dependent on underlying hardware and software architectures. This document details strategies for designing modular and flexible systems that can navigate the inherent constraints of autonomous laboratories, thereby enhancing their scalability, adaptability, and efficiency within high-throughput workflow selection frameworks.
Hardware Constraints and Modular Design Strategies
Hardware constraints in autonomous laboratories often stem from fixed instrumentation setups and a lack of standardized interfaces, which limit system reconfigurability for diverse experimental tasks.
Key Hardware Constraints
- Specialized Instrumentation: Current platforms often possess highly specialized hardware, where components like furnaces for solid-phase synthesis and liquid handlers for organic synthesis are not easily interchangeable [6].
- Limited Hardware Architectures: The absence of modular hardware architectures that can seamlessly accommodate diverse experimental requirements hinders generalization across different chemical domains [6].
- Integration Challenges: Mobile robots used for transporting samples between fixed instruments present a hardware configuration challenge, requiring precise coordination and interoperability [6].
Strategic Solutions for Modular Hardware
- Develop Standardized Interfaces: Creating standardized interfaces allows for the rapid reconfiguration of different instruments, facilitating a more flexible experimental setup [6].
- Extend Mobile Robot Capabilities: Enhancing mobile robots with specialized analytical modules that can be deployed on-demand increases the flexibility and scope of autonomous operations [6].
- Adopt a Top-Down Design Philosophy: In mechanical terms, this involves using pre-defined module skeletons, interfaces, and envelopes. This ensures that all module variants are compatible with the system and that interfaces are controlled and governed over time [56].
Software Constraints and Flexible Architecture Strategies
Software constraints primarily involve data quality, model generalizability, and the architectural design of the software that controls the autonomous system.
Key Software Constraints
- Data Scarcity and Noise: AI model performance is highly dependent on data quality. Experimental data often suffer from scarcity, noise, and inconsistent sources, hindering accurate tasks like materials characterization [6].
- Limited Model Generalization: AI and Large Language Models (LLMs) are often specialized for specific tasks and struggle to generalize across different domains or conditions. LLMs can also generate confident but incorrect information, leading to failed experiments [6].
- Architectural Drift: Without a clear focus, software components that start as modular can grow beyond their original intent, becoming bloated and losing their modularity [57].
Strategic Solutions for Flexible Software
- Implement Foundational Modular Principles:
- Separation of Concerns (SoC): Divide the system into distinct modules, each handling a specific function [58].
- High Cohesion and Low Coupling: Ensure elements within a module are closely related (high cohesion), while modules themselves interact with minimal dependencies (low coupling) [57] [58].
- Information Hiding: Modules should communicate through well-defined, stable interfaces without exposing their internal implementation details [57].
- Leverage Advanced AI Training Techniques: To enhance model generalization, employ foundation models trained across different materials and reactions, and use transfer learning to adapt models to new data [6].
- Adopt a Modular Monolithic Architecture: This hybrid approach maintains a single, unified codebase but divides the application into distinct, well-defined modules. It offers a balance between the simplicity of a monolith and the flexibility of microservices, making it suitable for systems of low to moderate scale [58].
- Purpose-Led Programming: Treat software as a collection of interchangeable modules with well-defined purposes, which is a key mindset for fighting complexity [57].
High-Throughput Workflow Selection Framework
The value of a workflow is derived from the quality and actionability of the information it generates. The following framework enables the optimal selection of high-throughput data collection workflows [1].
Workflow Selection Protocol
- Establish Objective: The user defines a quantifiable objective to guide the workflow development.
- List Available Procedures: The user enumerates the procedures, methods, and models to be considered.
- Fast Search: Conduct a broad search over all possible user-defined workflows to filter for high-quality candidates.
- Fine Search: Perform a detailed search and evaluation of the high-quality workflows to select the optimal one based on the objective.
Quantitative Metrics for Workflow Evaluation
Table 1: Quantitative Metrics for Evaluating Data Collection Workflows
| Metric | Description | Measurement Example |
|---|---|---|
| Collection Time | Time required to execute the workflow. | An optimal workflow reduced BSE-SEM image collection time by a factor of 85 compared to a previous study [1]. |
| Information Quality | A combination of accuracy, certainty, and resolution of the extracted data. | Proportional to the ability to make high-value decisions [1]. |
| Information Actionability | Usefulness of the information in achieving the specified objective. | A user-defined decision function; ground-truth data is highly actionable but often expensive [1]. |
| Success Rate | The proportion of successfully completed experiments. | A-Lab achieved a 71% success rate in synthesizing target materials (41 of 58) [6]. |
Experimental Protocols for Autonomous Experimentation
Protocol: Closed-Loop Operation of an Autonomous Laboratory
This protocol describes the general procedure for operating a self-driving lab, integrating AI and robotic execution [6].
- Objective Parsing: The system parses a user's command into a quantifiable objective.
- Information Identification: The system identifies the necessary information required to achieve the objective.
- Workflow Design: The system designs a workflow (a sequence of testing, characterization, and/or simulation steps) to collect the relevant information.
- Experimental Design: The system designs a sequence of experiments using the selected workflow to optimally gain information.
- Robotic Execution: Robotic systems automatically carry out the experimental steps (e.g., reagent dispensing, reaction control, sample collection).
- Data Analysis & Interpretation: Software algorithms or ML models analyze characterization data (e.g., XRD, NMR, MS) for substance identification and yield estimation.
- Iteration: Based on the analysis, the system proposes improved experimental conditions or routes using AI techniques like active learning and Bayesian optimization, and the loop (Steps 3-6) repeats until the objective is met.
Protocol: LLM-Driven Hierarchical Multi-Agent Experimentation
This protocol leverages a multi-agent system for on-demand chemical research [6].
- Task Management: A central Task Manager agent receives a research objective.
- Agent Coordination: The Task Manager coordinates four role-specific agents:
- Literature Reader: Performs web searching and document retrieval for prior knowledge.
- Experiment Designer: Generates initial synthesis schemes and reaction conditions.
- Computation Performer: Executes necessary computational chemistry calculations.
- Robot Operator: Generates code to control robotic experimentation systems.
- Plan Execution: The designed experimental plan is executed by the robotic platform.
- Analysis and Learning: Data from the experiment is analyzed, and the results are fed back to the agents to refine the approach.
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Key Research Reagents and Materials for Autonomous Experimentation
| Item | Function / Description |
|---|---|
| Precursor Libraries | Comprehensive collections of chemical starting materials for solid-state and solution-phase synthesis, selected by AI models for target materials [6]. |
| Solid-State Synthesis Furnaces | Instruments for high-temperature reactions to create inorganic materials, as used in platforms like A-Lab [6]. |
| Chemspeed ISynth Synthesizer | An automated synthesizer robot for performing organic synthesis reactions with minimal human intervention [6]. |
| X-Ray Diffractometer (XRD) | Used for phase identification and characterization of crystalline materials. ML models are used to analyze XRD patterns autonomously [6]. |
| Benchtop NMR Spectrometer | Provides structural information for organic molecules. Integrated into modular platforms for automated analysis [6]. |
| UPLC–Mass Spectrometry | Provides ultra-performance liquid chromatography separation coupled with mass spectrometry detection for analyzing reaction mixtures and identifying compounds [6]. |
| Deep-Learning Based Image Denoiser | AI tool used to enhance the quality of characterization data (e.g., SEM images), enabling faster data collection by reducing the required signal-to-noise ratio [1]. |
System Architecture and Workflow Visualizations
Autonomous Lab Closed-Loop
This diagram illustrates the continuous, closed-loop cycle of an autonomous laboratory.
Modular System Top-Down Design
This diagram depicts the top-down design approach for creating a flexible and governed modular system.
Workflow Selection Framework
This flowchart visualizes the framework for selecting the optimal high-throughput data collection workflow.
Autonomous Experimentation (AE) systems represent a transformative strategy to accelerate materials design and reduce product development cycles by executing an iterative research loop of planning, experiment, and analysis autonomously [1]. However, the reliability of these systems is often compromised by a critical limitation: robotic manipulation in most autonomous workflows operates in an open-loop manner, lacking real-time error detection and correction [32]. This assumes flawless execution without accounting for potential failures, an unrealistic expectation that reduces overall efficiency and reliability. Building systems that can proactively handle errors and demonstrate robustness is not merely an optimization but a foundational requirement for the advancement of the Integrated Computational Materials Engineering paradigm and high-throughput drug discovery.
The core challenge lies in the transition from static, human-defined workflows to dynamic, self-correcting systems. Current AE systems typically start with the adoption of a human-designed experimental workflow that remains static throughout the entire process [1]. This approach, while creating a controlled and repeatable information stream, severely limits the potential application space of AE systems to tasks that are strictly defined by human operators and are repetitive in nature. For AE systems to achieve their full potential and adapt to rapid technological advances, they must be endowed with the decision authority to select high-value data collection workflows and recover from unexpected failures independently of human scientists and engineers [1].
Theoretical Framework: Quantifying Workflow Value and Robustness
The Value of Information in Workflow Selection
A robust framework for autonomous experimentation must begin by specifying an objective that needs to be met. A well-designed Workflow generates relevant Information that adds significant Value to the broader objective [1]. This relationship can be conceptualized as: Workflow → Information → Value
The value of information is proportional to its Quality and Actionability [1]. Actionability is a user-defined decision function that explains how useful information is in achieving a particular objective. High-actionability information is critical to making high-value decisions, such as ground-truth defect density for estimating mechanical stability. Quality is proportional to the information's Accuracy with respect to a pre-determined ground truth and its Precision [1]. This quantitative framework enables the systematic comparison of competing workflows and error-handling strategies.
Defining Robustness in Analytical Methods
In method validation, robustness (or ruggedness) is defined as a measure of an analytical procedure's capacity to remain unaffected by small, but deliberate variations in method parameters, providing an indication of its reliability during normal usage [59]. This definition, widely applied in the pharmaceutical world under ICH guidelines, emphasizes that the consequences of robustness evaluation should include establishing a series of system suitability parameters to ensure the validity of the analytical procedure is maintained whenever used [59]. This formal approach to robustness testing systematically identifies factors that could impair method performance, allowing analysts to control these factors more strictly during method execution.
Core Protocols for Robust System Implementation
Protocol: Implementation of a Closed-Loop Inspection System
The Localization, Inspection, and Reasoning (LIRA) module provides a proven protocol for enhancing robotic decision-making through vision-language models, enabling real-time error detection and correction in self-driving labs [32].
