Breaking Through the Kinetic Barrier: AI-Driven Strategies to Overcome Sluggish Reactions in Autonomous Synthesis
Sluggish reaction kinetics present a critical bottleneck in autonomous synthesis, hindering the discovery and manufacturing of novel materials and pharmaceuticals.
Breaking Through the Kinetic Barrier: AI-Driven Strategies to Overcome Sluggish Reactions in Autonomous Synthesis
Abstract
Sluggish reaction kinetics present a critical bottleneck in autonomous synthesis, hindering the discovery and manufacturing of novel materials and pharmaceuticals. This article synthesizes the latest advances in artificial intelligence and robotic laboratories that are overcoming these kinetic limitations. We explore the foundational causes of kinetic barriers, detail cutting-edge methodological solutions from Bayesian optimization to active learning, provide actionable troubleshooting frameworks for experimental optimization, and validate these approaches through comparative analysis of real-world case studies. Tailored for researchers and drug development professionals, this resource provides a comprehensive roadmap for accelerating discovery timelines and improving the success rates of autonomous synthesis platforms in biomedical research.
Understanding the Kinetic Bottleneck: Why Sluggish Reactions Halt Autonomous Discovery
Defining Sluggish Kinetics in Solid-State and Solution-Phase Synthesis
FAQ: Troubleshooting Sluggish Kinetics
What are sluggish kinetics and how do I identify them in my synthesis?
Sluggish kinetics refer to reaction rates that are impractically slow, often halting the formation of a target material or significantly extending the synthesis time. This is a common barrier in both solid-state and solution-phase synthesis.
| Synthesis Type | Key Indicator of Sluggish Kinetics | Common Experimental Observation |
|---|---|---|
| Solid-State Synthesis | Reaction steps with low thermodynamic driving forces [1]. | A target material is not obtained even after extensive heating, or the reaction yield remains low despite seemingly optimal conditions. |
| Solution-Phase Synthesis | A slow rate of crystallization or phase separation [2] [3]. | A supersaturated solution remains for a long period without precipitating the desired crystalline product, or a polymer solution forms a gel-like network that separates slowly over many hours [3]. |
What are the primary causes of sluggish kinetics in solid-state synthesis?
In solid-state synthesis, the main cause is often sluggish reaction kinetics at the atomic level, where the driving force to form the target material from its intermediates is very small (e.g., less than 50 meV per atom) [1]. This low driving force results in extremely slow solid-state diffusion and reaction rates, preventing the system from reaching the thermodynamic equilibrium state within a practical timeframe.
How can sluggish kinetics be overcome in solid-state synthesis?
Advanced research platforms like the A-Lab use active learning algorithms grounded in thermodynamics to overcome this. The system identifies and avoids synthesis pathways that lead to intermediate compounds with a small driving force to form the final target. Instead, it prioritizes alternative precursor sets or reaction routes that have a much larger driving force (e.g., 77 meV per atom vs. 8 meV per atom), which can increase target yield by over 70% [1].
What solution-phase strategies can mitigate sluggish kinetics?
A key strategy is engineering material morphology to enhance transport and reaction pathways. For example, synthesizing nanoporous metal structures creates a high surface area and a percolating network that facilitates atomic or molecular diffusion. This has been shown to enhance sorption kinetics, as opposed to the sluggish kinetics observed in bulk or core-shell nanoparticle materials [4]. Furthermore, defect engineering, such as introducing oxygen vacancies into a catalyst, can improve electron transfer ability and accelerate key redox cycles, leading to a fast and deep degradation of contaminants within minutes [5].
Are there experimental techniques to better understand fast initial kinetics?
Yes. Traditional solid-state synthesis is often slow and limited by transport, but recent approaches using custom-designed reactors with in-situ X-ray scattering can capture the earliest stages of a reaction. These studies have revealed that significant product formation can occur within seconds to minutes under high temperatures, a period with fast initial kinetics that was previously overlooked. Analyzing these regimes with models like Avrami kinetics provides characteristic dimensionalities for each transformation step [6].
Research Reagent Solutions
The following table details key materials and their functions for experiments focused on overcoming sluggish kinetics.
| Reagent/Material | Function in Experiment |
|---|---|
| Lithium Naphthalenide Solution | A highly reductive organic solvent used in the synthesis of nanoporous Mg via reduction-induced decomposition, avoiding harsh corrosive environments [4]. |
| Oxygen Vacancies Enriched Biochar Catalyst (e.g., Mo-Co-ECM) | A heterogeneous catalyst where oxygen vacancies enhance electron transfer ability and accelerate the Co³⁺/Co²⁺ cycle, enabling rapid activation of oxidants like peroxymonosulfate for deep contaminant degradation [5]. |
| Precursor Powders (Various Oxides, Phosphates) | Starting materials for solid-state synthesis. Their selection is critical and can be optimized by machine learning models to avoid low-driving-force intermediates [1]. |
| In-situ X-ray Scattering Reactor | A custom reactor that enables real-time analysis of the earliest stages of a solid-state reaction, allowing researchers to capture and model fast initial kinetics [6]. |
Experimental Protocol: Overcoming Sluggish Kinetics via Active Learning
This methodology is adapted from the workflow of the A-Lab for the solid-state synthesis of novel inorganic powders [1].
1. Problem Identification and Initial Recipe Generation
- Input: A thermodynamically stable target material identified from computational screening (e.g., from the Materials Project database).
- Action: Generate up to five initial solid-state synthesis recipes using a natural-language model trained on historical literature. This model assesses "target similarity" to propose effective precursors and heating temperatures based on analogous known materials.
2. Robotic Execution and Analysis
- Action: The lab's robotic system automatically dispenses and mixes precursor powders, loads them into a furnace for heating, and then grinds and characterizes the resulting product via X-ray diffraction (XRD).
- Analysis: Machine learning models analyze the XRD patterns to identify phases and quantify the yield (weight fraction) of the target material.
3. Active Learning Optimization Cycle
- Condition: If the initial recipes fail to produce >50% yield of the target, an active learning algorithm (e.g., ARROWS³) is activated.
- Action: The algorithm uses two key principles:
- It leverages a growing database of observed pairwise solid-state reactions to infer pathways and prune the search space of ineffective recipes.
- It uses thermodynamic data to propose new synthesis routes that avoid intermediates with a small driving force to form the target, instead favoring pathways with larger driving forces.
- Iteration: The lab performs these new, optimized recipes robotically, repeating the cycle until the target is successfully synthesized or all options are exhausted.
Workflow Diagram
Experimental Protocol: Fast Kinetics Analysis with In-Situ Scattering
This protocol outlines how to study the fast initial kinetics of solid-state reactions, often missed by traditional methods [6].
1. Reactor Setup and Calibration
- Equipment: Utilize a custom-designed reactor that allows for rapid heating and is integrated with an in-situ X-ray scattering (or diffraction) setup.
- Calibration: Ensure precise calibration of temperature control and the X-ray detector to accurately correlate time, temperature, and scattering signal.
2. Reaction Initiation and Data Collection
- Loading: Load a well-mixed precursor powder (e.g., TiO₂ and Li₂CO₃) into the reactor.
- Initiation: Rapidly heat the sample to the desired reaction temperature (e.g., 700-750°C for fast kinetics or a lower temperature like 482°C for comparison).
- Data Collection: Immediately begin collecting time-resolved X-ray scattering patterns with a high acquisition rate (on the order of seconds) to capture the earliest stages of the reaction.
3. Data Analysis and Kinetic Modeling
- Phase Identification: Analyze the sequential scattering patterns to identify the emergence and evolution of crystalline phases, including intermediates and the final product.
- Kinetic Modeling: Fit the time-dependent phase fraction data to a kinetic model, such as the Avrami model, to extract characteristic parameters (e.g., Avrami exponents) that provide insight into the reaction mechanism and dimensionality.
Kinetics Analysis Diagram
Economic and Temporal Costs of Kinetic Barriers in Drug Development Pipelines
Frequently Asked Questions (FAQs)
Q1: What are the most significant economic impacts of kinetic barriers in drug development? The primary economic impact is the cost of clinical failure. Developing a new drug takes 10–15 years and costs $1–2 billion on average [7]. A staggering 90% of drug candidates that enter clinical trials fail, with approximately 40-50% failing due to a lack of clinical efficacy, often a direct consequence of poor pharmacokinetics and insufficient drug exposure at the target site [7]. Each day a drug is in development costs approximately $37,000 in direct out-of-pocket expenses, plus an estimated $1.1 million in lost opportunity [8].
Q2: Why do kinetic barriers cause failures late in the pipeline rather than early? Many kinetic barriers are not detected in standard preclinical models. Compounds are often optimized for high in vitro potency and specificity, but without equal emphasis on their structure–tissue exposure/selectivity relationship (STR) [7]. Discrepancies in biology between animal models and human disease, as well as poor prediction of human efficacy from animal models, mean that problems with tissue exposure and selectivity often only become apparent in costly Phase II clinical trials, the stage where lack of efficacy is most frequently revealed [7] [9].
Q3: How can I optimize a reaction to improve the drug-like properties of a lead compound? Reaction optimization is the systematic process of adjusting experimental conditions to improve outcomes like yield, selectivity, and rate [10]. Key variables to optimize include solvent, temperature, catalyst, time, and stoichiometry [10]. A step-by-step approach is:
- Choose a target metric (e.g., yield).
- Select 2–3 key variables to test based on literature.
- Design a small matrix of experiments.
- Run experiments and record results.
- Analyze trends and iterate [10]. Tools like Bayesian optimization algorithms can help guide this process more efficiently by learning from each experimental result [11] [10].
Q4: What is the STAR framework and how can it guide candidate selection? The Structure–Tissue Exposure/Selectivity–Activity Relationship (STAR) is a framework proposed to improve drug optimization by classifying candidates into four categories, balancing potency, tissue exposure, and clinical dose [7]. The following table summarizes the STAR classification system for drug candidates:
| Class | Specificity/Potency | Tissue Exposure/Selectivity | Clinical Dose & Outcome | Recommendation |
|---|---|---|---|---|
| Class I | High | High | Low dose; superior efficacy/safety | High success rate; prioritize [7]. |
| Class II | High | Low | High dose; high toxicity | High risk; cautious evaluation [7]. |
| Class III | Adequate | High | Low dose; manageable toxicity | Often overlooked; promising [7]. |
| Class IV | Low | Low | Inadequate efficacy/safety | Terminate early [7]. |
Troubleshooting Guides
Problem: Lead candidate shows high in vitro potency but fails in vivo due to poor tissue exposure.
Potential Causes and Solutions:
- Cause 1: Over-reliance on Structure-Activity Relationship (SAR) alone.
- Solution: Integrate Structure–Tissue Exposure/Selectivity Relationship (STR) into the early optimization process. Use the STAR framework to classify compounds and select those with balanced properties (e.g., Class I or III) rather than just high potency (Class II) [7].
- Cause 2: Inadequate blood-brain barrier (BBB) penetration for CNS targets.
- Solution: Implement high-throughput in vitro BBB permeability models early in discovery to identify compounds that cannot reach the CNS target. This allows for early structural modification to improve intrinsic permeability or reduce interaction with efflux pumps like P-glycoprotein [8].
- Cause 3: Poor drug-like properties leading to unfavorable pharmacokinetics.
- Solution: Rigorously apply early Absorption, Distribution, Metabolism, Excretion, and Toxicity (ADMET) screening. Adhere to guidelines like Lipinski's Rule of 5 (Molecular Weight <500, cLogP <5, H-bond donors ≤5, H-bond acceptors ≤10) to prioritize compounds with a higher probability of oral bioavailability [8].
Problem: Translational failure—efficacy in animal models does not predict efficacy in human clinical trials.
Potential Causes and Solutions:
- Cause 1: The wrong animal model was used for the human disease.
- Solution: Critically evaluate the predictive validity of animal models. A failure rate of 60-70% in Phase II trials is consistent across therapeutic areas, including those where animal models are considered predictive, like cardiovascular disease [9]. Invest in developing better humanized models or human cell-based systems.
- Cause 2: The pharmacodynamic (PD) endpoint measured in animals does not correlate with the clinical endpoint.
- Solution: Ensure that the endpoints used in preclinical studies are as close as possible to the true clinical outcome. For example, a drug designed to protect the heart from ischemia-reperfusion damage must show improvement in hard endpoints like infarct size, not just surrogate markers [9].
- Cause 3: Species-specific differences in drug metabolism or target biology.
- Solution: Conduct thorough in vitro studies using human enzymes and cells (e.g., hepatocytes, recombinant enzymes) to identify significant metabolic differences early. This was a key lesson from the failure of the vasopressin V1 receptor antagonist, which was highly effective in rats but not in humans due to species differences in the receptor [9].