- Purpose: To enable precise localization, automated error inspection, and reasoning, allowing robots to adapt dynamically to variations from the expected workflow state.
- Experimental Materials and Setup:
- Robotic System: Mobile manipulator with an edge computation device.
- Vision System: Camera(s) with appropriate field of view and resolution for the inspection tasks.
- Software Framework: Client-server architecture supporting SOAP and Flask communication protocols.
- VLMs: Vision-language models fine-tuned on domain-specific image datasets.
- Methodology:
- System Initialization: Initialize workflow parameters (station name, target name, fiducial marker ID).
- Vision-Based Localization: After the mobile robot navigates to a station, the arm moves to a predefined position for visual calibration. The client sends an ArUco pose request via the network, and a 6×1 vector representing the marker pose is returned to update manipulation-related frames.
- Manipulation Execution: The robotic arm executes its manipulation task.
- Closed-Loop Inspection: At critical points where errors are likely, the inspection client is invoked. An inspection request (input prompt) is transmitted while the camera captures an image. This is processed by LIRA on the server, which returns inspection and reasoning results to the client.
- Error Recovery: The robot applies the
InspectionHandlerto interpret the response and determine the appropriate next action, enabling dynamic recovery from errors.
- Validation: Testing across diverse tasks has demonstrated an error inspection success rate of 97.9%, high localization accuracy, and a tenfold reduction in localization time [32].
Protocol: Experimental Robustness Testing for Method Validation
This guideline provides a systematic approach for setting up and interpreting a robustness test, critical for ensuring method reliability during technology transfer between instruments or laboratories [59].
- Purpose: To examine potential sources of variability in method responses and identify factors that must be strictly controlled during method execution.
- Experimental Materials: Aliquots of the same test sample and standard(s) to be examined at different experimental conditions.
- Methodology:
- Factor Identification: Select factors from the analytical procedure (operational factors) and environmental conditions (environmental factors). These can be quantitative (continuous), qualitative (discrete), or mixture factors.
- Level Definition: Define the different levels for each factor. The interval should slightly exceed the variations expected during method transfer.
- Design Selection: Employ two-level screening designs (fractional factorial or Plackett-Burman designs) to screen a relatively large number of factors in a small number of experiments.
- Experiment Execution: Perform design experiments in a random sequence to avoid confounding factor effects with time-related effects.
- Response Measurement: Determine critical responses, such as content of main substance, peak areas/heights, and system suitability parameters (e.g., resolution, tailing factors).
- Effect Calculation: Calculate effects for each factor using the formula:
E(X) = [ΣY(+)/N] - [ΣY(-)/N], where E(X) is the effect of factor X on response Y, ΣY(+) is the sum of responses where X is at the (+) level, and ΣY(-) is the sum of responses where X is at the (-) level. - Statistical Analysis: Analyze effects statistically and/or graphically to identify factors with significant influence on the responses.
- System Suitability Limits: Derive SST limits based on experimental evidence from the robustness test.
Data Presentation and Analysis
Table 1: Performance Comparison of Autonomous Workflow Strategies
This table summarizes quantitative data comparing the performance of different workflow approaches, highlighting the efficiency gains from optimized and error-adaptive systems.
| Workflow Strategy | Data Collection Time | Relative Speed Improvement | Error Inspection Success Rate | Key Application |
|---|---|---|---|---|
| Traditional Workflow [1] | Baseline | 1x | Not Applicable | BSE-SEM image collection |
| Framework-Optimized Workflow [1] | 5x faster than benchmark | 5x | Not Applicable | BSE-SEM image collection |
| Deep-Learning Enhanced Workflow [1] | 85x faster than previous study | 85x | Not Applicable | BSE-SEM image collection |
| LIRA-Enhanced Workflow [32] | 34% reduction in manipulation time | ~1.5x | 97.9% | Solid-state chemistry workflows |
Table 2: Key Research Reagent Solutions for Robust Autonomous Systems
This table details essential materials and computational tools used in implementing robust, error-adaptive experimental systems.
| Item Name | Function/Application | Critical Specifications |
|---|---|---|
| Vision-Language Model [32] | Enables semantic understanding for error inspection and reasoning in robotic tasks. | Fine-tuned on domain-specific image datasets; capable of real-time inference. |
| Edge Computing Device [32] | Provides computational power for real-time image processing and VLM execution on mobile platforms. | Low-latency operation; sufficient processing capacity for model inference. |
| Fiducial Markers [32] | Enables precise vision-based localization of robotic manipulators within laboratory workspaces. | High contrast patterns; resistant to environmental variables like lighting changes. |
| Calibration Board [32] | Facilitates accurate coordinate frame transformation between cameras and robotic manipulators. | Precisely manufactured patterns; dimensionally stable. |
| Experimental Design Software | Supports the selection and analysis of screening designs for robustness testing. | Capable of generating fractional factorial and Plackett-Burman designs. |
System Architecture and Workflow Visualization
LIRA System Architecture Diagram
LIRA Closed-Loop System Architecture
Robustness Testing Protocol Workflow
Robustness Testing Methodology
Error Handling Decision Logic
Error Inspection and Recovery Logic
The integration of Key Performance Indicators (KPIs) and real-time dashboards is fundamental to establishing closed-loop, autonomous experimentation systems. This framework enables researchers to dynamically select and optimize high-throughput workflows by providing actionable, data-driven feedback, thereby accelerating scientific discovery in fields such as materials science and drug development [1] [32].
KPI Framework for Autonomous Experimentation
In autonomous research, the value of a workflow is a function of the information it generates, which is dictated by the information's quality and actionability [1]. KPIs serve as the quantifiable bridge between raw data and high-value decisions.
Table 1: Core KPI Classes for Autonomous Research Workflows
| KPI Class | Definition & Relevance | Example Metrics | Target Attributes (SMART) |
|---|---|---|---|
| Value to Customer | Metrics reflecting how well the process meets end-user (e.g., project) requirements and demands [60]. | On-Time Delivery of Results, Quality of Output Data [60]. | Specific, Measurable, Achievable, Realistic, Time-bound [60]. |
| Value to Company | Metrics affecting the bottom line and operational efficiency of the research program [60]. | Waste Reduction (material, time), Overall Equipment Effectiveness (OEE), Production Downtime, First Pass Yield [60]. | Specific, Measurable, Achievable, Realistic, Time-bound [60]. |
| Value to Employee | Metrics ensuring a safe and productive work environment for researchers and technicians [60]. | Safety Incident Rate, Automation Level of Repetitive Tasks [60]. | Specific, Measurable, Achievable, Realistic, Time-bound [60]. |
| Workflow quality | Metrics proportional to the accuracy and precision of the collected information with respect to a predetermined ground-truth [1]. | Data Fidelity Score, Measurement Precision, Image/Data Quality Index. | Specific, Measurable, Achievable, Realistic, Time-bound [60]. |
| Workflow actionability | A user-defined decision function that explains how useful information is in achieving a specific objective [1]. | Confidence Score for Decision-Making, Root-Cause Identification Rate. | Specific, Measurable, Achievable, Realistic, Time-bound [60]. |
Experimental Protocols for KPI Implementation and Workflow Validation
Protocol: Establishing a KPI-Driven Feedback Loop
This protocol outlines the steps for integrating KPIs into an autonomous experimentation cycle, enabling continuous workflow improvement.
Objective Parsing and KPI Selection:
- Parse the high-level research command (e.g., "identify root cause of failure") into a quantifiable objective [1].
- Select 1-2 high-impact KPIs from each class (Value to Customer, Company, Employee) that directly reflect this objective [60]. Avoid information overload by starting with a manageable set.
Workflow Design and Target Setting:
- Identify potential data collection workflows (e.g., different characterization techniques, sequencing of tests) that can generate the required information [1].
- For each selected KPI, establish a SMART target (e.g., "Reduce characterization data collection time for Sample Batch X by 5% within one month") [60].
Data Source Identification and Instrumentation:
Dashboard Construction and Deployment:
Review, Reporting, and Iteration:
- Conduct regular reviews of the KPI dashboard to track progress and identify deviations [60].
- Use drops in performance as evidence to investigate and initiate corrective actions within the experimental workflow [60].
- Iterate on Steps 3-6 of the autonomous experimentation loop if the objective is not met [1].
Protocol: Validating Workflow Selection via Closed-Loop Inspection
This protocol employs real-time visual inspection to validate and correct robotic manipulations, a common failure point in high-throughput workflows [32].
System Initialization:
- Initialize workflow parameters, including station name, target name, and fiducial marker ID for the robotic system [32].
Vision-Based Localization:
- After the mobile robot navigates to a station, the robotic arm moves to a predefined position for visual calibration.
- The client system sends an ArUco pose request. A 6x1 vector representing the marker's pose is returned to update the manipulation-related frames, achieving high-precision localization [32].
Manipulation and Inspection Trigger:
- The robotic arm executes its manipulation task (e.g., pick-and-place of a sample vial).
- At critical points where errors are likely, the inspection client is invoked. An inspection request prompt is transmitted alongside a camera image capture [32].
Visual Inspection and Reasoning:
- The captured image and prompt are processed by a vision-language model (VLM) on a server. The VLM returns inspection and reasoning results (e.g., "vial is misaligned by 3mm") to the client [32].
- An
InspectionHandlerfunction interprets the VLM's response to determine the next action (e.g., initiate a correction maneuver, flag an error, or proceed) [32].
Error Correction and Loop Closure:
- The system autonomously performs corrective actions based on the VLM's reasoning.
- The workflow proceeds to the next task, creating a closed-loop where errors are detected and corrected in real-time, significantly improving reliability [32].
Mandatory Visualizations
Workflow Selection & Improvement Logic
Closed-Loop Autonomous Experimentation
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Components for an Autonomous Research Environment
| Item / Solution | Function / Rationale | Example in Protocol |
|---|---|---|
| Vision-Language Model (VLM) | Provides semantic understanding for visual inspection, enabling the system to reason about task-level errors and dynamically recover [32]. | LIRA module using a fine-tuned VLM to diagnose vial misalignment and suggest corrections [32]. |
| Edge Computing Device | Delivers the computational power required for real-time image processing and VLM inference at the source of data generation, minimizing latency [32]. | LIRA server layer processing inspection requests in real-time without overburdening the central robot control system [32]. |
| Fiducial Markers (ArUco) | Enable fast, high-accuracy vision-based localization of robotic components within a dynamic laboratory environment, updating manipulation frames [32]. | Used in the localization step to calibrate the robot's position relative to a station before precise manipulation [32]. |
| Mobile Robotic Manipulator | Combines mobility with precision, allowing interaction with spatially distributed laboratory instruments (e.g., LCMS, NMR) in a single workflow [32]. | The primary actuator for moving samples between stations in a synthesis or characterization workflow [32]. |
| KPI Dashboard Software | Interactive tool providing a real-time, visual snapshot of KPIs, allowing users to monitor metrics at a glance and support data-driven decisions [61]. | Operational dashboard used by researchers to track data collection time, first pass yield, and equipment effectiveness [61] [60]. |
Validating, Comparing, and Benchmarking Autonomous Workflow Performance
The integration of autonomous experimentation (AE) systems has fundamentally transformed the materials design and drug discovery paradigms, enabling an iterative research loop of planning, experiment, and analysis carried out autonomously [1]. Within this context, the validation of high-throughput screening (HTS) platforms ensures that the massive volumes of data generated are reliable, reproducible, and actionable. Traditional validation parameters, as outlined in guidelines like ICH Q2(R2), provide the foundational framework, but their application must evolve to meet the demands of continuously learning, autonomous systems where workflows are dynamically selected rather than static [62] [63]. This document details application notes and protocols for implementing validation paradigms within the context of high-throughput workflow selection for autonomous experimentation research, providing researchers with structured methodologies to ensure data quality and operational reproducibility.
Core Validation Parameters and Their Application in HTS
The establishment of a robust HTS platform requires meticulous validation against a set of core parameters to ensure the quality and reliability of its output. The following table summarizes these key parameters and their specific considerations within HTS and autonomous contexts.
Table 1: Core Validation Parameters for High-Throughput Screening Platforms
| Validation Parameter | Traditional Definition (ICH Q2(R2) Context) | Application in HTS & Autonomous Workflows |
|---|---|---|
| Specificity | The ability to assess the analyte unequivocally in the presence of components that may be expected to be present. | Demonstration that the assay correctly identifies active compounds (hits) without interference from contaminants, DMSO, or compound auto-fluorescence [62] [64]. |
| Accuracy | The closeness of agreement between the value which is accepted and the value found. | Measured by the Z'-factor, a statistical parameter used to assess the quality and robustness of an HTS assay. A Z'-factor ≥ 0.5 is generally indicative of an excellent assay [63]. |
| Precision | The closeness of agreement between a series of measurements. | Evaluated through plate uniformity studies that measure intra-plate and inter-plate variability (e.g., coefficient of variation - CV%) across hundreds to thousands of data points [63]. |
| Detection Limit | The lowest amount of analyte in a sample that can be detected. | Critical for distinguishing weak hits from background noise in low-signal assays, such as those measuring subtle phenotypic changes [64]. |
| Robustness | A measure of the assay's capacity to remain unaffected by small, deliberate variations in method parameters. | Tested by varying automated liquid handling volumes, incubation times, or reagent stability to ensure reproducibility under robotic operation [62] [63]. |
| Range | The interval between the upper and lower concentrations of analyte for which suitability has been demonstrated. | Defined by the dynamic range of the detection system and the linearity of the response across compound concentrations and cell densities [63]. |
The transition to autonomous experimentation introduces an additional layer of complexity, where the value of information generated by a workflow is proportional to its quality and actionability [1]. Therefore, validation is not merely a one-time pre-screening activity but an ongoing process to ensure that the information driving the autonomous loop is of sufficient quality for AI/ML models to make correct decisions on experimental progression.
Workflow Selection Framework for Autonomous Experimentation
Autonomous experimentation systems require a principled framework to dynamically select the highest-value data collection workflow. The following diagram illustrates the core decision-making loop for optimal workflow selection.
Diagram 1: Workflow Selection Framework
This framework, reminiscent of multi-objective optimization, involves several key stages [1]:
- Objective Establishment: The user defines a quantifiable objective (e.g., "identify compounds with >50% inhibition at 10 µM").
- Procedure Listing: The system identifies all available experimental and simulation procedures that could generate relevant information.
- Fast Search: A rapid screening of possible workflows is conducted to filter for those generating high-quality information as per the objective.
- Fine Search: A more rigorous evaluation of the top candidate workflows is performed to select the single optimal workflow that generates the highest-value information, balancing quality, actionability, and cost.
- Execution and Iteration: The selected workflow is executed, and the system assesses if the objective is met, iterating back to step 3 if necessary.
A case study in the characterization of an additively manufactured Ti-6Al-4V sample demonstrated the power of this approach. By employing this framework to select an optimal workflow that incorporated a deep-learning based image denoiser, the collection time for high-quality backscattered electron scanning electron microscopy (BSE-SEM) images was reduced by a factor of 85 compared to a previously published study [1].
Detailed Experimental Protocol: Validation of a 3D Patient-Derived Colon Cancer Organoid HTS Platform
This protocol details the establishment and validation of an automated, high-throughput screening platform for three-dimensional patient-derived colon cancer organoid cultures in 384-well format, as a model for rigorous HTS validation [63].
Research Reagent Solutions
The following table lists the essential materials and reagents required for the execution of this protocol.
Table 2: Key Research Reagent Solutions for 3D Organoid HTS
| Item Name | Function/Description | Application in Protocol |
|---|---|---|
| Patient-Derived Organoid Cells | Primary 3D cell cultures that mimic the original tumor microenvironment. | Disease-specific model for drug sensitivity testing. |
| Extracellular Matrix (ECM) Gel | A basement membrane extract that provides a 3D scaffold for organoid growth. | Single cells are embedded in this matrix to enable self-organization into organoid structures. |
| Advanced Cell Culture Medium | A specialized medium containing growth factors and supplements necessary for organoid survival and proliferation. | Supports organoid formation and growth over 4 days prior to compound addition. |
| Compound Library | A curated collection of small molecules for screening. | Source of therapeutic candidates for sensitivity testing. |
| Cell Viability Assay Reagent | A luminescent or fluorescent dye that quantifies ATP levels or metabolic activity as a proxy for cell health. | Endpoint measurement to determine compound efficacy after treatment. |
| 384-Well Microplates | Assay plates with a standardized footprint for automation. | The vessel for the entire workflow, from plating to screening. |
Step-by-Step Protocol
Day 0: Automated Organoid Seeding
- Harvest and Suspend: Harvest patient-derived colon cancer organoids and dissociate them into single cells using a validated enzymatic method.
- Prepare Cell-ECM Mixture: Using an automated liquid handler, mix the single-cell suspension with chilled ECM gel on ice. The final cell density and ECM concentration must be optimized during assay development.
- Plate in 384-Well Format: Dispense a small volume (e.g., 20-40 µL) of the cell-ECM mixture into the center of each well of a 384-well microplate.
- Polymerize ECM: Incubate the microplate at 37°C for 30-60 minutes to allow the ECM gel to solidify.
- Overlay with Medium: Carefully add a predefined volume of advanced cell culture medium on top of the polymerized ECM droplet.
Day 1-4: Organoid Formation
- Maintain Culture: Incubate the microplates at 37°C, 5% CO2 for 4 days to allow the single cells to self-organize into organoid structures.
- Monitor Morphology: Visually inspect a subset of wells under a microscope to confirm successful organoid formation.
Day 4: Compound Treatment
- Prepare Compound Dilutions: Using an automated robotic system, prepare a serial dilution of compounds from the library in the assay medium.
- Add Compounds: Remove a portion of the old medium from each well and replace it with the medium containing the test compounds. Include controls (e.g., DMSO vehicle control for 0% inhibition, and a cytotoxic control for 100% inhibition).
Day 5-7: Endpoint Assay and Readout
- Add Viability Reagent: At the predetermined endpoint (e.g., 72 hours post-treatment), add the cell viability assay reagent to each well according to the manufacturer's instructions.
- Incubate and Read: Incubate the plate for the recommended time and measure the luminescence/fluorescence signal using a high-speed plate reader integrated into the automation system.
Validation and Data Analysis Protocol
- Plate Uniformity Study: To assess assay robustness and reproducibility, perform a replicate-experiment study using control compounds. Calculate the Z'-factor for the assay: Z' = 1 - [ (3σ_positive_control + 3σ_negative_control) / |μ_positive_control - μ_negative_control| ] An assay is considered excellent for HTS if Z' ≥ 0.5 [63].
- Data Normalization: Normalize raw data from each well using the plate-based controls: % Inhibition = (1 - (Signal_sample - Signal_positive_control) / (Signal_negative_control - Signal_positive_control)) * 100%
- Hit Identification: Apply a statistically defined threshold (e.g., % inhibition > 3 standard deviations from the mean of the negative control) to identify active compounds ("hits").
Lifecycle Management of Validated HTS Workflows
Validation in an autonomous environment is not a static event. The lifecycle of an HTS workflow must be managed to account for model drift, changes in reagent lots, and the introduction of new AI-driven tools. The following diagram outlines the continuous validation lifecycle.
Diagram 2: Validation Lifecycle Management
Key aspects of lifecycle management include [1] [62] [6]:
- Continuous Performance Monitoring: Tracking validation parameters like the Z'-factor and hit rates over time to detect performance degradation.
- AI Model Retraining: As autonomous systems generate new data, the AI/ML models used for workflow selection and data analysis must be periodically retrained to maintain predictive accuracy.
- Procedure Updates: The framework must allow for the introduction of new, improved procedures (e.g., a novel denoising algorithm [1] or label-free detection method [64]), which must then be validated and integrated into the pool of available workflows.
- Data and Model Governance: Implementing standardized data formats and uncertainty analysis is critical to managing the lifecycle of models trained on heterogeneous data sources [6].
The Scientist's Toolkit: Essential Research Reagent Solutions
Beyond the specific reagents for the organoid protocol, several core solutions are fundamental to a wide range of HTS campaigns in drug development.