The Scientist's Toolkit: Key Research Reagent Solutions
The following table lists essential materials and their functions for overcoming kinetic barriers in drug development.
| Reagent/Material | Function |
|---|---|
| Immortalized Cell Lines (e.g., brain capillary endothelial cells) | Form the basis of high-throughput in vitro models to study kinetic parameters like blood-brain barrier penetration [8]. |
| Primary Cultured Cells (e.g., bovine, porcine, or rat brain capillary endothelial cells) | Used in co-culture with astrocytes to create more physiologically relevant models for predicting tissue distribution and toxicity [8]. |
| P-glycoprotein (P-gp) Inhibitors | Used in assays to determine if a drug candidate is a substrate for efflux pumps, which can limit its tissue penetration and efficacy [8]. |
| hERG Assay Kits | Early in vitro assessment of a compound's potential to cause cardiotoxicity, a common reason for failure due to toxicity [7] [8]. |
| CYP450 Enzyme Assays | Determine the metabolic stability of a drug candidate and its potential for drug-drug interactions, key ADMET properties [8]. |
| Bayesian Optimization Software (e.g., ChemOS, Phoenics) | Algorithmic software that guides autonomous experimentation by proposing optimal conditions to test, dramatically accelerating reaction and formulation optimization [11]. |
Experimental Protocols & Workflow Visualization
Protocol 1: Autonomous Workflow for Optimizing Reaction Kinetics and Drug-Like Properties
This protocol outlines a closed-loop workflow for autonomous experimentation, which can be applied to optimize synthetic routes for key drug intermediates or to formulate compounds for improved solubility and bioavailability [11].
- Design: An experiment planning algorithm (e.g., a Bayesian optimizer) suggests a set of initial experimental conditions based on pre-defined objectives (e.g., maximize yield, minimize byproducts) and prior knowledge [11].
- Make: An automated synthesis platform (e.g., a robotic fluid-handling system) executes the suggested experiments, handling liquid reagents and performing reactions [11].
- Test: The reaction products are automatically transferred to an analysis platform (e.g., HPLC, MS) for characterization. The results (yield, purity) are recorded in a standardized database [11].
- Analyze: The algorithm learns from the new results, updating its internal model. It then uses this refined model to design the next, more optimal set of experiments, closing the loop [11].
The entire process is orchestrated by software like ChemOS, which is hardware-agnostic and manages scheduling, machine learning, and data storage [11]. This approach increases throughput, reproducibility, and the quality of data collected, while freeing researchers for higher-level tasks [11].
Diagram: Autonomous Optimization Cycle
Protocol 2: Early-Stage ADMET and Tissue Exposure Screening
This protocol is designed for the lead optimization stage to eliminate candidates with poor kinetic properties before they enter costly development phases [8].
- In Vitro Permeability Assessment:
- Use Caco-2 cell monolayers or artificial membranes (PAMPA) to model human intestinal absorption.
- For CNS targets, use a validated in vitro BBB model (e.g., a co-culture of brain endothelial cells and astrocytes).
- Test compounds with and without specific inhibitors of efflux transporters like P-gp to identify substrates.
- Metabolic Stability Assay:
- Incubate the drug candidate with liver microsomes (human and preclinical species) or hepatocytes.
- Measure the half-life (t₁/₂) of the parent compound over time. A t₁/₂ > 45–60 minutes in human microsomes is generally preferred [7].
- Tissue Binding Assessment:
- Determine the compound's plasma protein binding and tissue homogenate binding using methods like equilibrium dialysis.
- This data is critical for understanding the volume of distribution and the fraction of free, pharmacologically active drug.
- Data Integration and STAR Classification:
- Integrate the data on permeability, metabolic stability, and tissue binding with potency (IC₅₀, Ki) data.
- Classify the lead series according to the STAR framework to select the best candidates for in vivo studies [7].
Diagram: Drug Development Pipeline with Kinetic Barrier Checkpoints
Quantitative Data on Clinical Attrition
The high cost of drug development is driven predominantly by failure in clinical stages. The table below summarizes the primary reasons for clinical failure of drug candidates, based on an analysis of data from 2010–2017 [7].
| Reason for Clinical Failure | Attribution Rate |
|---|---|
| Lack of Clinical Efficacy | 40% - 50% [7] |
| Unmanageable Toxicity | ~30% [7] |
| Poor Drug-Like Properties (PK, Bioavailability) | 10% - 15% [7] |
| Lack of Commercial Needs / Poor Strategic Planning | ~10% [7] |
Fundamental Concepts FAQ
What are thermodynamic and kinetic control? In chemical synthesis, thermodynamic control and kinetic control describe which reaction pathway is favored under given conditions, determining the final product mixture when competing pathways lead to different products [12].
- Kinetic Product: Forms faster due to a lower activation energy barrier. It is favored under kinetic control at lower temperatures and shorter reaction times.
- Thermodynamic Product: Is more stable and has a lower overall free energy. It is favored under thermodynamic control when the reaction is allowed to reach equilibrium, typically at higher temperatures and with longer reaction times [12] [13].
Why is the distinction important for autonomous synthesis? Autonomous laboratories, like the A-Lab, use computation and active learning to plan and execute experiments. Understanding whether a reaction is under kinetic or thermodynamic control is crucial for the AI to:
- Propose effective synthesis recipes by correctly prioritizing precursor sets and reaction conditions.
- Diagnose and overcome failures, such as sluggish reaction kinetics, which are a major cause of unsuccessful synthesis attempts [1].
- Optimize pathways by leveraging knowledge of observed reaction intermediates and their driving forces to avoid low-yield traps [1].
How can I visually distinguish between the two? The following energy profile diagram illustrates the key differences. The kinetic product forms via a pathway with a lower activation energy (Ea), while the thermodynamic product is more stable (lower ΔG).
How do temperature and time influence the product? The table below summarizes how reaction conditions determine the dominant product [12] [13].
| Condition | Favored Control Type | Favored Product | Rationale |
|---|---|---|---|
| Low TemperatureShort Time | Kinetic Control | Kinetic Product | Insufficient thermal energy to overcome the higher barrier to the thermodynamic product; system is trapped by reaction speed. |
| High TemperatureLong Time | Thermodynamic Control | Thermodynamic Product | Sufficient thermal energy and time for reaction reversal and equilibration; system reaches the most stable state. |
A classic example is the electrophilic addition to 1,3-butadiene. At low temperatures, the kinetic 1,2-adduct dominates. At high temperatures, the thermodynamic 1,4-adduct prevails [12] [13].
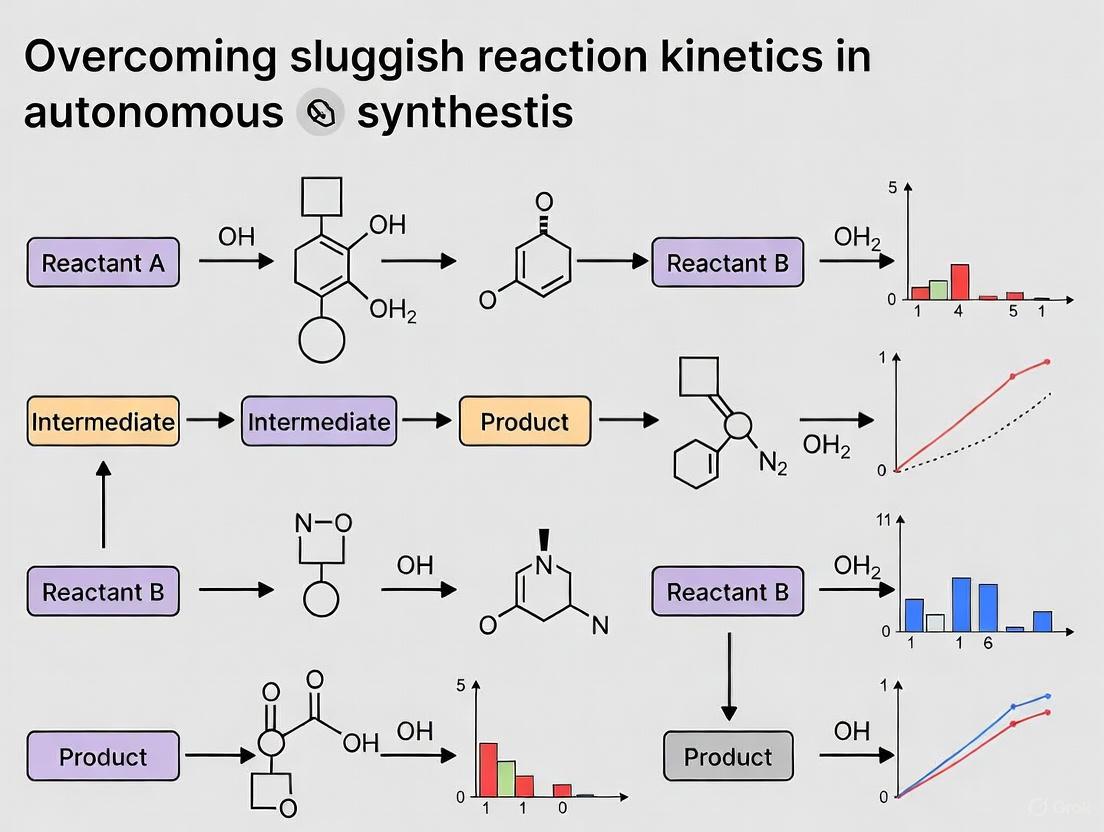
Troubleshooting Guide: Overcoming Sluggish Kinetics
Sluggish reaction kinetics was identified as the primary failure mode for 11 out of 17 unobtained targets in a recent large-scale autonomous synthesis campaign [1]. This section provides a diagnostic workflow.
Diagnostic Workflow for Kinetic Failures The following flowchart outlines a step-by-step troubleshooting process for an autonomous system that fails to synthesize a target material.
Common Failure Modes in Autonomous Synthesis Analysis from the A-Lab operation categorized reasons for synthesis failures, providing actionable diagnostics [1].
| Failure Mode | Description | Evidence | Potential Solution |
|---|---|---|---|
| Sluggish Kinetics | Reaction steps have low driving force (<50 meV/atom). | Target absent; reaction intermediates persist even at high temperature. | Use active learning to find alternative precursor sets that form intermediates with a larger driving force to the target [1]. |
| Precursor Volatility | Key precursor is lost during heating before it can react. | Non-stoichiometric product mixture; deficiency of a specific element. | Use sealed ampoules or alternative precursor salts with lower volatility. |
| Amorphization | Product or key intermediate does not crystallize. | Broad, featureless XRD pattern despite reaction signatures. | Anneal at different cooling rates; use alternative grinding protocols. |
| Computational Inaccuracy | Target material is not actually thermodynamically stable. | No known synthesis route succeeds; contradictory computational data. | Re-evaluate computational predictions of phase stability. |
Protocol: Active Learning for Route Optimization (ARROWS3) When initial recipes fail, the A-Lab uses an active learning cycle to overcome kinetic barriers [1].
- Input Failed Data: Feed the unsuccessful recipe and the identified intermediates into the active learning algorithm.
- Query Observed Reaction DB: Check a growing database of pairwise solid-state reactions to infer known pathways and avoid retesting.
- Compute Driving Forces: Use formation energies from ab initio databases (e.g., Materials Project) to calculate the driving force (ΔG) from observed intermediates to the target.
- Propose New Recipe: Prioritize precursor sets that avoid intermediates with a very low driving force (<50 meV/atom) to the target, as these are kinetic traps.
- Iterate: The new recipe is tested robotically, and the cycle continues until the target is obtained or all options are exhausted.
The Scientist's Toolkit
Key Research Reagents and Materials The following table lists essential components for conducting and analyzing experiments in autonomous synthesis research.
| Item | Function in Experiment |
|---|---|
| Precursor Powders | High-purity metal oxides, carbonates, phosphates, etc., that serve as reactants for solid-state synthesis of inorganic powders [1]. |
| Alumina Crucibles | Chemically inert containers that hold powder samples during high-temperature heating in box furnaces [1]. |
| X-ray Diffractometer (XRD) | The primary characterization tool used to identify crystalline phases and determine the weight fraction of the target product in the synthesis output [1]. |
| Ab Initio Database (e.g., Materials Project) | A computational database providing pre-calculated formation energies and phase stability data, which are essential for predicting stability and calculating reaction driving forces [1]. |
| Probabilistic ML Model for XRD | A machine learning model trained on experimental structures to identify phases and their weight fractions from XRD patterns, even for previously unreported compounds [1]. |
Experimental Workflow of an Autonomous Laboratory The A-Lab integrates computation, robotics, and active learning into a closed-loop workflow for materials discovery [1].