Table 3: Essential Research Reagent Solutions for HTS in Drug Discovery
| Item Name | Function/Description | Common Application Areas |
|---|---|---|
| Enzyme/Receptor Target | Purified protein that is the molecular target of the therapeutic intervention. | Biochemical Assays for enzyme inhibition and receptor-binding studies [64]. |
| Cell Lines with Reporter Genes | Engineered cells containing a detectable reporter (e.g., luciferase, GFP) linked to a pathway of interest. | Cell-Based Assays for measuring pathway modulation and transcriptional activity [64]. |
| Fluorescent Dyes & Probes | Molecules that emit light upon binding to specific cellular components or in response to physiological changes. | High-Content Screening (HCS) for multiparameter analysis of cell morphology, viability, and subcellular localization [64]. |
| Label-Free Detection Kits | Reagents and technologies (e.g., Surface Plasmon Resonance - SPR) that monitor molecular interactions in real-time without labels. | Confirmatory Screens to eliminate false positives by verifying binding affinity and kinetics [64]. |
| Orthogonal Assay Kits | A different assay technology used to re-test hits from the primary screen. | Hit Validation to ensure biological relevance and minimize advancement of false positives [62]. |
In the rapidly evolving field of autonomous experimentation, the systematic quantification of performance is paramount for advancing research in materials science and drug development. The selection of high-throughput workflows hinges on the ability to measure and optimize three critical dimensions: throughput (the volume of experiments completed), reproducibility (the reliability of results), and cost savings (the economic efficiency of the process). This document provides detailed application notes and protocols for researchers and scientists to accurately measure these metrics, enabling data-driven workflow selection and optimization. By implementing these standardized protocols, research teams can significantly accelerate their experimental cycles while maintaining rigorous scientific standards.
Quantifying Throughput in Autonomous Experimentation
Definition and Core Importance
In performance testing, throughput is defined as the amount of data or transactions a system processes within a defined time frame under specific conditions [65]. For autonomous experimentation, this translates to the number of experimental iterations or data points an autonomous system can successfully complete and process per unit of time. Unlike raw speed, throughput reflects real efficiency under load, showing how well resources support scalability, responsiveness, and consistent performance in demanding conditions [65].
High-throughput computing (HTC) in research involves running a large number of jobs, frequently enabled by automation, scripts, and workflow managers [66]. This "task farming" approach is a characteristic feature of HTC but poses unique challenges for job schedulers in high-performance computing (HPC) environments, where excess log data and scheduling overhead can become bottlenecks [66].
Protocol for Measuring Experimental Throughput
Objective: To standardize the measurement of experimental throughput in autonomous research systems for accurate cross-platform comparison and bottleneck identification.
Materials and Equipment:
- Autonomous experimentation platform (e.g., modular robotic system)
- High-performance computing infrastructure
- Job scheduling system (e.g., Slurm)
- Time-tracking software with millisecond precision
- Data logging infrastructure
Methodology:
- Baseline Establishment:
- Execute a minimum of 10 consecutive experimental cycles using a standardized protocol.
- Record the total time from experiment initiation to final data output for each cycle.
- Calculate average cycle time and standard deviation across all runs.
Throughput Calculation:
- Calculate throughput using the formula: Throughput = (Total Completed Experiments) / (Total Time) [65].
- For example, if a system completes 300 experimental runs in 5 minutes: Throughput = 300 / 5 = 60 experiments per minute [65].
- Express results in appropriate units (experiments/hour, data points/second, samples/minute).
Load Testing:
- Gradually increase experimental load from normal to peak operating conditions.
- Measure throughput at each load level to identify performance degradation points.
- Document the maximum sustainable throughput before system failure.
Bottleneck Identification:
- Monitor individual subsystem performance (robotic actuation, sensor measurement, data processing, storage I/O).
- Identify the slowest component in the experimental pipeline as the primary bottleneck.
- Calculate utilization rates for each subsystem during operation.
Data Interpretation:
- Compare throughput metrics against project requirements and historical baselines.
- A decreasing throughput trend under constant load may indicate system degradation.
- Throughput should be analyzed alongside latency metrics for complete performance assessment.
Table 1: Throughput Calculation Examples in Different Research Contexts
| Research Domain | Throughput Metric | Calculation Example | Typical Benchmarks |
|---|---|---|---|
| Materials Characterization | Images processed per hour | 500 BSE-SEM images in 2 hours = 250 images/hour [1] | 5-85x improvement over manual methods [1] |
| Bioproduction Optimization | Experimental conditions tested per day | 48 medium conditions in 24 hours = 2 conditions/hour [22] | Varies with automation level |
| Computational Screening | Molecular simulations completed per hour | 300 simulations in 5 minutes = 3,600 simulations/hour [66] | Dependent on HPC resources |
Visualization of Throughput Optimization Workflow
Diagram Title: Throughput Measurement and Optimization Workflow
Assessing Reproducibility in High-Throughput Experiments
The Reproducibility Challenge in Automated Science
Reproducibility provides crucial information for establishing confidence in measurements and evaluating workflow performance in high-throughput experiments [67]. However, outputs from these systems are often noisy due to numerous sources of variation in experimental and analytic pipelines [67]. In biological contexts, techniques like single-cell RNA-seq experience high levels of dropout events where a gene is observed in one cell but not detected in another of the same type, leading to numerous zero values in datasets [67].
A critical challenge emerges from how missing data is handled in reproducibility assessment. When only candidates with non-missing measurements are considered, assessments can be misleading. If a small proportion of measurements agree well across replicates but the rest are observed only on a single replicate, excluding zeros can suggest high reproducibility despite large amounts of discordance [67].
Advanced Protocol for Reproducibility Assessment
Objective: To implement a statistically robust methodology for assessing reproducibility in high-throughput experiments that properly accounts for missing data and operational factors.
Materials and Equipment:
- Paired replicate datasets from identical experimental conditions
- Statistical computing environment (R, Python)
- Implementation of Correspondence Curve Regression (CCR) or similar advanced methods
- Data visualization tools for reproducibility assessment
Methodology:
- Data Preparation:
- Collect matched datasets from at least 5 experimental replicates.
- Document all missing values and their patterns across replicates.
- Apply appropriate data transformation and normalization techniques.
Statistical Assessment:
- For complete datasets: Apply both Pearson and Spearman correlation analyses between replicate scores [67].
- For datasets with missing values: Implement Correspondence Curve Regression (CCR) with latent variable approach to incorporate missing values [67].
- Calculate Irreproducible Discovery Rate (IDR) or Maximum Rank Reproducibility (MaRR) for rank-based consistency assessment [67].
Operational Factor Analysis:
- Model how operational factors (experimental platforms, sequencing depth, parameter settings) affect reproducibility using regression approaches [67].
- Quantify the impact of each factor on overall reproducibility metrics.
- Determine confidence intervals for reproducibility estimates.
Visualization and Interpretation:
- Generate correspondence curves or CAT (Correspondence at the Top) plots.
- Create scatter plots of matched measurements between replicates.
- Document consistency in top-ranked candidates across significance thresholds.
Data Interpretation:
- Reproducibility coefficients >0.9 indicate excellent consistency.
- Values between 0.7-0.9 suggest acceptable reproducibility for most applications.
- Coefficients <0.7 indicate significant variability requiring protocol optimization.
- Consistency in top-ranked candidates is often more important than overall correlation.
Table 2: Methods for Reproducibility Assessment in High-Throughput Experiments
| Method | Application Context | Handling of Missing Data | Key Output Metrics |
|---|---|---|---|
| Pearson Correlation | Continuous measurements, complete datasets | Excludes cases with missing values | Correlation coefficient (r) |
| Spearman Correlation | Rank-based assessments, non-normal distributions | Excludes cases with missing values | Rank correlation coefficient (ρ) |
| Correspondence Curve Regression (CCR) | Datasets with substantial missing values | Incorporates missing values via latent variable approach | Regression coefficients for operational factors |
| Irreproducible Discovery Rate (IDR) | Ranking consistency assessment | Limited capabilities with missing data | IDR score, reproducibility estimates |
Visualization of Reproducibility Assessment Framework
Diagram Title: Reproducibility Assessment Methodology
Calculating Cost Savings and Return on Investment
The Business Case for Autonomous Experimentation
Quantifying the financial impact of automated research workflows is essential for justifying initial investments and guiding resource allocation decisions. Companies can achieve over 400% ROI within three years when they measure automation impact across customer loyalty, operational efficiency, and risk mitigation [68]. Comprehensive ROI analysis must extend beyond direct cost savings to include productivity gains, error reduction, and risk mitigation [69].
Protocol for ROI Calculation in Research Automation
Objective: To provide a standardized methodology for calculating return on investment and cost savings from implementing autonomous experimentation systems.
Materials and Equipment:
- Financial records of automation implementation costs
- Labor tracking systems
- Productivity monitoring tools
- Error reporting databases
Methodology:
- Establish Baseline Metrics:
- Document current process volumes, handle times, and cost per experiment.
- Measure current error rates and time spent on error rectification.
- Quantify current experimental throughput and reproducibility metrics.
Calculate Implementation Costs:
- Sum all hardware, software, and integration expenses.
- Include training, change management, and operational disruption costs.
- Calculate total cost of ownership (TCO) including ongoing maintenance.
Quantify Benefit Categories:
- Efficiency Gains: Track reduced time-to-resolution (TTR), lower average handle time, and fewer escalations [68].
- Error Reduction: Document decreases in experimental errors and associated rectification costs [69].
- Throughput Improvements: Calculate value of additional experiments completed per time unit.
- Employee Productivity: Measure reduction in time spent on administrative tasks [69].
- Risk Mitigation: Quantify value of compliance improvements, prevented fines, and avoided reputational damage [68].
ROI Calculation:
- Use standard ROI formula: ROI = (Net Gain from Investment - Cost of Investment) / Cost of Investment × 100% [69].
- For example: If you invest $10,000 in workflow software and realize a net gain of $20,000: ROI = (20,000 - 10,000) / 10,000 × 100% = 100% [69].
- Project ROI over appropriate timeframe (typically 3 years for research automation).
Sensitivity Analysis:
- Test ROI calculations under different adoption and utilization scenarios.
- Identify breakeven points and key assumptions driving ROI results.
Data Interpretation:
- ROI >100% within 3 years indicates strong financial justification.
- Payback periods under 12 months are increasingly common for AI deployments [68].
- Non-financial benefits (improved reproducibility, faster discovery cycles) should be documented alongside financial metrics.
Table 3: ROI Calculation Framework for Autonomous Experimentation Workflows
| Cost Category | Measurement Protocol | Typical Range |
|---|---|---|
| Implementation Costs | Sum of hardware, software, integration, training | $50,000 - $500,000+ |
| Efficiency Savings | (Pre-automation time - Post-automation time) × labor rate | 25-30% productivity boosts [68] |
| Error Reduction | (Pre-automation errors - Post-automation errors) × cost per error | 40-75% error reductions [68] |
| Throughput Value | Additional experiments × value per experiment | Varies by research domain |
| Risk Mitigation | Quantified value of compliance improvements and prevented incidents | Difficult to quantify but potentially substantial [68] |
Integrated Workflow Selection Framework
Synthesizing Metrics for Optimal Workflow Selection
The optimal selection of high-throughput data collection workflows requires balancing throughput, reproducibility, and cost considerations. A proposed framework enables the design and selection of workflows for autonomous experimentation systems by first searching for workflows that generate high-quality information, then selecting the workflow that generates the highest-value information as per user-defined objectives [1].