Frequently Asked Questions (FAQs)
Q1: What does "sluggish reaction kinetics" mean in the context of solid-state synthesis? Sluggish reaction kinetics refers to solid-state reactions that proceed extremely slowly, often due to low thermodynamic driving forces (typically below 50 meV per atom) or slow diffusion rates in solid materials. This prevents reactions from reaching completion within practical experimental timeframes, causing synthesis attempts to fail even for thermodynamically stable compounds [1].
Q2: Why are kinetic limitations particularly problematic for autonomous laboratories? Autonomous labs operate with predefined experimental cycles and time constraints. Reactions with slow kinetics may not produce detectable amounts of target material within these cycles, leading the system to incorrectly classify viable syntheses as failures and abandon promising reaction pathways [1] [14].
Q3: What experimental strategies can help overcome slow kinetics? Key strategies include: (1) increasing reaction temperatures to accelerate reaction rates, (2) selecting precursor combinations that avoid intermediate phases with low driving forces, (3) extending reaction times for promising pathways, and (4) using finer precursor powders to reduce diffusion path lengths [1] [14].
Q4: How can I determine if my failed synthesis is due to kinetic limitations? Monitor for these indicators: (1) target formation begins but plateaus at low yield, (2) intermediate phases persist throughout the reaction, (3) calculations show low driving forces (<50 meV/atom) for critical reaction steps, or (4) extended reaction time at higher temperature increases target yield [1].
Troubleshooting Guide: Kinetic Limitations in Solid-State Synthesis
Problem Diagnosis Table
| Observation | Possible Causes | Diagnostic Tests | Suggested Solutions |
|---|---|---|---|
| Low target yield with persistent intermediate phases | Slow solid-state diffusion; Low driving force for final reaction step | Calculate decomposition energy of intermediates; Analyze reaction pathway driving forces | Increase reaction temperature; Modify precursor selection to avoid low-driving-force intermediates |
| Partial reaction with unreacted starting materials | Slow nucleation kinetics; Insufficient reaction energy | Perform stepwise heat treatments; Test with finer precursor powders | Introduce seeding crystals; Use mechanical activation; Employ multi-stage heating profiles |
| Inconsistent results between similar precursor sets | Varying kinetic pathways with different activation energies | Compare reaction pathways for different precursors; Analyze intermediate phases | Prioritize precursor combinations with simpler reaction pathways; Use combinatorial screening |
| Variable performance across temperature ranges | Temperature-dependent kinetic barriers | Conduct temperature-gradient experiments; Determine activation energy | Optimize temperature profile; Extend reaction time at critical temperature ranges |
Quantitative Analysis of A-Lab Synthesis Failures
Table: Root Causes for 17 Failed Syntheses in A-Lab Experiments [1]
| Failure Category | Number of Targets | Percentage of Total Failures | Characteristic Kinetic Issues |
|---|---|---|---|
| Sluggish reaction kinetics | 11 | 65% | Reaction steps with driving forces <50 meV/atom |
| Precursor volatility | 3 | 18% | Loss of reactive components before reaction completion |
| Amorphization | 2 | 12% | Failure to crystallize despite reaction occurrence |
| Computational inaccuracy | 1 | 6% | Incorrect stability predictions affecting precursor selection |
Experimental Protocols for Kinetic Analysis
Protocol 1: Driving Force Calculation for Reaction Steps
Purpose: Identify kinetic bottlenecks in proposed synthesis routes by quantifying thermodynamic driving forces [1].
Materials:
- Computational access to materials database (e.g., Materials Project)
- Formation energy data for target and potential intermediate phases
- Statistical analysis software
Procedure:
- Identify all possible intermediate phases that may form between precursors
- Retrieve or calculate formation energies (ΔGf) for all relevant phases
- Compute decomposition energy for each reaction step: ΔErxn = ΣΔGf(products) - ΣΔGf(reactants)
- Flag any reaction steps with driving forces <50 meV/atom as potential kinetic bottlenecks
- Prioritize synthesis routes that avoid low-driving-force steps
Expected Output: Quantitative assessment of reaction pathway viability with identification of specific kinetic barriers.
Protocol 2: Precursor Selection Optimization
Purpose: Select precursor combinations that maximize driving forces and minimize kinetic barriers [1].
Materials:
- Multiple precursor options for target composition
- Historical reaction database
- Pairwise reaction data
Procedure:
- Generate all chemically plausible precursor combinations for target material
- Consult historical data on similar systems to identify successful precursor patterns
- Evaluate predicted reaction pathways for each precursor set
- Calculate pairwise reaction energies between potential intermediates
- Select precursors that generate high-driving-force intermediates (>75 meV/atom)
- Validate selection with small-scale test reactions before full synthesis
Expected Output: Optimized precursor set with minimized kinetic barriers to target formation.
Research Reagent Solutions
Table: Essential Materials for Kinetic Studies in Solid-State Synthesis
| Reagent Category | Specific Examples | Function in Kinetic Analysis | Application Notes |
|---|---|---|---|
| Computational Databases | Materials Project, Google DeepMind | Provide formation energies for driving force calculations | Essential for predicting reaction pathways before experimentation |
| Precursor Libraries | Metal oxides, phosphates, carbonates | Enable screening of multiple reaction pathways | Maintain diverse selection to maximize finding kinetically favorable routes |
| Historical Reaction Databases | ICSD, literature mining datasets | Identify successful precursor patterns for analogous materials | Train ML models for improved precursor selection |
| In Situ Characterization | High-temperature XRD, Raman spectroscopy | Monitor phase evolution in real time | Critical for identifying rate-limiting steps in reaction pathways |
Workflow Diagrams
Diagram 1: Kinetic Failure Analysis Pathway
Diagram 2: Kinetic Optimization Workflow
The Role of Driving Force Calculations in Predicting Kinetic Traps
Frequently Asked Questions (FAQs)
1. What is a kinetic trap in self-assembly or synthesis reactions? A kinetic trap is a metastable state that hinders the formation of the thermodynamically stable, ordered product. Even when the final ordered state is energetically favorable, the system becomes trapped in a disordered structure due to dynamics that prevent the components from rearranging into the correct configuration [15].
2. How do driving force calculations help predict kinetic traps? Driving force calculations, rooted in thermodynamic free energy landscapes, help identify the energetic favorability of the desired product versus off-pathway intermediates. By quantifying this, researchers can predict if proposed reaction conditions provide sufficient thermodynamic driving force to overcome activation barriers or if they risk populating stable, but undesired, trapped states [15].
3. What are the common experimental signatures of a kinetic trap? Common signs include:
- The reaction stalls at a high yield of incomplete or disordered clusters instead of forming the target structure [15].
- The final yield of the desired product is highly dependent on the initial conditions, such as concentration or temperature, rather than converging to a thermodynamically predicted value.
- Experiments show the formation of amorphous aggregates or gels instead of crystalline or other ordered phases [15].
4. My autonomous synthesis platform is producing inconsistent yields. Could kinetic trapping be the cause? Yes. In autonomous synthesis, if the AI proposes reaction conditions with overly strong interparticle bonds or excessively high concentrations to maximize yield, it can inadvertently push the system into a kinetically trapped regime. This results in high yield in some experiments but low yield in others due to the formation of off-pathway aggregates. Implementing driving force estimates as a constraint in the AI's decision-making process can help avoid these regions of parameter space [15].
5. What is the relationship between bond strength and kinetic trapping? Strong interparticle bonds are a primary cause of kinetic trapping. While strong bonds stabilize the final ordered state, they also make it difficult for incorrectly bonded subunits to break apart and re-arrange properly. Effective self-assembly often relies on a balance of many relatively weak, transient interactions, which allow for error correction through frequent bond-breaking and re-formation [15].
Troubleshooting Guides
Problem: Low Yield of Desired Ordered Product in Self-Assembly
Description: The reaction predominantly forms disordered, polydisperse clusters or aggregates instead of the target monodisperse structure (e.g., a viral capsid or a specific metal-organic framework).
Diagnosis: This is a classic symptom of kinetic trapping, often caused by an interaction energy that is too strong, preventing molecular reorganization [15].
Solution: Weaken the effective interparticle interactions to allow for error correction.
Step-by-Step Protocol:
- Monitor Reaction Progress: Use an in-situ analytical technique (e.g., NMR, DLS, or UV-Vis) to track the formation of the target product versus aggregates over time [16].
- Modify Interaction Strength:
- For molecular systems, adjust the solvent composition to reduce binding affinity (e.g., increase polarity).
- For colloidal systems, modify the surface chemistry or electrolyte concentration.
- Consider using a protecting group or a reversibly binding ligand to temporarily moderate interaction strength.
- Optimize Thermodynamic Driving Force: Systematically vary the concentration and temperature. The optimal yield often occurs at an intermediate concentration and a specific temperature range that provides sufficient driving force without inducing trapping [15].
- Implement a Ramp-and-Hold Protocol: Start the reaction at a elevated temperature where bonds are weak and rearrange easily, then slowly cool (ramp) to the final temperature to anneal the correct structure.
Problem: Slow or Incomplete Phase Transformation in Solid-State Synthesis
Description: The synthesis fails to convert a starting material into a desired metastable phase, or the transformation is impractically slow.
Diagnosis: The kinetic pathway to the metastable phase is hindered by a large energy barrier or competition with the formation of the stable phase.
Solution: Use an autonomous experimentation platform to rapidly explore ultrafast annealing conditions that can kinetically trap the metastable phase [17].
Step-by-Step Protocol:
- Sample Preparation: Deposit an amorphous thin-film library of the target material on a substrate via reactive sputtering [17].
- Autonomous Exploration with lg-LSA: Employ a system like the Scientific Autonomous Reasoning Agent (SARA) integrated with lateral gradient laser spike annealing (lg-LSA). This setup creates a spatial gradient of temperature and dwell time across the sample [17].
- Hierarchical Active Learning:
- The AI agent proposes the next set of lg-LSA synthesis parameters (e.g., laser power, scan speed).
- An inner autonomous loop performs rapid optical characterization on the processed stripe.
- The AI uses the data to update its model of the synthesis phase diagram and proposes the next most informative experiment [17].
- Identify Conditions: The autonomous loop will efficiently map the synthesis phase boundaries, identifying the specific time-temperature conditions (e.g., high quench rates of 10⁴ to 10⁷ K/s) required to stabilize the metastable phase, such as δ-Bi₂O₃, at room temperature [17].
Problem: Autonomous Optimization Algorithm Suggests Impractical Conditions
Description: The AI guiding your self-driving lab consistently suggests reaction parameters that lead to gelling, precipitation, or inconsistent results.
Diagnosis: The AI's objective function is likely focused only on maximizing the yield of the final product, ignoring the stability of intermediate states.
Solution: Reformulate the AI's optimization problem to incorporate constraints based on driving force calculations and real-time diagnostics.
Step-by-Step Protocol:
- Define a Multi-Objective Reward Function: Instead of rewarding only high final yield, also penalize the formation of aggregates. This can be done by incorporating in-situ light scattering data or viscosity measurements as negative terms in the reward function [16].
- Incorporate Physical Models: Integrate coarse-grained physical models that estimate the driving force for aggregation into the AI's decision-making process. The AI should be designed to avoid regions of parameter space predicted to have an excessively high driving force for disordered aggregation [15].
- Implement Bayesian Optimization with Constraints: Use advanced optimization algorithms that can handle "no-go" constraints. Define a constraint based on a real-time diagnostic signal (e.g., turbidity) and instruct the AI to avoid conditions that trigger it [18].
- Validate with Orthogonal Analytics: After the AI identifies an optimal condition, run a final validation experiment using a high-information technique like NMR or LC-MS to confirm the identity and purity of the product [16].
Quantitative Data and Experimental Parameters
The following table summarizes key parameters from documented studies on kinetic trapping and autonomous synthesis, providing a reference for your experimental design.
Table 1: Experimental Parameters in Kinetic Trap and Autonomous Synthesis Studies
| System / Platform | Key Parameter | Value / Range | Role in Kinetic Trapping & Synthesis |
|---|---|---|---|
| Viral Capsid Model [15] | Bond Strength (εb/T) | ~4.5 (Optimal) | Intermediate strength maximizes yield; stronger bonds (>5) cause trapping via disordered clusters. |
| Bond Strength (εb/T) | >5 (Trapping) | ||
| Lattice Gas Model [15] | Bond Energy (εb) | Variable | Strong bonds frustrate phase separation dynamics, leading to gelation and trapping. |
| SARA (Bi₂O₃ System) [17] | Quench Rate | 10⁴ - 10⁷ K/s | High quench rates enable kinetic trapping of metastable phases (e.g., δ-Bi₂O₃) at room temperature. |
| Peak Temperature (Tp) | Up to 1400°C | Explored to find non-equilibrium conditions for metastable phase formation. | |
| Autonomous NMR Platform [16] | Analysis Cycle | Continuous / On-the-fly | Provides real-time feedback on reaction composition, allowing the AI to adjust parameters before traps dominate. |
Table 2: The Scientist's Toolkit: Key Research Reagent Solutions
| Item | Function in Experiment |
|---|---|
| Lateral Gradient Laser Spike Annealing (lg-LSA) [17] | Enables ultra-fast thermal processing with spatial gradients, allowing high-throughput mapping of time-temperature transformation diagrams for metastable materials. |
| Ising Lattice Gas Model [15] | A computational model used to study generic mechanisms of kinetic trapping during phase separation, providing insights into how strong bonds frustrate ordering. |
| Advanced Chemical Profiling (ACP) Software [16] | Automates the analysis and quantification of NMR data, providing machine-readable output for real-time feedback and control in autonomous workflows. |
| Bayesian Optimization [18] | An AI-driven approach used to guide experiments, efficiently navigating complex parameter spaces to find optimal conditions while potentially avoiding kinetic traps. |
| Thiosulfate Ion & Starch Indicator [19] | A classic chemical clock reaction system used to indirectly measure the initial rate of slow redox reactions by monitoring the time until a color change occurs. |
Workflow and Relationship Diagrams
Autonomous Synthesis Workflow
Kinetic Trap Relationship
AI-Powered Methodologies to Accelerate Reaction Kinetics
Frequently Asked Questions (FAQs)
Q1: What makes Bayesian Optimization (BO) particularly suitable for optimizing composition-spread films?
BO is ideal for this application because it is designed to optimize black-box functions that are expensive to evaluate, which perfectly describes the time-consuming and resource-intensive nature of fabricating and testing composition-spread films [20] [21] [22]. Its ability to balance exploration (testing uncertain regions of the composition space) and exploitation (refining areas known to yield good results) allows it to find optimal material compositions with a minimal number of experimental cycles [23] [24]. Furthermore, specialized BO methods have been developed specifically to select which elements should be compositionally graded in a spread film, a capability not offered by conventional optimization packages [20].
Q2: My autonomous loop is taking too long per cycle. Where are the common bottlenecks in a high-throughput workflow for Hall effect materials?
The primary bottlenecks in conventional workflows are often device fabrication (using multi-step lithography requiring photoresists, taking ~5.5 hours) and measurement setup (wire-bonding for individual devices, taking ~0.5 hours) [25]. A modern high-throughput system overcomes this by implementing:
- Photoresist-free laser patterning for device fabrication (~1.5 hours for 13 devices) [20] [25].
- Custom multichannel probes with pogo-pins for simultaneous measurement of multiple devices, eliminating wire-bonding (~0.2 hours for 13 devices) [20] [25].
- Combinatorial sputtering for depositing composition-spread films (~1-2 hours) [20].
Q3: How do I handle noisy measurements of anomalous Hall resistivity (e.g., due to film inhomogeneity) in my Bayesian Optimization model?
Gaussian Processes (GPs), the common surrogate model in BO, can directly incorporate measurement noise [21] [26]. When configuring your GP model, you can set a noise variance parameter (often called alpha or noise). This informs the model to treat deviations in the data below a certain threshold as noise, preventing it from overfitting to spurious measurements and leading to more robust optimization [21].
Q4: Our experimental results are not matching the model's predictions. How can we improve the performance of the Bayesian Optimization process?
Performance issues can often be traced to the initial samples or the acquisition function.
- Initialization: The BO process is sensitive to the initial set of random samples. Ensure you run an adequate number of random trials (e.g., 5-10) before the optimization begins to build a reasonable initial surrogate model [22].
- Acquisition Function Tuning: The parameter
xiin the Expected Improvement (EI) function controls the balance between exploration and exploitation. A value that is too high leads to excessive exploration, while a value too low causes the algorithm to get stuck in local optima. Experiment with different values ofxi(a common default is 0.01) to improve convergence [21] [22].
Troubleshooting Guides
Issue: Poor Convergence or Suboptimal Material Proposal
This occurs when the BO algorithm fails to find a composition that significantly improves the target property (e.g., anomalous Hall resistivity) within a reasonable number of cycles.
| Potential Cause | Diagnostic Steps | Resolution |
|---|---|---|
| Inadequate initial sampling | Check if the initial random samples cover the entire composition space evenly. A clustered initial dataset limits the model's global understanding. | Increase the number of random initial trials. Use space-filling designs like Latin Hypercube Sampling for initial data collection if possible. |
| Misconfigured acquisition function | Plot the acquisition function over the composition space. It may show a flat profile or maxima only in known regions. | Adjust the xi parameter in the Expected Improvement function. Increase xi to encourage more exploration of unknown compositions [23] [21]. |
| Inappropriate kernel for the Gaussian Process | Review the model's predictions; they may be overly smooth or too "wiggly," failing to capture the true landscape. | Change the GP kernel. The Matérn kernel is a good default for modeling physical properties. Experiment with different kernel lengthsales [21]. |
Issue: Integration Failure Between BO and Automated Hardware
The software fails to control the combinatorial sputtering system or parse data from the multichannel Hall probe.
| Potential Cause | Diagnostic Steps | Resolution |
|---|---|---|
| Incorrect input file format for deposition system | Manually check the generated recipe file against the system's required format. | Develop or use a dedicated Python program (e.g., nimo.preparation_input function) that automatically generates a correctly formatted input file from the BO proposal [20]. |
| Data structure mismatch after combinatorial experiment | Confirm that the analyzed experimental data is correctly mapped back to the candidate compositions in the database (candidates.csv). |
Implement an automated analysis function (e.g., nimo.analysis_output in "COMBAT" mode) that removes tested composition ranges from the candidate list and adds the new results with the correct composition labels [20]. |
Experimental Protocols
High-Throughput Anomalous Hall Effect (AHE) Workflow
The following protocol describes the integrated, high-throughput method for discovering materials with a large Anomalous Hall Effect [20] [25].
Title: Autonomous Closed-Loop AHE Experiment
Procedure:
- Composition-Spread Film Deposition:
- Use a combinatorial sputtering system equipped with a linear moving mask and substrate rotation.
- Co-sputter from multiple targets to create a thin film with a continuous composition gradient in one direction on a substrate (e.g., SiO₂/Si).
- Duration: ~1.3 - 2 hours [20] [25].
- Key Parameters: The BO algorithm selects which two elements (e.g., two 3d-3d or 5d-5d pairs) to grade compositionally.
Photoresist-Free Device Fabrication:
Simultaneous AHE Measurement:
- Use a custom multichannel probe with spring-loaded pogo-pins that contact all device terminals simultaneously.
- Install the probe in a Physical Property Measurement System (PPMS) with a superconducting magnet.
- Measure the Hall voltage of all devices while sweeping a perpendicular magnetic field to saturation.
- Duration: ~0.2 hours for 13 devices [20] [25].
Automatic Data Analysis and Bayesian Optimization:
- A Python program automatically analyzes the raw voltage data to calculate the anomalous Hall resistivity (({\rho }_{{yx}}^{A})) for each composition.
- The results are fed into the specialized BO algorithm (e.g., via the NIMO orchestration system).
- The algorithm updates its surrogate model and uses the acquisition function to propose the next composition-spread film to fabricate, specifying the elements to grade.
- The loop returns to Step 1.
Bayesian Optimization Algorithm for Composition-Spread Films
This protocol details the specific BO method used for composition-spread films, which extends standard BO to select which elements to grade [20].
Input: Initial candidate composition list (candidates.csv), prior Gaussian Process model.
Output: Proposal for the next composition-spread film (proposals.csv).
Procedure:
- Select a Promising Base Composition:
- Find the composition with the highest value from the acquisition function (e.g., Expected Improvement) using the current GP model. This is the same as conventional BO [20].
Score All Possible Element Pairs for Grading:
- For each possible pair of elements (e.g., Ni/Co, Ta/Ir):
- Generate
Lcompositions by creating a linear gradient between the two elements, while keeping the other elements fixed at the values from Step 1. - Evaluate the acquisition function for each of these
Lcompositions. - Calculate the score for this element pair by averaging the acquisition function values across the
Lcompositions [20].
- Generate
- For each possible pair of elements (e.g., Ni/Co, Ta/Ir):
Propose the Next Experiment:
- Select the element pair with the highest score to be compositionally graded in the next film.
- The proposal (
proposals.csv) will include theLspecific compositions for this gradient [20].
The Scientist's Toolkit: Research Reagent Solutions
Table 1: Essential materials and software for autonomous AHE materials discovery.
| Item | Function/Description | Example/Reference |
|---|---|---|
| Combinatorial Sputtering System | Deposits thin films with a continuous composition gradient on a single substrate by co-sputtering from multiple targets. | Systems with linear moving masks and substrate rotation [20] [25]. |
| Laser Patterning System | Enables photoresist-free fabrication of multiple Hall bar devices by ablating the film, drastically increasing throughput. | Direct-write laser systems [20] [25]. |
| Custom Multichannel Probe | Allows simultaneous measurement of Hall voltage from multiple devices using pogo-pins, eliminating slow wire-bonding. | Probes with 28+ pogo-pins designed for PPMS [20] [25]. |
| Bayesian Optimization Software | Orchestrates the closed-loop experiment. Selects next compositions to test by modeling the composition-property landscape. | NIMO, PHYSBO, GPyOpt [20]. |
| Ferromagnetic 3d Elements | Base elements providing ferromagnetism, essential for the Anomalous Hall Effect. | Fe, Co, Ni [20] [25]. |
| 5d Heavy Metals | Dopant elements with strong spin-orbit coupling, used to enhance the Anomalous Hall Effect. | Ta, W, Ir, Pt [20] [25]. |
| SiO₂/Si Substrate | Common, thermally oxidized silicon substrate for depositing amorphous magnetic thin films at room temperature. | Readily available and suitable for device integration [20]. |
Troubleshooting Guides
Q: The autonomous vessel becomes unstable and oscillates violently when trying to hold position (loiter) at a waypoint. How can this be resolved?
A: This is a known issue related to autopilot gain settings. The solution involves adjusting the specific parameter that controls the angular velocity gain for steering.
- Investigation Steps:
- Confirm the issue occurs specifically in
LOITERmode, even if waypoint navigation is stable. - Check the autopilot's tuning parameters for steering gains.
- Confirm the issue occurs specifically in
- Solution:
- Locate the parameter
ATC_STR_ANG_P(or its equivalent in your autopilot system). - Reduce the value of this gain. For example, if the default value is 5, try reducing it to 1 to dampen the aggressive steering response.
- Test the new parameter in a safe environment. The vessel should be stable in loiter mode, though it may still spin rapidly to acquire its heading [27].
- Locate the parameter
Q: The system fails to accurately measure drift velocity, which is critical for the ARROWS3 algorithm's route optimization. What should I check?
A: Drift measurement relies on precise GPS data and correct script execution.
- Investigation Steps:
- Verify the Lua script is actively running on the autopilot and that the correct command ID (e.g.,
86) is triggered by your mission waypoints [27]. - Check the data logging functionality. Ensure the autopilot's SD card has space and that the script correctly writes the drift data (starting latitude, longitude, timestamp, drift speed, and direction) to a CSV file [27].
- Monitor the telemetry link in real-time to see if drift data is being transmitted. A value of
-1typically indicates the system is not in drift mode, while a positive number shows the live drift distance [27].
- Verify the Lua script is actively running on the autopilot and that the correct command ID (e.g.,
- Solution:
- Review and validate the mission plan. Ensure waypoints are set to
loiter_timeto stabilize the vessel before drift, and are followed by aSCRIPT_TIMEcommand to activate the drift script [27]. - If wind is a significant source of error, consider using a vessel with a minimal above-waterline profile or implementing a drogue system to better couple the vessel with water currents [27].
- Review and validate the mission plan. Ensure waypoints are set to
Q: The calculated optimal route does not yield the expected improvement in travel time or efficiency. What could be the cause?
A: This can stem from issues with the input data or the optimization constraints.
- Investigation Steps:
- Review Data Currency: The ARROWS3 algorithm uses a measured velocity field. If there is a significant time delay between measuring the currents and the vessel traversing the route, the flow conditions may have changed, making the data obsolete [27].
- Check Mission Definition: Verify that the mission's goals and constraints (e.g., patrol zone boundaries, no-go areas) are correctly programmed into the algorithm. An "optimal" route is only optimal for the defined mission [27].
- Validate the Velocity Field: Examine the raw drift measurements and the subsequent spatial interpolation. Ensure the survey points form a sensible grid (like a rectangle) to maximize the area where the algorithm performs reliable interpolation instead of less accurate extrapolation [27].
- Solution:
- Use a faster survey vessel to minimize the time between measurement and route execution.
- Re-run the current measurement survey immediately before the optimized mission.
- Visually inspect the interpolated velocity field for anomalies or inconsistencies with observed conditions [27].