This framework follows a value chain perspective: Workflow → Information → Value, where the value of information is proportional to its quality and actionability [1]. The actionability is a user-defined decision function that explains how useful information is in achieving a particular objective, while quality is proportional to accuracy and precision [1].
The Scientist's Toolkit: Essential Research Reagent Solutions
Table 4: Key Research Reagent Solutions for High-Throughput Experimentation
| Reagent/Resource | Function in Workflow | Application Context |
|---|---|---|
| M9 Minimal Medium | Base medium for microbial culture containing only essential nutrients | Bioproduction optimization (e.g., E. coli strains) [22] |
| Trace Element Mixtures (CoCl₂, ZnSO₄, etc.) | Enzyme cofactors for metabolic pathways | Optimization of glutamic acid production in recombinant strains [22] |
| Deep-Learning Based Image Denoisers | Algorithmic enhancement of noisy imaging data | High-throughput materials characterization [1] |
| Bayesian Optimization Algorithms | Efficient parameter space exploration for experimental optimization | Autonomous medium conditioning and bioprocess optimization [22] |
| Single-Cell RNA-seq Protocols | High-throughput gene expression profiling at single-cell resolution | Biological reproducibility assessment in transcriptomics [67] |
Visualization of Integrated Workflow Selection Process
Diagram Title: Integrated Workflow Selection Framework
The systematic quantification of throughput, reproducibility, and cost savings provides an essential foundation for selecting and optimizing high-throughput workflows in autonomous experimentation research. By implementing the protocols and application notes detailed in this document, researchers and drug development professionals can make data-driven decisions that accelerate discovery while maintaining scientific rigor and fiscal responsibility. The integrated framework presented enables the selection of workflows that maximize information value according to specific research objectives, ultimately advancing the capabilities of autonomous research systems across materials science and pharmaceutical development.
Within high-throughput autonomous experimentation research, the characterization of materials often represents the most significant bottleneck to discovery. The acceleration of these workflows is paramount for closing the gap between computational prediction and experimental realization of novel materials [70]. This Application Note details a case study of "Latice," a machine-learning approach that achieves a 7.5-fold acceleration in Electron Backscatter Diffraction (EBSD) indexing while simultaneously reducing data storage requirements by approximately 99% [71]. This dramatic efficiency gain is a critical step towards the overarching goal of 85-fold speed increases in comprehensive characterization workflows, enabling more rapid and iterative autonomous discovery cycles.
The implementation of the Latice method demonstrated substantial improvements in both the speed and data efficiency of crystallographic analysis. The key performance metrics are summarized in Table 1.
Table 1: Performance Metrics of the Latice Machine Learning Approach
| Performance Indicator | Traditional Workflow | Latice Workflow | Improvement Factor |
|---|---|---|---|
| EBSD Indexing Speed | Baseline | 7.5x Faster | 7.5-fold increase [71] |
| Data Storage Needs | Baseline | ~1% of Original | ~99% reduction [71] |
| Physical Fidelity | Baseline | Preserved | Essential physics of the system maintained [71] |
The success of this characterization workflow is a key enabler for advanced autonomous experimentation platforms, such as the A-Lab, which integrates robotics, artificial intelligence, and real-time data interpretation for the synthesis of novel inorganic powders [70]. The ability to rapidly and efficiently analyze synthesis products, such as via X-ray Diffraction (XRD), is fundamental to the closed-loop operation of such systems.
Experimental Protocols
Protocol 1: Autonomous Synthesis of Novel Inorganic Materials
This protocol describes the solid-state synthesis workflow as implemented by the A-Lab for creating novel inorganic powders [70].
- Target Identification: Select target materials predicted to be stable using large-scale ab initio phase-stability data from sources like the Materials Project.
- Precursor Selection and Recipe Proposal:
- Utilize natural-language models trained on historical synthesis literature to propose initial solid-state synthesis recipes based on analogy to known, similar materials.
- Assign a synthesis temperature using a separate ML model trained on literature heating data.
- Robotic Sample Preparation:
- Dispense and mix precursor powders in the calculated stoichiometric ratios using an automated powder handling station.
- Transfer the mixed powder into an alumina crucible.
- Automated Heating:
- Load the crucible into a box furnace using a robotic arm.
- Execute the heating recipe (temperature ramp, hold, cool) under atmospheric conditions.
- Product Characterization and Analysis:
- After cooling, transfer the sample to a characterization station.
- Grind the sintered product into a fine powder.
- Acquire an XRD pattern of the resulting powder.
- Analyze the XRD pattern using probabilistic machine learning models to identify phases and determine their weight fractions via automated Rietveld refinement.
- Active Learning and Iteration:
- If the target yield is below a defined threshold (e.g., <50%), employ an active learning algorithm (e.g., ARROWS3) that integrates computed reaction energies and observed outcomes to propose a new, optimized synthesis recipe.
- Automatically return to Step 3 to execute the improved recipe.
Protocol 2: Machine-Learning Accelerated EBSD Indexing
This protocol outlines the procedure for implementing the Latice machine-learning approach to accelerate EBSD characterization [71].
- Sample Preparation: Prepare a metallographic or geological sample to a high-quality polished finish suitable for EBSD analysis.
- Data Acquisition:
- Mount the sample in a Scanning Electron Microscope (SEM) equipped with an EBSD detector.
- Define the scan area and step size for the EBSD map.
- Collect the EBSD patterns across the specified region. The large volume of patterns typically constitutes the primary data bottleneck.
- ML-Based Data Processing with Latice:
- Input the raw EBSD patterns into the Latice machine-learning model.
- The model processes the patterns to extract crystallographic orientation data, performing this operation 7.5 times faster than conventional indexing methods.
- Data Compression and Storage:
- The Latice framework outputs the essential crystallographic information in a highly compressed format, reducing storage footprint by ~99% compared to raw pattern storage.
- Data Validation:
- Validate the ML-generated results by comparing a subset of the data against results from conventional indexing to ensure essential physical properties of the system are preserved.
Workflow and Signaling Pathway Diagrams
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Materials and Tools for High-Throughput Workflows
| Item | Function / Application |
|---|---|
| Inorganic Precursor Powders | High-purity starting materials for solid-state synthesis of target compounds [70]. |
| Alumina Crucibles | Containers for holding powder samples during high-temperature reactions in box furnaces [70]. |
| X-ray Diffraction (XRD) Instrument | Primary tool for the non-destructive phase identification and characterization of crystalline synthesis products [70]. |
| Electron Backscatter Diffraction (EBSD) Detector | A detector system mounted on an SEM for quantifying crystallographic microstructures in materials [71]. |
| Machine Learning Models (e.g., for XRD analysis or recipe proposal) | AI algorithms that interpret characterization data (e.g., XRD patterns) or propose synthesis parameters, enabling autonomy and high-throughput decision-making [70]. |
| Active Learning Algorithm (e.g., ARROWS3) | Software that uses thermodynamic data and experimental outcomes to iteratively propose improved synthesis recipes in a closed-loop system [70]. |
Therapeutic Drug Monitoring (TDM) is a cornerstone of personalized medicine, enabling the optimization of drug dosage regimens by measuring drug concentrations in biological fluids to ensure maximal efficacy while minimizing adverse effects [72]. The core principle of TDM involves a continuous cycle of sample collection, preparation, analysis, and clinical decision-making, which can be executed through either manual or automated methodologies [73]. As the demand for high-throughput analysis grows in both clinical and research settings, automated workflows are increasingly being integrated into autonomous experimentation systems [6] [74].
This application note provides a detailed comparative analysis of manual and automated approaches in TDM, framed within the broader context of high-throughput workflow selection for autonomous experimentation research. We present structured quantitative data, detailed protocols, and visual workflow diagrams to guide researchers and drug development professionals in selecting and implementing optimal TDM methodologies for their specific applications.
Comparative Performance Data
The transition from manual to automated methods involves significant changes in operational parameters and performance characteristics. The following tables summarize key quantitative comparisons based on validation studies, including data from an automated workflow for monitoring Cannabidiol (CBD) and its metabolite [75].
Table 1: Precision and Accuracy Comparison for CBD and 7-Hydroxy-CBD Analysis in Human Serum
| Parameter | Method | Analyte | Intraday Precision (%) | Interday Precision (%) | Accuracy Range (%) |
|---|---|---|---|---|---|
| LOQ | Manual | CBD | 4.5 | 6.3 | 111.8 |
| Automated | CBD | 11.5 | 8.4 | 109.3 | |
| Manual | 7-Hydroxy-CBD | 6.5 | 7.8 | 95.4 | |
| Automated | 7-Hydroxy-CBD | 8.2 | 8.1 | 95.4 | |
| QC Low | Manual | CBD | 2.7 | 6.6 | 100.8 |
| Automated | CBD | 3.4 | 5.3 | 87.9 | |
| Manual | 7-Hydroxy-CBD | 2.0 | 7.9 | 105.1 | |
| Automated | 7-Hydroxy-CBD | 3.8 | 5.6 | 103.0 | |
| QC Medium | Manual | CBD | 5.6 | 6.2 | 93.6 |
| Automated | CBD | 4.8 | 6.7 | 93.1 | |
| Manual | 7-Hydroxy-CBD | 2.6 | 7.2 | 94.2 | |
| Automated | 7-Hydroxy-CBD | 4.1 | 6.3 | 94.5 | |
| QC High | Manual | CBD | 1.0 | 5.6 | 92.5 |
| Automated | CBD | 1.5 | 2.4 | 93.3 | |
| Manual | 7-Hydroxy-CBD | 1.3 | 6.8 | 94.4 | |
| Automated | 7-Hydroxy-CBD | 3.7 | 6.5 | 91.9 |
Table 2: Operational and Workflow Characteristics
| Characteristic | Manual Method | Automated Method |
|---|---|---|
| Sample Preparation Time | High (Several hours) | Low (Minutes per plate) |
| Throughput | Low (Limited by technician speed) | High (Parallel processing in 96-well plates) |
| Inter-operator Variability | Significant risk | Minimal to none |
| Liquid Handling Precision | Subject to human error | Highly reproducible |
| Scalability | Challenging for large batches | Excellent for high-volume workflows |
| Initial Investment Cost | Low | High |
| Operational Cost per Sample | Higher (Labor-intensive) | Lower (Reduced labor) |
| Extraction Recovery (%) | CBD: 80-85; Metabolite: 86-92 | CBD: 80-104; Metabolite: 81-92 |
Experimental Protocols
Protocol 1: Manual Sample Preparation for LC-MS/MS Analysis of CBD and 7-Hydroxy-CBD
This protocol is adapted from the manual method used for the quantitative determination of Cannabidiol (CBD) and its active metabolite, 7-hydroxy-CBD, in human serum [75].