Frequently Asked Questions (FAQs)
Q: What is the core principle behind the ARROWS3 algorithm for route optimization?
A: The ARROWS3 algorithm uses real-time, on-site measurements of surface currents (and other drift forces) to build a velocity field map. It then calculates a vessel's path through this dynamic field to minimize travel time or energy consumption by leveraging favorable currents and avoiding adverse ones [27].
Q: Why is a Lua script used in the data collection phase?
A: A Lua script is integrated into the autopilot to create a custom "drift mode" that is not a standard function. This script automates the process of stopping the propulsion, logging high-frequency GPS data to calculate drift velocity and direction, and resuming the mission—all essential for gathering the data the ARROWS3 algorithm needs to function [27].
Q: For scientific current measurement, what is a limitation of using a standard autonomous surface vessel (ASV)?
A: A standard ASV's drift is influenced by wind and waves in addition to current. For pure oceanographic data, this adds noise. Scientific drift buoys use a drogue (sea anchor) to minimize wind drift and better measure water movement. An ASV like n3m02 was observed to be noticeably susceptible to drifting with the wind [27].
Q: How does the algorithm handle the inherent delay between measuring currents and executing an optimized route?
A: This is a recognized source of uncertainty. The algorithm itself cannot compensate for changing conditions between the survey and the mission. The primary strategy is to minimize this delay by using a fast survey vessel and conducting measurements as close in time to the main mission as possible [27].
The Scientist's Toolkit: Research Reagent Solutions
The following materials are essential for implementing the ARROWS3-based autonomous measurement and optimization system.
| Item Name | Function |
|---|---|
| Autonomous Vessel Platform | A reliable, robotic boat that serves as the physical platform for transporting sensors, an autopilot, and a propulsion system. |
| GPS Receiver | Provides high-precision, real-time positional data essential for calculating speed, direction, and drift velocity [27]. |
| Programmable Autopilot | The central control unit (e.g., Matek F765-WING) that executes navigation commands, runs custom scripts, and manages sensor data [27]. |
| Lua Scripting Environment | Allows for the creation and execution of custom automation scripts on the autopilot, such as the one used to initiate and log drift measurements [27]. |
| Telemetry System | Enables real-time, wireless communication between the autonomous vessel and a ground control station for monitoring and intervention [27]. |
Experimental Protocol: Drift Measurement for Velocity Field Mapping
Objective: To autonomously collect surface drift data at predefined points within a survey area to construct a velocity field for the ARROWS3 route optimization algorithm.
Methodology:
- Mission Planning:
- Define a rectangular grid of waypoints within the target survey area to maximize the zone for reliable spatial interpolation [27].
- Program each waypoint in the autopilot mission as a
loiter_timepoint with a short hold time (e.g., 10 seconds) to allow the vessel to stabilize [27]. - Immediately after each
loiter_timewaypoint, program aSCRIPT_TIMEcommand (e.g., ID 86) with arguments to initiate drifting for a set duration (e.g., 50 seconds) and a safety radius (e.g., 10 meters) [27].
- Autonomous Execution:
- Deploy the vessel to execute the mission.
- The vessel will navigate to each waypoint, loiter, and then the Lua script will disable the motors and begin logging GPS data to calculate drift [27].
- Data Collection:
- Data is recorded in real-time via telemetry and stored in a CSV file on the autopilot's SD card. Key data points include [27]:
- Start Latitude and Longitude
- Timestamp
- Drift Speed
- Drift Direction
- Data is recorded in real-time via telemetry and stored in a CSV file on the autopilot's SD card. Key data points include [27]:
ARROWS3 System Workflow
The following diagram illustrates the core operational workflow of the ARROWS3 autonomous measurement and optimization system.
Data Flow for Route Optimization
This diagram details the data processing pipeline, from raw measurement to optimized route command.
Troubleshooting Guides and FAQs
Frequently Asked Questions
Q1: Why is my multimodal model failing to outperform my best unimodal model? This common issue often stems from inadequate fusion techniques or poor modality alignment. The heterogeneity of data sources (e.g., spectral, imaging) means they may contain complementary but differently structured information. Evaluate different fusion strategies: late fusion (combining model decisions), early fusion (combining raw features), or advanced methods like MultConcat multimodal fusion, which achieved 89.3% accuracy in recognizing dangerous actions by effectively capturing cross-modal interactions [28] [29]. Ensure your modality encoders are robust enough to extract useful features before fusion.
Q2: How can I handle missing spectroscopic data in my kinetic analysis? Implement fusion techniques robust to missing modalities. Some advanced algorithms can compensate for information loss by using available modalities to infer missing data, which is particularly valuable in experimental settings where certain measurements might fail [29]. Consider coordinated representations that maintain relationships between modalities even when some are absent [28].
Q3: What's the optimal approach for fusing time-resolved spectroscopic and imaging data for kinetic modeling? For temporal data, consider techniques that preserve timing relationships across modalities. Alignment becomes crucial—explicit alignment for directly corresponding sub-components or implicit alignment using latent representations for loosely connected temporal sequences [28]. Ensure sufficient temporal resolution in your fastest modality to capture critical kinetic events.
Q4: How can I validate that my fused model truly leverages complementary information across modalities? Ablation studies are essential. Systematically remove each modality and observe performance degradation. Additionally, analyze whether the model captures expected complementary relationships; for instance, in spectroscopic data fusion, ensure the model leverages both MIR and Raman complementarities rather than relying predominantly on one modality [30].
Q5: What computational resources are typically required for complex multimodal fusion? Memory requirements vary significantly by fusion technique. Late fusion typically uses more memory during prediction as it maintains multiple models, while early fusion consumes more memory during training due to concatenated high-dimensional features [29]. For spectroscopic data, Complex-level Ensemble Fusion (CLF) adds computational overhead but provides superior predictive accuracy for complex regression tasks [30].
Troubleshooting Common Experimental Issues
Problem: Sluggish reaction kinetics hindering material synthesis Background: This parallels issues encountered in autonomous materials synthesis, where 19% of failed targets faced kinetic hurdles, particularly reactions with low driving forces (<50 meV per atom) [1]. Solution: Implement active learning cycles that identify and avoid kinetic traps. The A-Lab system successfully optimized synthesis routes by prioritizing intermediates with larger driving forces (e.g., increasing from 8 meV to 77 meV per atom) to overcome sluggish kinetics [1]. Consider designing alternative reaction pathways that bypass slow-reacting intermediates.
Problem: Discrepancies between different spectroscopic techniques during kinetic measurements Background: Each spectroscopic method (UV-visible, IR, fluorescence, Raman) has unique advantages and limitations for kinetic studies [31]. Solution: Systematically compare kinetic parameters from multiple techniques to validate results and gain comprehensive mechanistic understanding. For example, UV-visible and fluorescence excel at monitoring electronic transitions, while IR and Raman are better for vibrational transitions [31]. Use discrepancies to identify complex reaction mechanisms rather than treating them as experimental error.
Problem: Ineffective fusion of complementary spectroscopic data Background: Traditional data fusion methods often fall short with disparate spectroscopic data, limiting predictive performance [30]. Solution: Implement Complex-level Ensemble Fusion (CLF), which jointly selects variables from concatenated spectra (e.g., MIR and Raman), projects them with partial least squares, and stacks latent variables into a boosted regressor. This approach has demonstrated significantly improved predictive accuracy by capturing feature- and model-level complementarities in a single workflow [30].
Problem: Insufficient data for training robust multimodal kinetics models Background: Many real-world applications have limited samples (e.g., fewer than one hundred), making conventional ML approaches challenging [30]. Solution: Leverage co-learning techniques that transfer knowledge from data-rich modalities to data-poor ones [28]. Additionally, employ data augmentation specific to each modality and consider coordinated representation learning that creates a shared space across modalities even with limited data.
Comparison of Multimodal Fusion Techniques
Table 1: Performance comparison of fusion techniques across different applications
| Fusion Technique | Application Domain | Key Performance Metric | Result | Reference |
|---|---|---|---|---|
| MultConcat Fusion | Dangerous action recognition | Accuracy | 89.3% | [28] |
| Complex-level Ensemble Fusion (CLF) | Spectroscopic data (MIR+Raman) | Predictive accuracy | Significantly improved vs. established methods | [30] |
| Late Fusion | General classification | Model performance | Varies by modality impact | [29] |
| Early Fusion | General classification | Model performance | Effective for interconnected modalities | [29] |
| Sketch | General classification | Model performance | Creates common representation space | [29] |
Spectroscopic Methods for Kinetic Measurements
Table 2: Characteristics of spectroscopic methods for kinetic analysis
| Method | Timescale | Key Applications | Advantages | Limitations |
|---|---|---|---|---|
| UV-visible spectroscopy | Seconds to minutes | Concentration changes, electronic transitions | Broad applicability, follows Beer-Lambert law | Requires chromophore |
| Infrared spectroscopy | Seconds to minutes | Vibrational transitions, functional groups | Specific molecular information | Affected by solvent absorption |
| Fluorescence spectroscopy | Nanoseconds to microseconds | Fast reactions, aromatic compounds | High sensitivity, fast temporal resolution | Requires fluorescent species |
| Raman spectroscopy | Seconds to minutes | Aqueous solutions, inorganic compounds | Minimal water interference | Weak signals, specialized equipment needed |
Experimental Protocols
Protocol 1: Complex-level Ensemble Fusion for Spectroscopic Data
This protocol outlines the CLF method for fusing mid-infrared (MIR) and Raman spectroscopic data to enhance kinetic modeling [30].
Materials Required:
- Paired MIR and Raman spectra datasets
- Computational environment for machine learning
- Genetic algorithm implementation
- Partial Least Squares (PLS) regression capability
- XGBoost regressor
Procedure:
- Data Preprocessing: Normalize both MIR and Raman spectra to account for instrumental variations.
- Variable Selection: Jointly select informative variables from concatenated MIR and Raman spectra using a genetic algorithm.
- Projection: Project the selected variables using Partial Least Squares to create latent variables that capture covariance between spectroscopic features and target kinetic parameters.
- Ensemble Stacking: Stack the latent variables from both modalities into an XGBoost regressor.
- Model Validation: Validate using cross-validation against single-modality models and traditional fusion approaches.
Expected Outcomes: CLF consistently demonstrates significantly improved predictive accuracy compared to single-source models and classical fusion schemes by effectively leveraging complementary spectral information [30].
Protocol 2: Active Learning for Overcoming Sluggish Kinetics
Adapted from autonomous materials synthesis research, this protocol addresses kinetic barriers in reactions [1].
Materials Required:
- Robotic synthesis platform (optional but beneficial)
- In-situ characterization (e.g., XRD for materials, spectroscopy for molecular systems)
- Computational thermodynamics database
- Active learning implementation
Procedure:
- Initial Synthesis Proposal: Generate initial conditions using literature-inspired models or analogy to known systems.
- Reaction Execution: Perform synthesis under proposed conditions.
- Product Characterization: Quantify target yield using appropriate analytical techniques.
- Pathway Analysis: Identify intermediate phases or species and compute driving forces to final product using thermodynamic data.
- Recipe Optimization: Prioritize pathways with larger driving forces (>50 meV per atom) and avoid intermediates with small driving forces.
- Iterative Refinement: Continue active learning cycle until target is obtained or all possibilities exhausted.
Expected Outcomes: This approach successfully identified synthesis routes with improved yield for multiple targets, including a ~70% yield increase for CaFe₂P₂O₉ by avoiding low-driving-force intermediates [1].
Workflow Visualization
Multimodal Kinetics Analysis Workflow
Active Learning for Kinetics Optimization
Research Reagent Solutions
Table 3: Essential materials and computational tools for multimodal kinetics research
| Item | Function | Application Context |
|---|---|---|
| MIR and Raman spectrometers | Complementary vibrational spectroscopy | Capturing different aspects of molecular structure and changes [30] |
| Time-resolved transient absorption spectrometer | Studying fast reaction kinetics (subpicosecond) | Monitoring short-lived intermediates in photochemical reactions [32] |
| Fluorescence lifetime spectrometer | Tracking emission decay kinetics | Studying energy transfer processes and molecular interactions [32] |
| Genetic algorithm optimization | Variable selection from multimodal data | Identifying most informative features across spectroscopic modalities [30] |
| XGBoost regressor | Ensemble modeling for fused data | Integrating latent variables from multiple modalities for improved prediction [30] |
| Ab initio computational databases | Thermodynamic driving force calculations | Predicting reaction pathways and identifying kinetic barriers [1] |
Large Language Models for Precursor Selection and Reaction Condition Prediction
Core Concepts and Troubleshooting
What are the primary causes of sluggish reaction kinetics, and how can LLMs help diagnose them?
Sluggish reaction kinetics, a major failure mode in autonomous synthesis, often stems from reaction steps with low driving forces (typically <50 meV per atom), which present a significant energy barrier for the reaction to proceed [1]. Other common causes include slow solid-state diffusion, precursor volatility, and unwanted amorphization of materials [1].
LLMs, particularly when operating in an "active" environment with access to computational tools, can diagnose these issues by calculating and analyzing reaction energies and identifying potential kinetic traps [33] [34]. For instance, an LLM agent can be prompted to calculate the driving force for each proposed reaction step. If the driving force is below the 50 meV/atom threshold, it can flag this step as high-risk for kinetic failure and proactively suggest an alternative pathway [1].
My LLM keeps "hallucinating" implausible precursors or reaction conditions. How can I mitigate this?
Hallucination is a critical failure mode where the LLM generates information not grounded in chemical reality, which can be dangerous in an experimental context [33] [34]. This occurs most frequently when the LLM is used in a "passive" mode, relying solely on its training data without access to external, grounding tools [33].
Mitigation Strategies:
- Integrate External Tools: Ground the LLM's responses by connecting it to external knowledge bases and software. Essential tools include:
- Employ Fine-Tuning: Fine-tune a base LLM (e.g., LLaMA, Qwen) on high-quality, domain-specific datasets such as the USPTO (containing ~50k reactions) or Reaxys (containing over 1 million experimental reactions) [35] [36] [37]. This teaches the model the precise "grammar" of chemistry.
- Implement Agent Frameworks: Use frameworks like ReAct (Reason + Act) that force the LLM to cycle through a process of reasoning about the task, taking an action (e.g., querying a database), and observing the result before proceeding. This breaks down complex tasks and grounds each step in real data [34].
This is a fundamental challenge as most LLMs are primarily text-based, while chemical research is inherently multimodal [33]. The agent likely lacks a designed architecture to process and cross-reference different data types.
Solution: Implement a multi-agent or tool-based architecture. A well-designed system like ChemCrow uses a single LLM as a "reasoning engine" that orchestrates multiple specialized tools [34]. For example:
- One specialized tool (or a separately fine-tuned LLM) can be dedicated to interpreting spectral data [35].
- Another tool can search synthesis literature using natural language queries [36].
- The main LLM agent then takes the outputs from these specialized tools and synthesizes them into a coherent answer or plan [34] [37].
How reliable are current LLMs at predicting synthesizability compared to traditional methods?
Recent specialized LLMs have demonstrated superior performance in predicting the synthesizability of inorganic crystals compared to traditional thermodynamic or kinetic stability measures. The Crystal Synthesis LLM (CSLLM) framework, for instance, has achieved state-of-the-art accuracy.
Table 1: Comparison of Synthesizability Prediction Methods
| Prediction Method | Metric | Reported Accuracy | Key Limitation |
|---|---|---|---|
| Synthesizability LLM (CSLLM) [38] | Accuracy on testing data | 98.6% | Requires large, high-quality datasets for fine-tuning |
| Thermodynamic Stability [38] | Energy above hull ≥ 0.1 eV/atom | 74.1% | Many metastable phases are synthesizable |
| Kinetic Stability [38] | Lowest phonon frequency ≥ -0.1 THz | 82.2% | Computationally expensive; structures with imaginary frequencies can be synthesized |
What are the key safety considerations when using LLMs to guide actual laboratory synthesis?
Safety is paramount, as LLM errors can lead to hazardous situations [33].
- Grounding in Reality: Always use the LLM in an "active" environment with tools that can check for chemical incompatibilities (e.g., reactive functional groups, strong oxidizers/reducers) [34].
- Human-in-the-Loop: Implement mandatory human review and approval for all synthesis procedures, especially those involving high-energy reactions or toxic precursors, before any physical execution [33] [34].
- Explicit Safety Checks: Program the agent to explicitly run safety checks before finalizing a procedure. For example, ChemCrow can be instructed to check the safety data sheets (SDS) of all proposed chemicals [34].
- Fail-Safes for Robotics: When connected to automated labs, ensure robotic platforms have built-in physical safety protocols (e.g., pressure release valves, inert atmosphere capabilities) that are independent of the LLM's control [1].
Advanced Optimization and Workflows
Can you provide a detailed protocol for using an LLM agent to plan and optimize a synthesis?
The following protocol is adapted from the workflows of autonomous systems like Coscientist [33], A-Lab [1], and ChemCrow [34].
Objective: Plan and execute the synthesis of a target molecule (e.g., an organocatalyst) via an LLM-powered autonomous agent.
Experimental Protocol:
Task Formulation:
- Provide the agent with a clear, natural language prompt. Example: "Find a thiourea organocatalyst that accelerates the Diels-Alder reaction. Plan and execute its synthesis." [34].
Molecular Identification and Validation:
- The agent uses its integrated tools to search scientific literature for suitable candidate molecules.
- It then verifies the molecular structures and properties by cross-referencing chemical databases (e.g., PubChem via an API call).
Retrosynthesis Planning:
- The agent calls a retrosynthesis prediction tool (e.g., AIZynthFinder) with the validated molecule's SMILES string as input.
- The tool returns several possible retrosynthetic pathways. The LLM reasons about the most feasible route based on precursor complexity and cost.
Precursor and Condition Selection:
- The agent checks the availability and safety of the proposed precursors.
- It then queries a reaction condition recommendation tool to predict optimal solvents, catalysts, and temperatures. Fine-tuned models like SynthLLM can achieve ~85% accuracy in predicting conditions for common cross-coupling reactions [35].
Procedure Validation and Execution (in silico or in roboto):
- The drafted synthesis procedure is validated against a platform's rules (e.g., checking solvent volumes, purification steps) [34].
- If errors are found (e.g., "not enough solvent"), the agent iteratively corrects the procedure.
- Upon validation, the procedure is compiled into executable code and sent to a robotic synthesis platform (e.g., RoboRXN) for physical execution [34].
Analysis and Active Learning:
- The product is characterized (e.g., via NMR or XRD). The outcome (success/failure, yield) is fed back to the agent.
- If the synthesis fails, an active learning loop is triggered. The agent uses the failure data to propose a modified recipe, for example, by avoiding low-driving-force intermediates or adjusting thermal profiles [1].
Diagram 1: LLM Agent Synthesis Workflow
What experimental reagents and computational tools are essential for setting up an LLM-driven synthesis lab?
A functional LLM-driven synthesis lab requires a combination of computational and physical research reagents.
Table 2: Essential Research Reagent Solutions for an LLM-Driven Lab
| Category | Item / Tool Name | Function / Purpose | Example / Source |
|---|---|---|---|
| Computational Tools | Base LLM | The core reasoning engine; must have strong instruction-following and tool-use capabilities. | GPT-4, Qwen (open-source) [34] [36] |
| Chemical Databases | Provide ground-truth data on molecules, reactions, and properties for validation. | USPTO, PubChem, Reaxys, Materials Project [35] [1] [38] | |
| Specialized Prediction Tools | Perform domain-specific tasks like retrosynthesis, condition recommendation, and property prediction. | AIZynthFinder (retrosynthesis), RXN (reaction prediction) [34] [37] | |
| Agent Framework | The software layer that connects the LLM to tools and manages the ReAct workflow. | LangChain, ChemCrow [34] [36] | |
| Physical Lab & Data | Robotic Synthesis Platform | Automates the physical execution of synthesis procedures. | RoboRXN, A-Lab [1] [34] |
| Automated Characterization | Provides rapid feedback on synthesis outcomes. | XRD, NMR, LC-MS [1] | |
| Broad Precursor Library | A diverse inventory of chemical starting materials to enable a wide range of syntheses. | Common organic and inorganic precursors (e.g., from Sigma-Aldrich) |
How can I improve my LLM's performance on specific chemistry tasks like precursor selection?
Beyond general fine-tuning, you can create specialized "expert" models within a larger framework.
Methodology for Fine-Tuning a Precursor Selection LLM (as demonstrated by CSLLM) [38]:
Data Curation:
- Positive Data: Collect a large set of known precursor-product pairs from databases like the ICSD (for inorganic crystals) or USPTO (for organic molecules).
- Negative Data: Construct a balanced dataset of non-synthesizable or implausible pairs. This can be done by sampling theoretical structures with low synthesizability scores from materials databases [38].
Text Representation:
- Convert crystal structures or molecules into a compact text string that includes essential information (composition, lattice parameters, space group). This "material string" is analogous to SMILES for organic molecules and is used for fine-tuning the LLM [38].
Model Fine-Tuning:
- Start with a powerful base LLM (e.g., LLaMA series).
- Perform supervised fine-tuning on the curated dataset of precursor-product pairs. The training objective is to predict the correct precursors given a target material, learning the complex relationships between products and their feasible starting materials [38] [36].
This approach has led to models that can predict solid-state precursors for common binary and ternary compounds with over 90% accuracy, significantly outperforming heuristic methods [38].
Diagram 2: Fine-Tuning a Chemistry LLM
Practical Solutions for Stalled Reactions: From Data Scarcity to Hardware Constraints
Identifying Low Driving Force Reactions Before Experimental Investment
Frequently Asked Questions
What defines a "low driving force" reaction in synthetic chemistry? A low driving force reaction is one with a small negative Gibbs free energy change (ΔG°), meaning the reaction is only slightly exergonic and releases little energy [39]. The equilibrium constant (K_eq) for such reactions is only slightly greater than 1, indicating the reaction does not strongly favor products over reactants at equilibrium [39].
Why are low driving force reactions problematic in autonomous synthesis? Low driving force reactions provide minimal thermodynamic incentive to proceed, making them highly susceptible to kinetic barriers [40] [39]. In autonomous workflows, these reactions often result in failed syntheses or low yields despite extensive optimization attempts, wasting significant robotic operational time and resources [40].
Can computational screening reliably identify low driving force reactions before experimentation? Yes, computational thermodynamics using ab initio databases like the Materials Project can calculate decomposition energies to predict stability [40]. However, research shows that decomposition energy alone does not always correlate perfectly with synthesizability, indicating that kinetic factors also play a critical role [40].
What experimental signatures suggest my reaction has a low driving force? Key indicators include: formation of persistent reaction intermediates that do not convert to the final product, consistently low yields despite extensive parameter optimization, and the reaction requiring exceptionally long times or high temperatures to proceed [40] [41].
Troubleshooting Guides
Problem: Consistently Low Target Yields Despite Precursor Optimization
Potential Cause: Low thermodynamic driving force insufficient to overcome activation barriers to product formation.
Solutions:
- Compute reaction energetics: Use ab initio databases to calculate the decomposition energy of your target. Materials with decomposition energies near zero (particularly <10 meV/atom) often present synthesis challenges [40].
- Modify target composition: Incorporate elements or functional groups that increase the thermodynamic stability of your final product.
- Employ intermediate avoidance: Use active-learning algorithms to identify and circumvent low-energy intermediates that trap the reaction pathway. The A-Lab demonstrated this approach by prioritizing intermediates with larger driving forces (>70 meV/atom) to reach the target compound [40].
- Shift to metastable targets: Consider targeting metastable phases with more favorable formation pathways, as some materials near the convex hull (with positive decomposition energies) can still be synthesized with appropriate kinetic control [40].
Problem: Formation of Persistent Intermediates That Resist Conversion
Potential Cause: Kinetic trapping in intermediate states with minimal driving force to final products.
Solutions:
- Map pairwise reaction pathways: Build a database of observed solid-state reactions to understand which intermediates form and their relative energies [40]. The A-Lab identified 88 unique pairwise reactions in its experiments, which helped predict and avoid unfavorable pathways [40].
- Apply the ARROWS³ algorithm: Implement Autonomous Reaction Route Optimization with Solid-State Synthesis, which uses active learning to integrate computed reaction energies with experimental outcomes to predict optimal solid-state reaction pathways [40].
- Increase thermal energy input: Strategically use higher temperature treatments to overcome kinetic barriers, though this must be balanced against potential decomposition.
- Alternative precursor screening: Test precursors that form intermediates with substantially larger driving forces to the final product. For CaFe₂P₂O₉ synthesis, switching from intermediates with 8 meV/atom driving force to those with 77 meV/atom increased yield by approximately 70% [40].
Problem: Computational Screening Fails to Predict Experimental Synthesis Failures
Potential Cause: Overreliance on thermodynamic predictions without considering kinetic accessibility.
Solutions:
- Integrate historical data: Use natural language processing models trained on literature synthesis data to assess target similarity and predict feasible precursors, mimicking human expert reasoning [40].
- Implement active learning cycles: Combine computational screening with robotic testing in an iterative workflow where failed experiments inform subsequent computational recommendations [40].
- Expand characterization: Include in-situ monitoring techniques to detect amorphous byproducts or transient intermediates that may indicate kinetic traps [40].