Principle: Serum samples undergo manual protein precipitation (PP) to remove proteins and isolate the analytes prior to analysis by Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS).
Materials:
- Biological Sample: Human serum.
- Reagents: Acetonitrile (LC-MS grade), Methanol (LC-MS grade), Internal Standard (e.g., CBD-d3), Deionized Water.
- Equipment: Manual pipettes and tips, Vortex mixer, Centrifuge, Microcentrifuge tubes (1.5-2.0 mL), Filter plates or syringe filters.
Procedure:
- Aliquot and Spike: Pipette 100 µL of human serum into a clean microcentrifuge tube. Add a fixed volume (e.g., 10 µL) of the internal standard working solution.
- Vortex: Mix the sample thoroughly on a vortex mixer for 30-60 seconds.
- Protein Precipitation: Add 300 µL of ice-cold acetonitrile to the sample tube to precipitate serum proteins.
- Vortex and Centrifuge: Vortex the mixture vigorously for 1 minute. Centrifuge at a high speed (e.g., 14,000 × g) for 10 minutes at 4°C to form a compact protein pellet.
- Supernatant Collection: Carefully transfer the clear supernatant (approximately 300 µL) to a new, labeled microcentrifuge tube or a well in a 96-well plate.
- Evaporation and Reconstitution (if required): Evaporate the supernatant to dryness under a gentle stream of nitrogen or using a vacuum concentrator. Reconstitute the dry residue with 100-150 µL of a reconstitution solution (e.g., a water/methanol mixture) compatible with the LC-MS/MS mobile phase.
- Vortex and Transfer: Vortex the reconstituted sample and transfer it to an autosampler vial for LC-MS/MS analysis.
Protocol 2: Automated Sample Preparation for LC-MS/MS Analysis of CBD and 7-Hydroxy-CBD
This protocol describes the automated workflow implemented on a robotic platform, as validated for CBD and 7-hydroxy-CBD [75].
Principle: An integrated robotic liquid handling system automates the key steps of protein precipitation, including solvent dispensing, mixing, centrifugation, and supernatant transfer, directly in a 96-well plate format.
Materials:
- Biological Sample: Human serum.
- Reagents: Acetonitrile (LC-MS grade), Internal Standard (e.g., CBD-d3).
- Equipment: Automated liquid handling platform (e.g., from Tecan, Hamilton, or PerkinElmer) with capabilities for solvent dispensing, pipetting, and plate manipulation. Integrated centrifuge and filtration station. 96-well plates.
Procedure:
- System Priming: Prime the automated liquid handling system with all necessary reagents and solvents according to the manufacturer's instructions.
- Plate Loading: Load a 96-well plate containing the serum samples (100 µL/well) into the deck of the automated platform.
- Internal Standard Addition: The robotic arm dispenses the internal standard solution into each sample well.
- Automated Mixing: The platform mixes the samples, typically by pipette aspiration-dispersion or plate shaking.
- Precipitant Dispensing: The system dispenses a precise volume of ice-cold acetonitrile (e.g., 300 µL) into each well.
- Automated Mixing and Centrifugation: The platform mixes the solution thoroughly and then transfers the entire plate to an integrated centrifuge for centrifugation.
- Filtration and Transfer: Post-centrifugation, the platform automatically performs filtration and transfers the clarified supernatant to a new 96-well collection plate.
- Output: The system produces a 96-well plate ready for direct injection into the LC-MS/MS system, eliminating the need for manual intervention.
Workflow Visualization
The fundamental decision-making process for selecting a TDM methodology, from sample arrival to final analysis, can be conceptualized as a logical pathway. The following diagram illustrates this high-level workflow selection logic.
TDM Workflow Selection Logic
The core operational steps for both manual and automated TDM methods share a common goal but differ significantly in execution. The following diagram provides a comparative view of these procedural pathways.
Manual vs. Automated TDM Process
The Scientist's Toolkit: Research Reagent Solutions
Successful implementation of TDM protocols, whether manual or automated, relies on a set of core reagents and materials. The following table details essential components for setting up a robust TDM analysis.
Table 3: Essential Research Reagents and Materials for TDM
| Item | Function/Description | Application Note |
|---|---|---|
| LC-MS/MS Grade Solvents | High-purity Acetonitrile, Methanol, and Water used in mobile phases and sample preparation. | Minimizes background noise and ion suppression, ensuring optimal instrument sensitivity and reproducibility [75]. |
| Stable Isotope-Labeled Internal Standards | Analytically identical molecules to the drug of interest, but labeled with heavy isotopes (e.g., Deuterium, C-13). | Corrects for analyte loss during sample preparation and for variability in instrument response, critical for quantification accuracy [75]. |
| Certified Reference Standards | Highly characterized and pure samples of the drug and its metabolites. | Used for accurate calibration curve preparation to ensure the validity of concentration measurements [72]. |
| Protein Precipitation Reagents | Solvents like Acetonitrile or Methanol. | Cause the denaturation and precipitation of proteins in biological samples, clarifying the solution for analysis [75]. |
| Solid Phase Extraction (SPE) Cartridges | Cartridges containing sorbent material for selective extraction and purification of analytes. | Provide cleaner extracts than protein precipitation, reducing matrix effects, though they are more complex to automate [72]. |
| 96-Well Plates & Seals | Standardized microplates and adhesive seals. | The standard format for high-throughput automated workflows, enabling parallel processing of dozens of samples [75]. |
The comparative analysis presented in this application note clearly delineates the respective domains of manual and automated TDM methods. Manual sample preparation remains a flexible, low-capital-cost option for low-volume or highly specialized assays. However, automated workflows demonstrate superior performance in key metrics essential for modern drug development and autonomous research: throughput, reproducibility, and scalability [75].
The integration of fully automated TDM protocols into self-driving laboratories represents a paradigm shift. These systems, which integrate artificial intelligence, robotic experimentation, and automated workflows into a closed-loop cycle, are poised to dramatically accelerate scientific discovery [6]. The robust, standardized data generated by automated TDM is the high-quality fuel required for training the AI/machine learning models that drive these autonomous systems [1] [74]. Therefore, the selection of an automated TDM workflow is not merely an operational efficiency gain but a critical strategic enabler for the future of high-throughput, data-driven pharmacological research.
Ensuring Data Integrity and Compliance with Regulatory Standards (e.g., ALCOA+)
In the rapidly evolving field of autonomous experimentation, where artificial intelligence (AI) and robotics enable high-throughput discovery, maintaining data integrity is paramount. The ALCOA+ framework provides the foundational principles for ensuring data reliability, quality, and regulatory compliance throughout the research lifecycle. Originally articulated by the FDA in the 1990s, ALCOA has evolved into ALCOA+ and now ALCOA++ to address modern challenges in data management across clinical trials, biomanufacturing, and materials science [76]. For researchers employing autonomous experimentation systems, integrating these principles directly into automated workflows is essential for producing scientifically valid, reproducible, and regulatory-compliant results.
Autonomous experimentation systems, or "self-driving labs," integrate AI, robotic experimentation, and automation technologies into a continuous closed-loop cycle to conduct scientific experiments with minimal human intervention [6]. These systems can dramatically accelerate chemical synthesis and materials innovation, but they also generate vast amounts of data that must be managed according to rigorous integrity standards. The expansion of data collection tools, including electronic data capture (EDC) systems, wearables, eConsent platforms, and various eSource technologies, makes robust data integrity frameworks even more critical [76]. This application note provides detailed methodologies for implementing ALCOA+ principles within high-throughput autonomous workflows, complete with protocols, visualization, and practical tools for researchers and drug development professionals.
ALCOA+ Framework: Principles and Significance
Core Principles and Evolution
ALCOA+ represents an evolution from the original five ALCOA attributes to a more comprehensive framework that addresses the complete data lifecycle. The principles are defined as follows [76] [77]:
- Attributable: Data must clearly indicate who created or modified it, including the person and/or system involved, with this information retained in metadata with date and time stamps.
- Legible: Data must be readable and reviewable in its original context, with any encoding, compression, or encryption being reversible so information is not lost.
- Contemporaneous: Data should be recorded at the time of the activity with accurately captured date/time set by an external standard.
- Original: The first capture of data or a certified copy created under controlled procedures must be retained.
- Accurate: Records must faithfully represent what occurred, with validated coding, transfers, and interfaces.
- Complete: All data, including metadata, audit trails, and relevant contextual information, must be present to allow reconstruction of events.
- Consistent: Data should be standardized throughout its lifecycle with aligned definitions, units, and sequencing.
- Enduring: Data must remain intact and usable for the entire retention period with suitable formats, backups, and archiving.
- Available: Data should be readily retrievable for monitoring, audits, and inspections whenever required across the retention period.
The progression from ALCOA to ALCOA+ reflects the scientific community's response to increasing regulatory scrutiny and the need for more comprehensive data integrity measures, particularly in pharmaceutical development and clinical research [77].
Regulatory Context and Enforcement Trends
Regulatory agencies including the FDA, EMA, and PIC/S treat ALCOA+ attributes as the minimum data integrity expectation under regulations such as 21 CFR 211.68 (controls of automated systems) and 211.100 (production/process controls) [77]. Analyses of FDA enforcement actions indicate significant focus on data integrity, with nearly 80% of data integrity-related warning letters issued since 2008 occurring during 2014-2018 [76]. More recent analysis of 2022-2024 Warning Letters shows continued spikes in citations for issues including unsecured shared network drives, manual overwrite of HPLC raw data files, unvalidated true-copy processes, and missing audit-trail reviews [77].