- Balance thermodynamics and kinetics: Use multi-objective optimization that considers both thermodynamic stability and predicted synthetic accessibility scores derived from literature analogs.
Quantitative Data for Reaction Assessment
Computational Screening Metrics and Their Predictive Value
| Metric | Calculation Method | Threshold for Concern | Predictive Accuracy |
|---|---|---|---|
| Decomposition Energy | Ab initio computation of energy to form compound from neighbours on phase diagram [40] | <10 meV/atom [40] | 71% success rate for >10 meV/atom [40] |
| Driving Force to Target | Energy difference between intermediate and target phases [40] | <20 meV/atom [40] | Identified in 6/9 optimized A-Lab syntheses [40] |
| Historical Similarity Score | Natural language processing of literature synthesis reports [40] | Low similarity to previously synthesized materials [40] | 35/41 successful A-Lab syntheses used literature-inspired recipes [40] |
Experimental Synthesis Outcomes from Autonomous Laboratory
| Synthesis Approach | Success Rate | Number of Targets Obtained | Average Yield |
|---|---|---|---|
| Literature-inspired recipes | 60% (35/58 targets) [40] | 35 | Not specified |
| Active learning optimization | 67% (6/9 targets) [40] | 6 | Significantly improved vs initial [40] |
| Overall A-Lab performance | 71% (41/58 targets) [40] | 41 | >50% target yield [40] |
Experimental Protocols
Protocol 1: Computational Pre-screening for Low Driving Force Reactions
Purpose: Identify potentially problematic reactions before experimental investment.
Methodology:
- Query phase stability databases: Access the Materials Project or Google DeepMind databases to obtain decomposition energies for target materials [40].
- Calculate theoretical driving forces: Compute energy differences between proposed precursors, potential intermediates, and final products using DFT-corrected formation energies [40].
- Assess synthetic accessibility: Use natural language models trained on historical synthesis data to identify analogous reactions and predict feasible precursors [40].
- Flag high-risk targets: Flag materials with decomposition energies <10 meV/atom or minimal driving forces from proposed precursors for specialized synthesis protocols [40].
Expected Outcomes: Classification of targets into high, medium, and low synthetic accessibility categories with recommended synthesis approaches for each.
Protocol 2: Active Learning Optimization for Problematic Reactions
Purpose: Iteratively improve yields for reactions identified as having low driving forces.
Methodology:
- Establish baseline: Perform initial literature-inspired synthesis attempts using robotic automation [40].
- Characterize products: Use XRD with automated Rietveld refinement to quantify phase fractions and identify persistent intermediates [40].
- Update reaction database: Record observed pairwise reactions between precursors and intermediates to build pathway knowledge [40].
- Compute alternative pathways: Use ARROWS³ algorithm to identify precursor combinations that avoid low-driving-force intermediates [40].
- Iterate synthesis conditions: Test computationally recommended alternatives, prioritizing routes with largest thermodynamic driving forces to target [40].
Expected Outcomes: For the A-Lab, this approach successfully optimized 9 targets, with 6 being obtained that had zero yield from initial recipes [40].
Workflow Visualization
Research Reagent Solutions
| Reagent/Resource | Function | Application Example |
|---|---|---|
| Materials Project Database | Provides ab initio computed phase stability data [40] | Screening target compounds for thermodynamic stability before synthesis attempts [40] |
| ARROWS³ Algorithm | Active learning integration of computed energies and experimental outcomes [40] | Optimizing solid-state reaction pathways by avoiding low-driving-force intermediates [40] |
| Automated XRD with Rietveld Refinement | Quantifies phase fractions in synthesis products [40] | Identifying persistent intermediates that indicate kinetic traps in reaction pathways [40] |
| Natural Language Processing Models | Assess target similarity from literature synthesis data [40] | Proposing initial synthesis recipes based on analogous successful syntheses [40] |
| Pairwise Reaction Database | Catalogues observed solid-state reactions between precursors [40] | Predicting reaction pathways and reducing redundant experimental testing [40] |
Overcoming Data Scarcity with Augmented Synthetic Data and Transfer Learning
Frequently Asked Questions
| Question | Answer |
|---|---|
| What are the primary causes of sluggish reaction kinetics in autonomous synthesis? | Sluggish kinetics are often caused by reaction steps with low thermodynamic driving forces (e.g., <50 meV per atom), which slow down reaction rates and can prevent the formation of the target material [1]. |
| How can synthetic data help overcome real data scarcity in this field? | Synthetic data replicates the mathematical and statistical properties of real data, creating ample, diverse datasets for training machine learning (ML) models that control autonomous labs, thus overcoming the scarcity and privacy issues of real-world experimental data [42] [43]. |
| What is the role of transfer learning in autonomous materials discovery? | Transfer learning allows knowledge from one synthesis context to be applied to another. The A-Lab, for instance, uses ML models trained on vast historical literature data to propose initial synthesis recipes for novel target materials, mimicking a human expert's use of analogy [1]. |
| What are the main types of synthetic data, and which is best for synthesis research? | The main types are Fully Synthetic (created from scratch), Partially Synthetic (some real data points are modified), and Hybrid Synthetic (a blend of real and synthetic data). The choice depends on the need for privacy and the availability of initial real data; hybrid approaches often balance utility and realism effectively [43]. |
| How do I validate that my synthetic data is accurate enough? | Validation involves statistical testing (e.g., comparing distributions with KS-tests), predictive performance checks, and, crucially, review by domain experts to ensure the data realistically represents the chemical phenomena being modeled [43]. |
Troubleshooting Guides
Guide 1: Troubleshooting Slow Reaction Kinetics
Problem: Synthesis reactions are not proceeding to completion, or target yield is low due to slow kinetics, a issue that hindered 11 out of 17 failed syntheses in a major autonomous lab study [1].
| Step | Action | Rationale & Details |
|---|---|---|
| 1 | Calculate Driving Forces | Use ab initio computation (e.g., via the Materials Project) to identify reaction steps with low driving forces (<50 meV per atom), which are likely kinetic bottlenecks [1]. |
| 2 | Analyze Reaction Pathway | Use an active learning algorithm (e.g., ARROWS³) to map the solid-state reaction pathway and identify intermediate phases with small driving forces to form the target [1]. |
| 3 | Design Alternative Route | Propose a new precursor set or synthesis route that avoids intermediates with low driving forces, prioritizing those with a larger driving force (>70 meV per atom) to form the target [1]. |
| 4 | Validate with High-Throughput Screening | Use an automated platform to experimentally screen the alternative synthesis recipes and measure the resulting target yield [44]. |
Guide 2: Troubleshooting Poor Synthetic Data Quality
Problem: Machine learning models trained on your synthetic data are not generalizing well or are producing inaccurate predictions for real-world experiments.
| Step | Action | Rationale & Details |
|---|---|---|
| 1 | Profiling & Understanding | Perform a thorough statistical analysis (e.g., using ydata-profiling) of your original real dataset to understand its distributions, correlations, and relationships [43]. |
| 2 | Select Appropriate Technique | Choose a data generation method suited to your data type. Generative Adversarial Networks (GANs) are powerful for high-dimensional data, while rule-based generation is ideal for scenarios with known business logic [42] [43]. |
| 3 | Implement Quality Gates | Integrate automated validation and bias detection algorithms into your data generation pipeline. Use a DataValidator and BiasDetector to ensure quality and fairness [45]. |
| 4 | Continuous Monitoring | Regularly update and refine your synthetic data generators to reflect new real-world data and changing requirements, ensuring long-term reliability [43]. |
Experimental Protocols
Protocol 1: Generating Synthetic Data via a Generative Adversarial Network (GAN)
Objective: To create a high-quality, fully synthetic dataset that mimics the statistical properties of a scarce real dataset on reaction outcomes.
- Data Preparation: Compile all available real experimental data, including precursors, conditions (temperature, time), and outcomes (e.g., yield, purity). Clean and normalize the data.
- Model Selection: Implement a Generative Adversarial Network (GAN) framework. The generator creates synthetic data samples, and the discriminator evaluates their authenticity against the real data [43].
- Training: Train the GAN on the prepared real data. The training process is an adversarial game where the generator improves its output until the discriminator can no longer distinguish synthetic from real data.
- Generation & Validation: Use the trained generator to produce the required volume of synthetic data. Validate the output by ensuring its statistical properties (distribution, correlation) match the original data using tests like the Kolmogorov-Smirnov test [43].
Protocol 2: Implementing a Transfer Learning Workflow for Reaction Optimization
Objective: To leverage a pre-trained model on a large, general chemistry dataset to accelerate the optimization of a specific reaction with limited data.
- Base Model Acquisition: Select a pre-trained large language model (LLM) with broad chemical knowledge, such as GPT-4, which has been used to power specialized agents for chemical synthesis [44].
- Specialization (Fine-Tuning): Fine-tune the base model on your specific, smaller dataset related to the target reaction (e.g., aerobic alcohol oxidation). This process adapts the model's general knowledge to your specific domain [44].
- Integration into an Autonomous Loop: Deploy the fine-tuned model as an "Experiment Designer" or "Result Interpreter" agent within an autonomous research framework (e.g., LLM-RDF). The agent can propose new experiments and analyze results [44].
- Active Learning: Close the loop by using an active learning algorithm (e.g., ARROWS³) that uses the model's predictions and experimental outcomes to iteratively propose and validate improved synthesis recipes with high target yield [1].
Workflow Visualization
Synthetic Data and Transfer Learning Workflow
Troubleshooting Sluggish Kinetics
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function |
|---|---|
| Cu/TEMPO Catalyst System | A sustainable catalytic system for the aerobic oxidation of alcohols to aldehydes; avoids expensive metals and demonstrates chemoselectivity [44]. |
| Automated High-Throughput Screening (HTS) Platform | Robotics system that enables rapid experimental testing of hundreds of substrate and condition combinations, generating crucial data to overcome scarcity [44]. |
| LLM-Based Research Framework (LLM-RDF) | A framework comprising specialized AI agents (e.g., Literature Scouter, Experiment Designer) to automate and guide the end-to-end synthesis development process via natural language [44]. |
| Active Learning Algorithm (ARROWS³) | An algorithm that integrates computed reaction energies with experimental outcomes to predict and optimize solid-state reaction pathways, avoiding kinetic traps [1]. |
| Synthetic Data Generation Tools (e.g., Gretel, MOSTLY.AI, SDV) | Software platforms and Python libraries that use AI to generate privacy-preserving, high-quality synthetic datasets that mimic real data for model training [43]. |
Hardware Innovations for Enhanced Mixing, Milling, and Temperature Control
In the field of autonomous materials discovery, sluggish reaction kinetics represent a significant bottleneck. When reaction steps have a low driving force (often cited as below 50 meV per atom), the system can become trapped in metastable states, preventing the formation of the desired target material [1]. Advanced hardware for mixing, milling, and temperature control is critical for overcoming this challenge by providing the energy and conditions necessary to drive these slow solid-state reactions to completion. This technical support center provides troubleshooting guides and FAQs to help researchers optimize these critical hardware-dependent processes within their autonomous workflows.
Frequently Asked Questions (FAQs)
Q1: How do temperature fluctuations during milling impact my synthesis yield?
Temperature is a critical variable that directly influences viscosity, reaction kinetics, and particle agglomeration [46]. Inadequate temperature control can prevent the necessary chemical reactions from occurring at the desired rate, leading to unwanted byproducts and significantly reduced yield. This is a common cause of sluggish reaction kinetics [1] [46]. Precise temperature regulation ensures consistent results from batch to batch.
Q2: My robotic synthesis platform is not dispensing liquids consistently. What could be wrong? Inconsistent liquid dispensing can be caused by several factors [47]:
- Pressure Supply Issues: A recent change in bottle pressure requires the system to be recalibrated.
- Valve Failure: The liquid valve, particularly for acidic reagents, may be failing and require replacement.
- Line Obstructions: Particulates or crystallization in the liquid lines can inhibit flow. Regularly flushing lines with an appropriate solvent (like Acetonitrile) is recommended.
- Insufficient Flow: Ensure the pressure supply to the bottle has sufficient flow and that the lines are not kinked.
Q3: Why is my automated system struggling to synthesize targets identified as stable by computational screening?
Computational stability is only one factor. Experimental realization faces hurdles like slow kinetics, precursor volatility, and amorphization [1]. Furthermore, precursor selection has a profound influence on the synthesis path. Even for stable materials, only a fraction of attempted recipes may succeed, as the choice of precursor can determine whether the reaction forms the target or becomes trapped in a metastable state [1].
Q4: What is the role of specialized hardware like rotor-stators in overcoming kinetic barriers?
Innovative hardware like temperature-regulated rotor-stators represents a leap forward [46]. This equipment achieves particle deagglomeration and dispersion while efficiently controlling the material's temperature via a jacketed dome and vessel. This is crucial for temperature-sensitive applications and for managing viscosity, which directly impacts process efficiency and the ability to drive slow reactions [46].