For autonomous experimentation research, these regulatory expectations translate to specific technical requirements. Systems must implement unique user IDs (no shared accounts), appropriate access controls, validated audit trails, automatic timestamp capture synchronized to external standards, and secure data retention mechanisms [76]. The following table summarizes key ALCOA+ requirements and their implications for autonomous research systems:
Table 1: ALCOA+ Requirements for Autonomous Experimentation Systems
| ALCOA+ Principle | Technical Implementation | Autonomous System Consideration |
|---|---|---|
| Attributable | Unique user IDs, access controls, audit trails | System must log which AI agent or robotic component generated data |
| Contemporaneous | Automated timestamps synced to NTP/UTC | Robotic systems must timestamp all operations automatically |
| Original | Raw data retention, certified copy procedures | Preserve dynamic source data (e.g., sensor waveforms, event logs) |
| Complete | Metadata retention, reconstruction capability | Capture all experimental parameters and environmental conditions |
| Enduring | Suitable formats, backups, archiving | Ensure data readability independent of specific hardware |
| Available | Searchable storage, indexed repositories | Implement retrieval pathways for high-volume experimental data |
Integration of ALCOA+ into Autonomous Experimentation Workflows
Workflow Selection Framework for Data Integrity
Autonomous experimentation systems require frameworks that enable the design and selection of data collection workflows that inherently support ALCOA+ principles. A promising approach involves a value-driven workflow selection process where workflows are evaluated based on the quality and actionability of information they generate [1]. This framework follows the progression:
Workflow → Information → Value
Where the value of information is proportional to its quality and actionability [1]. For ALCOA+ compliance, this means selecting workflows that not only generate high-quality information but also do so in a manner that satisfies regulatory data integrity requirements.
The framework employs a two-stage selection process: (1) a fast search over possible user-defined workflows to filter for high-quality options, and (2) a fine search over these high-quality workflows to select the optimal workflow based on user-defined objectives [1]. This approach enables autonomous systems to dynamically identify high-value workflows that generate structured materials information while maintaining data integrity.
Table 2: Workflow Selection Criteria Balancing Information Value and Data Integrity
| Selection Criterion | Information Quality Aspect | ALCOA+ Integration |
|---|---|---|
| Accuracy | Faithful representation of ground truth | Implement calibrated instruments, validated transfers |
| Precision | Low variance in repeated measurements | Standardized procedures, consistent units |
| Completeness | All necessary data points present | Capture all metadata, prevent deletions |
| Timeliness | Data available when needed | Automated recording, real-time capture |
| Traceability | Lineage from source to use | Audit trails, version control |
| Actionability | Useful for decision-making | Available when needed, legible format |
Implementation Protocol: ALCOA+ in Autonomous Characterization
The following detailed protocol implements ALCOA+ principles for autonomous materials characterization, based on the AutoSAS framework for automated data analysis in high-throughput experimentation [78].
Protocol Title: Implementation of ALCOA+ Principles in Autonomous Small-Angle Scattering (SAS) Characterization
Objective: To enable fully autonomous structural characterization while maintaining complete ALCOA+ compliance throughout the data collection, analysis, and interpretation pipeline.
Materials and Equipment:
- Autonomous Formulation Laboratory platform with X-ray or neutron scattering capability
- Sample handling robotics with liquid dispensing systems
- Data analysis server with AutoSAS software package
- Network Time Protocol (NTP) synchronized clock system
- Secure data storage with automated backup
- Electronic Laboratory Notebook (ELN) system with audit trail functionality
Procedure:
Experimental Planning Phase
- Define candidate models for expected structures in human-readable format
- Document all initial parameters in ELN with timestamp and user attribution
- Set validation criteria for model selection based on information-theoretic measures
Automated Data Collection
- Synchronize all instrument clocks to NTP server prior to initiation
- Implement unique instrument identifiers for all data generation points
- Capture raw data formats with complete metadata (temperature, concentration, etc.)
- Generate contemporaneous logs of all robotic operations and sample movements
Data Processing and Analysis
- Apply AutoSAS combinatorial fitting to raw data using predefined models
- Execute model selection based on balanced criteria (quality and complexity)
- Preserve original fitted data alongside analysis results
- Generate complete audit trail of all processing steps
Result Interpretation and Storage
- Document classification results with confidence metrics
- Store original raw data in enduring formats with appropriate backups
- Ensure all result files are searchable and indexed for availability
- Verify data consistency across multiple analytical techniques
Validation: The protocol should be validated by comparing autonomous results with expert-human analysis for a standard material system. Success is achieved when the autonomous system identifies known structural transitions and discovers new boundaries not previously characterized, while maintaining complete ALCOA+ compliance throughout the process [78].
Visualization of ALCOA+ Workflows
To illustrate the integration of ALCOA+ principles into autonomous experimentation workflows, the following diagram maps the data integrity checkpoints throughout a typical autonomous research cycle:
Diagram 1: ALCOA+ checkpoints in an autonomous research workflow. The dashed green lines indicate where specific data integrity principles are verified throughout the experimental cycle.
The workflow demonstrates how each stage of autonomous experimentation incorporates specific ALCOA+ verification points, ensuring data integrity is maintained throughout the research lifecycle rather than being treated as a final compliance check.
Research Reagent Solutions for Data Integrity
Implementing robust data integrity practices requires both technical solutions and methodological approaches. The following table details essential research reagents and tools that support ALCOA+ compliance in autonomous experimentation systems:
Table 3: Research Reagent Solutions for ALCOA+ Compliance
| Solution Category | Specific Tools/Platforms | ALCOA+ Function | Implementation Example |
|---|---|---|---|
| Electronic Lab Notebooks | Benchling, SciNote, RSpace | Attributable, Contemporaneous | Automated recording of experimental parameters with user attribution and timestamps |
| Laboratory Information Systems | LIMS, CDS, SDMS | Complete, Consistent | Centralized data management with standardized formats and complete metadata capture |
| Automated Audit Trail Systems | Custom Python scripts, PharmaCM | Attributable, Complete | Log all data accesses, modifications, and processing steps with user and timestamp |
| Time Synchronization Tools | NTP servers, network time clients | Contemporaneous | Ensure all instruments and systems use synchronized time sources |
| Data Format Standards | AnIML, ISA-TAB, Allotrope | Legible, Consistent | Standardized data formats that remain readable independent of original software |
| Secure Storage Systems | Cloud archives, institutional repositories | Enduring, Available | Automated backups with disaster recovery and retrieval capabilities |
| Certified Copy Tools | Validated PDF generators, checksum utilities | Original, Accurate | Create verified copies of original data without altering content |
| Electronic Signatures | 21 CFR Part 11-compliant systems | Attributable | Unique user authentication for all critical data entries and modifications |
These tools form the technical foundation for maintaining data integrity in high-throughput autonomous environments. When selecting and implementing these solutions, researchers should prioritize systems with validated functionality, appropriate security controls, and interoperability with existing instrumentation [79].
Case Study: Autonomous Materials Discovery with ALCOA+ Compliance
A notable implementation of ALCOA+-compliant autonomous experimentation is the A-Lab platform for solid-state materials synthesis [6]. This case study demonstrates how data integrity principles can be integrated into each stage of a fully autonomous research cycle:
Background: A-Lab is an autonomous solid-state synthesis platform powered by AI tools and robotics, designed to synthesize and characterize novel inorganic materials predicted by computational models [6].
ALCOA+ Integration:
Attributable Data Generation
- All synthesis actions logged with specific robotic component identifiers
- AI decision points recorded with model versions and parameters
- Each characterization result linked to specific synthesis attempt
Contemporaneous Recording
- Automated timestamps for all robotic operations synchronized to NTP
- Real-time data capture from XRD and other characterization tools
- Immediate logging of analysis results upon generation
Original Data Preservation
- Raw XRD patterns stored in original instrument format
- Synthesis parameter logs maintained without modification
- Certified copies created for data transfer between systems
Complete Data Capture
- All synthesis attempts recorded, including failed experiments
- Full metadata on precursors, temperatures, and processing conditions
- Environmental conditions (humidity, temperature) logged throughout
Enduring Storage
- Data archived in multiple formats to ensure long-term readability
- Regular backups to geographically separate locations
- Migration plans for data format obsolescence
Results: Over 17 days of continuous operation, A-Lab successfully synthesized 41 of 58 target materials while maintaining complete data integrity throughout the process [6]. The system not only reproduced known synthesis pathways but also discovered new structural transitions not previously identified, demonstrating that rigorous data integrity practices can coexist with exploratory autonomous research.
The integration of ALCOA+ principles into autonomous experimentation systems is both a regulatory necessity and a scientific opportunity. By designing data integrity into high-throughput workflows from the outset, researchers can accelerate discovery while ensuring the reliability and credibility of their results. The frameworks, protocols, and tools outlined in this application note provide a roadmap for implementing these practices across diverse research domains.
As autonomous laboratories evolve, several emerging trends will shape the future of data integrity in high-throughput research. These include the development of foundation models trained across different materials and reactions to enhance AI generalization, the implementation of standardized data formats to address data scarcity and inconsistency, and the creation of modular hardware architectures with standardized interfaces for flexible experimental configurations [6]. Additionally, LLM-based autonomous agents show promise for enhancing experimental planning and execution while maintaining comprehensive data integrity through transparent decision-making processes [6].
For researchers embarking on autonomous experimentation initiatives, the key success factors include: (1) mapping data flows and systems to ALCOA+ attributes during the design phase, (2) implementing automated audit trail reviews focused on critical data, (3) ensuring time synchronization across all instruments, and (4) establishing clear roles and access controls so that no single party has exclusive control over research data [76]. By adopting these practices, research organizations can build autonomous experimentation platforms that are not only scientifically productive but also regulatory-ready and data-integrity assured.
Conclusion
The strategic selection and optimization of high-throughput workflows are fundamental to unlocking the full potential of autonomous experimentation. By integrating the principles outlined—from a value-driven foundational framework to robust validation protocols—research organizations can dramatically accelerate discovery cycles. The convergence of AI, advanced robotics, and hyperautomation points toward a future of increasingly intelligent, self-correcting labs. For biomedical and clinical research, this evolution promises not only faster development of therapies but also more predictive biology through human-relevant models and standardized, high-quality data, ultimately enabling more personalized and effective patient treatments.
References
- 1. A Framework for the Optimal Selection of High-Throughput ... [https://link.springer.com/article/10.1007/s40192-022-00280-5]
- 2. Autonomous experimentation systems for materials ... [https://www.sciencedirect.com/science/article/pii/S2590238521003064]
- 3. Autonomous Experimentation and Self-Driving Labs for ... [https://www.nae.edu/340966/Autonomous-Experimentation-and-SelfDriving-Labs-for-Materials-Synthesis-Using-Deposition-Techniques]
- 4. Development of Standards to Support a Modular and ... [https://www.nist.gov/programs-projects/development-standards-support-modular-and-autonomous-laboratory-ecosystem]
- 5. [2206.07108v1] A Framework for the Optimal Selection for... [https://arxiv.org/abs/2206.07108v1]
- 6. Artificial intelligence-driven autonomous laboratory for ... [https://www.oaepublish.com/articles/cs.2025.66]
- 7. High-Throughput Labs: The Future of Testing and Innovation [https://www.monolithai.com/blog/high-throughput-labs-future-of-testing]
- 8. The Rise of Autonomous Labs in Life Science [https://www.sartorius.com/en/company/newsroom/blog/the-rise-of-autonomous-labs-in-life-science-1771962]
- 9. A High-Throughput Workflow to Analyze Sequence ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11580747/]
- 10. High throughput process development workflow with ... [https://www.sciencedirect.com/science/article/pii/S0021967319302432]
- 11. A rapid methods development workflow for high-throughput ... [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0211582]
- 12. US AI Regulation 2025: What Businesses Must Do [https://digital.nemko.com/news/us-ai-regulation-landscape-2025]
- 13. How AI and Automation Are Changing Drug Discovery [https://bellbrooklabs.com/how-ai-and-automation-are-changing-drug-discovery/?srsltid=AfmBOopCgJcp1UC38A_25FiBt5Py5Z_n7JON4OMJX_WWlRxTPKBZ2xU9]
- 14. Advancing automation in high - throughput screening: Modular... [https://pubmed.ncbi.nlm.nih.gov/35304338/]
- 15. An Overview of High Screening | The Scientist Throughput [https://www.the-scientist.com/an-overview-of-high-throughput-screening-71561]
- 16. opentrons.com/applications/hts/ drug -screening [https://opentrons.com/applications/hts/drug-screening]
- 17. 12 Best Data Quality Tools for 2025 [https://lakefs.io/data-quality/data-quality-tools/]
- 18. - High target throughput using a fully automated... drug discovery [https://pubs.rsc.org/en/content/articlelanding/2024/sc/d3sc05937e]
- 19. Optimal decision-making in high-throughput virtual ... [https://www.sciencedirect.com/science/article/pii/S2666389923002672]
- 20. 2025 Data Labeling Platform Trends: Tools, Workflows ... [https://encord.com/blog/data-labeling-platform-trends/]
- 21. 2025 Workflow Automation Trends: Key Statistics and ... [https://psglobalconsulting.com/blog/2025-workflow-automation-trends-key-statistics-and-insights-for-success]
- 22. Development of the autonomous lab system to support ... [https://www.nature.com/articles/s41598-025-89069-y]
- 23. Best Tools for Data Workflow Automation in 2025 [https://mammoth.io/blog/best-tools-for-data-workflow-automation-in-2025/]
- 24. A fully automated high-throughput workflow for 3D-based ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7609049/]
- 25. Automated Powder Dispensing - CHRONECT Workstations XPR [https://www.palsystem.com/en/workflow-solutions/automated-powder-dispensing-and-processing/]
- 26. Automate Powder-Liquid Prep with Precision [https://chronect.trajanscimed.com/xpr-powder-liquid-workstation]
- 27. Robotic dispensing system (CHRONECT XPR) [https://www.biorender.com/icon/robotic-dispensing-system-chronect-xpr-927]
- 28. A Practical Guide on Low-Code Workflow Automation [https://www.integrate.io/blog/low-code-workflow-automation-a-practical-guide/]
- 29. Low Code Workflow Automation [https://www.kognitos.com/blog/low-code-workflow-platforms/]
- 30. Modular Platforms for Flexible Bioprocessing Applications [https://ritaibioreactor.com/bioprocessing-applications/]
- 31. Low Code Architecture: A Comprehensive Guide [https://www.esystems.fi/en/blog/low-code-architecture-comprehensive-guide]
- 32. Localization, inspection, and reasoning (LIRA) module for ... [https://www.nature.com/articles/s42004-025-01770-1]
- 33. Top low‑code AI workflow automation tools [https://www.vellum.ai/blog/top-low-code-ai-workflow-automation-tools]
- 34. 18 Low-Code Application Platforms 2026: Comparison & ... [https://www.eleken.co/blog-posts/low-code-application-platforms]
- 35. Low Code Platforms Comparison: Making Informed Choices [https://www.nected.ai/us/blog-us/low-code-platforms-comparison]
- 36. Automation Revolutionizes High Throughput ... [https://chronect.trajanscimed.com/news/high-throughput-experimentation-hte]
- 37. Development of High-Throughput Experimentation ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11099536/]
- 38. The integration of artificial intelligence and high-throughput ... [https://www.sciencedirect.com/science/article/abs/pii/S1004954125001831]
- 39. What are Cross-Functional Teams? — updated 2025 | IxDF [https://www.interaction-design.org/literature/topics/cross-functional-teams?srsltid=AfmBOor1cVogNZqasdn99FAT8KGAE-k1BIHlItxlAuS4-RUXIJqLmyXu]
- 40. What is hyperautomation? | Definition and benefits [https://www.sap.com/products/technology-platform/process-automation/what-is-hyperautomation.html]
- 41. What is Hyperautomation? A Guide [https://www.automationanywhere.com/rpa/hyperautomation]
- 42. Hyperautomation - Fast Complete Process Automation [https://www.uipath.com/rpa/hyperautomation]
- 43. Hyperautomation vs RPA: A guide for MSPs [https://www.connectwise.com/blog/hyperautomation-vs-rpa]
- 44. The Role of AI in Drug Discovery: Challenges, Opportunities ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10302890/]
- 45. Artificial Intelligence for Drug Development [https://www.fda.gov/about-fda/center-drug-evaluation-and-research-cder/artificial-intelligence-drug-development]
- 46. What Is Hyperautomation? [https://www.oracle.com/cloud/hyperautomation/]
- 47. Automating drug discovery [https://www.nature.com/articles/nrd.2017.232]
- 48. How do you identify bottlenecks? Here are three ... [https://www.workato.com/the-connector/identify-bottlenecks-in-a-process/]
- 49. Workflow automation in 2025: Everything you need to know ... [https://www.xurrent.com/blog/workflow-automation-ai-business-efficiency-guide]
- 50. How To Eliminate Bottlenecks in Manufacturing in 2025 [https://throughput.world/blog/bottlenecks-in-manufacturing/]
- 51. How to Fix the Most Common Workflow Bottlenecks [https://gravityflow.io/articles/the-most-common-workflow-bottlenecks-and-how-to-fix-them/]
- 52. Quantitative Data Analysis: Methods, Examples, and Tools [https://www.quadratichq.com/blog/quantitative-data-analysis-methods-examples-and-tools]
- 53. Top 6 Visualizations for Quantitative Data Analysis Methods [https://chartexpo.com/blog/quantitative-data-analysis-methods]
- 54. Few-Shot Learning: How AI Learns Faster with Less Data [https://itrexgroup.com/blog/few-shot-learning-how-ai-learns-faster-with-less-data/]
- 55. How Synthetic Data & AI are Surging Cybersecurity in 2025 [https://www.cotelligent.com/resources/synthetic-data-and-ai-in-cybersecurity-2025-188]
- 56. Boost the Modular System with Configuration Design [https://www.modularmanagement.com/blog/boost-the-modular-system-with-configuration-design]
- 57. Developing modular software: Top strategies and best ... [https://vfunction.com/blog/modular-software/]
- 58. Modular software architecture – improves scalability🤔 [https://selleo.com/blog/how-does-modular-software-architecture-improve-scalability]
- 59. Guidance for robustness/ruggedness tests in method ... [https://www.sciencedirect.com/science/article/abs/pii/S073170850000529X]
- 60. Establishing Manufacturing KPIs for Continuous Improvement [https://www.dataparc.com/blog/establishing-manufacturing-kpis-for-continuous-improvement/]
- 61. KPI Dashboards: Comprehensive Guide to Effective Tracking [https://www.simplekpi.com/Blog/KPI-Dashboards-a-comprehensive-guide]
- 62. Process validation and screen reproducibility in high ... [https://pubmed.ncbi.nlm.nih.gov/19171922/]
- 63. Assay Establishment and Validation of a High-Throughput ... [https://www.sciencedirect.com/science/article/pii/S2472555222071490]
- 64. The High-Throughput Screening Transformation in Modern ... [https://www.pharmasalmanac.com/articles/the-high-throughput-screening-transformation-in-modern-drug-development]
- 65. What is Throughput in Performance Testing? A Complete Guide [https://abstracta.us/blog/performance-testing/what-is-throughput-in-performance-testing/]
- 66. High-throughput computing and workflows - Docs CSC [https://docs.csc.fi/computing/running/throughput/]
- 67. Assessing Reproducibility of High-throughput Experiments ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9039958/]
- 68. Measuring the ROI of Workflow Automation [https://www.cxtoday.com/contact-center/measuring-the-roi-of-workflow-automation/]
- 69. From Hunches to Hard Data: Measuring ROI for Workflow ... [https://decisions.com/from-hunches-to-hard-data-measuring-roi-for-workflow-automation/]
- 70. An autonomous laboratory for the accelerated synthesis of ... [https://www.nature.com/articles/s41586-023-06734-w]
- 71. New paper: Latice - a machine-learning approach to speed ... [https://www.linkedin.com/posts/po-yen-tung_cellreportsphysicalscience-materialsscience-activity-7378910643120250880-i_y_]
- 72. Overview of therapeutic drug monitoring and clinical practice [https://www.sciencedirect.com/science/article/abs/pii/S0039914023007476]
- 73. How Therapeutic Drug Monitoring Works — In One Simple ... [https://www.linkedin.com/pulse/how-therapeutic-drug-monitoring-works-one-simple-xbavf]
- 74. high-throughput technologies and automated workflows to ... [https://www.sciencedirect.com/science/article/pii/S0958166925000643]
- 75. Automated Workflow for High-Throughput LC–MS/MS ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12295711/]
- 76. The ALCOA++ Principles for Data Integrity in Clinical Trials [https://www.quanticate.com/blog/alcoa-principles]
- 77. ALCOA Data-Integrity Principles: A Complete 2025 Guide [https://redica.com/data-integrity-and-alcoa/]
- 78. AutoSAS: A new human-aside-the-loop paradigm for ... [https://pubmed.ncbi.nlm.nih.gov/40860982/]
- 79. Free Download Research Data Integrity Assurance Template [https://www.meegle.com/en_us/advanced-templates/laboratory_operations/research_data_integrity_assurance_template]