Troubleshooting Guides
Guide: Overcoming Sluggish Reaction Kinetics
Sluggish kinetics are identified when a thermodynamically stable target material fails to form, often due to reaction steps with low driving forces [1].
Step 1: Identify the Problem
- Confirm the target is computationally stable and that the failure is not due to precursor volatility or amorphization [1].
- Analyze the reaction pathway to identify steps with a low driving force (<50 meV per atom) [1].
Step 2: List Possible Explanations & Solutions Table: Troubleshooting Sluggish Reaction Kinetics
| Possible Cause | Data to Collect | Corrective Experimentation |
|---|---|---|
| Low Reaction Driving Force | Calculate reaction energies for all potential intermediate phases using ab initio data [1]. | Use an active-learning algorithm to propose alternative precursor sets that avoid low-driving-force intermediates [1]. |
| Insufficient Milling Energy | Analyze particle size distribution pre- and post-milling. | Optimize milling duration and intensity. Ensure temperature is controlled during milling to prevent unwanted agglomeration [46]. |
| Sub-Optimal Thermal Profile | Review the heating data (temperature, ramp rate, dwell time) from failed experiments. | Propose a higher synthesis temperature using a machine learning model trained on literature heating data [1]. Implement a multi-step heating profile. |
Step 3: Implement and Verify
- Execute the highest-priority corrective recipe.
- Characterize the product via XRD and use probabilistic ML models to analyze phase and weight fractions [1].
- If successful, update the active-learning database; if not, proceed down the list of possible solutions.
Guide: Resolving Hardware Malfunctions in Automated Synthesizers
Problem: Machine will not power on [47].
- Step 1: Check if an Emergency Stop (
E-stop) has been activated. - Step 2: Inspect the control box for a blown fuse. Replace it with a similar type if necessary.
- Step 3: Check for and clean up any spills or exposed wires that may have caused a short circuit.
Problem: Pressure leak / Argon supply not lasting long [47].
- Step 1: Verify the Argon supply pressure is below 25 PSI (recommended 10-20 PSI range).
- Step 2: The most common leak location is a loose reagent bottle cap. Ensure all caps are secured tightly and that O-rings are not cracked or compromised. Replace O-rings as needed.
Problem: Liquid not dispensing [47].
- Step 1: Confirm the correct liquid bottle position is being used and that it is receiving adequate pressure.
- Step 2: Ensure the liquid sensor is dry (look for a green light).
- Step 3: Listen for the sound of the solenoid valve firing. If no sound is heard, the valve may need replacement. Tapping it lightly may help.
- Step 4: Check liquid lines for kinks or crystallization.
Experimental Protocols & Workflows
Protocol for an Autonomous Kinetics-Optimization Experiment
This protocol leverages the A-Lab's workflow for identifying synthesis routes that overcome kinetic barriers [1].
1. Target Input & Recipe Proposal:
- Provide the target compound's composition to the autonomous management system.
- The system generates up to five initial synthesis recipes using a natural-language processing model trained on historical literature data [1].
- A separate ML model proposes an initial synthesis temperature [1].
2. Robotic Execution:
- A robotic station dispenses and mixes precursor powders, then transfers them into an alumina crucible [1].
- A robotic arm loads the crucible into a box furnace for heating under the proposed conditions [1].
3. Product Characterization & Analysis:
- After cooling, the sample is robotically transferred to a station where it is ground into a fine powder and measured by X-ray diffraction (XRD) [1].
- The XRD pattern is analyzed by ML models to identify phases and determine weight fractions via automated Rietveld refinement [1].
4. Active Learning & Pathway Optimization:
- If the target yield is below 50%, the active learning cycle (
ARROWS3) is initiated [1]. - The algorithm uses a growing database of observed
pairwise reactionsto infer pathways and avoid intermediates with a small driving force to form the target [1]. - It then proposes a new, optimized recipe with a higher probability of success, and the loop (steps 2-4) repeats.
The following workflow diagram illustrates this closed-loop, autonomous process:
Autonomous Kinetics Optimization Workflow
Protocol for Temperature-Dependent Viscosity Profiling
Understanding how temperature affects your precursor mixture's viscosity is key to optimizing milling and dispersion processes [46].
1. Equipment Setup:
- Use a temperature-regulated disperser or mixer (e.g., a rotor-stator system with a jacketed vessel for coolant/heated fluid circulation) [46].
- Ensure the system is equipped with a viscosity probe or a means to measure power draw, which correlates with viscosity.
2. Data Collection:
- Prepare a standard batch of your precursor mixture.
- Set the disperser to a constant shear rate.
- Measure the viscosity (or power draw) at temperature intervals (e.g., every 5°C) across a relevant range (e.g., 20°C to 60°C).
- Record the data in a table for analysis.
Table: Example Data Table for Viscosity Profiling
| Temperature (°C) | Viscosity (cP) / Power Draw (W) | Observations (e.g., flow, agglomeration) |
|---|---|---|
| 20 | ||
| 25 | ||
| 30 | ||
| ... |
3. Analysis and Optimization:
- Plot temperature against viscosity to identify the optimal range for processing.
- A decrease in viscosity with rising temperature generally leads to smoother blending and reduced process times [46].
- Select the operational temperature that provides the lowest practical viscosity without causing precursor degradation or solvent loss.
The Scientist's Toolkit: Key Research Reagent Solutions
Table: Essential Hardware and Reagents for Optimizing Mixing and Milling
| Item | Function / Explanation |
|---|---|
| Temperature-Regulated Rotor-Stator | Provides simultaneous particle deagglomeration/dispersion and precise temperature control via a jacketed design, crucial for managing viscosity and reaction kinetics [46]. |
| Precursor Powder Library | A diverse collection of high-purity, well-characterized solid precursors. The selection of precursors is a primary factor in determining the synthesis pathway and overcoming kinetic barriers [1]. |
| Acetonitrile (or other wash solvents) | Used to flush and clean liquid lines in automated synthesizers to prevent clogs caused by crystallized reagents, ensuring consistent liquid dispensing [47]. |
| Replacement Valves & O-rings | Critical spares for automated fluidic systems. Leaky valves or compromised O-rings are common causes of pressure loss and inconsistent reagent delivery [47]. |
| Inert Gas Supply (e.g., Argon) | Used to maintain an inert atmosphere over sensitive reagents and reactions. Pressure must be regulated (typically 10-20 PSI) to prevent venting and ensure system safety [47]. |
Troubleshooting Logic Flowchart
The following diagram provides a logical pathway for diagnosing and addressing the common issue of failed synthesis in an autonomous lab, integrating both hardware and chemical considerations.
Synthesis Failure Diagnosis Flowchart
Core Concepts: Persist vs. Pivot
In autonomous synthesis research, particularly when addressing challenging problems like sluggish reaction kinetics, researchers must continually assess whether to persist with the current experimental strategy or pivot to a fundamentally new approach [48]. This decision is a structured course correction designed to test a new fundamental hypothesis about the product, strategy, or engine of growth, and should be made without a change in the overarching scientific vision [48].
Decision Framework: When to Persist vs. Pivot
| Decision | When to Choose | Key Indicators |
|---|---|---|
| Persist [49] [48] | The core hypothesis remains valid and experiments show progressive validation of assumptions [48]. | Consistent, positive progress in key metrics; high customer satisfaction; a proven, sustainable business model [49] [48]. |
| Pivot [50] [49] [48] | Feedback is negative/indifferent, data doesn't support core assumptions, or a single feature/showing significantly outperforms the rest [48]. | Misalignment with market needs; weak/no growth metrics; resource strain with no clear path; competitor dominance; product-market misfit [50] [49]. |
Common types of pivots in a research strategy include:
- Zoom-In Pivot: A single feature or reaction condition becomes the entire new focus [48].
- Customer Segment Pivot: The solution should target a different research problem or application area [48].
- Technology Pivot: Changing the core technology or synthetic methodology to achieve the same outcome more efficiently [48].
- Value Capture Pivot: Changing how the success or utility of a synthesis is measured and evaluated [48].
Troubleshooting Guide & FAQs
FAQ 1: My autonomous synthesis campaigns are yielding stagnant results. How can I determine if the problem is with my strategy or just the parameters?
This is a classic sign to re-examine your Problem-Solution Fit [50]. Conduct a structured assessment by asking:
- Is the problem worth solving? Does your target research community or application area truly care about this specific kinetic challenge? [50]
- Are the results useful? Would the potential outcomes of your research be adopted, or are there fundamental barriers (e.g., cost, scalability, stability) that your approach does not address? [50]
If the answer to either is "no," it is a strong indicator that a pivot may be necessary. If the answers are "yes," then persevering with an optimization of your parameters is likely the correct path [50].
FAQ 2: What are the most critical metrics to monitor in a self-driving lab to inform a persist/pivot decision?
While application-specific metrics are vital, several general Key Performance Indicators (KPIs) can guide your decision:
- Plateauing Customer Acquisition Rates: In a research context, this can be interpreted as a lack of new research questions or applications being enabled by your methodology [50].
- Low Engagement or Retention: This translates to the inability of other researchers to reproduce or build upon your published synthetic protocols, indicating a potential flaw in the robustness or generalizability of the approach [50].
- Success Rate per Design-Make-Test-Analyze (DMTA) Cycle: A low or declining rate of successful experiments/hits indicates the underlying model or hypothesis may be flawed [11].
FAQ 3: My experimental data is highly variable. How can I confidently decide on a direction?
Embrace Bayesian Optimization algorithms, such as the Phoenics algorithm, which are designed to handle noisy data and can efficiently guide experimentation even with significant uncertainty [11]. These algorithms propose new experimental conditions by balancing exploration (testing new, uncertain regions of parameter space) and exploitation (refining known promising conditions), which is a more robust strategy than simple parameter sweeping [11].
FAQ 4: We have a promising lead but progress has slowed. Should we pivot or persevere?
First, diagnose the nature of the slowdown. If you are making incremental, measurable progress and each DMTA cycle provides new learning, you should persevere [48]. However, if you are in a "dire situation" of running in neutral—consuming resources but making no material progress—it is a clear sign to consider a pivot [48]. The most common regret among successful teams is not pivoting earlier [48].
Detailed Experimental Protocols
Protocol 1: Implementing a Structured "Pivot or Persevere" Meeting
Regular, scheduled decision-making meetings are a best practice to avoid emotional or delayed pivots [48].
- Objective: To make a data-driven decision on whether to continue the current research strategy (Persevere), change it (Pivot), or terminate the project (Stop) [48].
- Frequency: No more than once a month, but no less than once per quarter [48].
- Methodology:
- Review Evidence: Present all experimental data from the last period. Use a SWOT Analysis (Strengths, Weaknesses, Opportunities, Threats) to take a comprehensive and honest look at your current position [50].
- Evaluate Progress Against Hypotheses: Ask: "What evidence do we have that our current strategy is getting us closer to achieving our vision?" [48] Focus on validating your "leap of faith assumptions." [48]
- Make the Decision:
Protocol 2: The Build-Measure-Learn Loop for Kinetic Optimization
This Lean Startup method, applied to research, creates a rigorous framework for iteration [50].
- Objective: To use data from small-scale experiments to refine your approach rapidly [50].
- Workflow:
- BUILD: Design a small, focused experiment—a minimal viable experiment—to test a specific aspect of your reaction (e.g., a narrow range of catalysts and temperatures) [50].
- MEASURE: Execute the experiment in your self-driving lab and collect performance metrics (e.g., yield, conversion rate, kinetics). Use actionable metrics that are directly tied to your kinetic challenge [50].
- LEARN: Analyze the results to confirm or deny your hypothesis. The learning from this analysis dictates the next cycle—whether to persevere and optimize further or pivot to a new catalytic system or mechanism [50].
Protocol 3: Multi-Functional Interface Modification for Material Synthesis
This protocol, adapted from battery research, exemplifies a "persist" strategy where a core material is retained but its interface is intelligently adapted to overcome kinetic limitations [51].
- Objective: To improve electrochemical performance by enhancing ionic transport and stability at the interface, rather than abandoning the core cathode material [51].
- Synthesis Workflow:
- Synthesize Single-Crystal Particles: Replace secondary spherical structures with submicron single-crystal structures. This promotes better solid-solid contact with the solid-state electrolyte, shortening ion/electron transport paths [51].
- Apply Multi-Functional Coating: Use in-situ high-temperature reactions to construct a Li-gradient layer and a lithium molybdate coating on the particle surface. This accelerates Li-ion transport and suppresses interfacial side reactions [51].
- Characterize: Use techniques like HAADF-STEM and TOF-SIMS to validate the enhanced Li-ion diffusion kinetics and interfacial stability [51].
The Scientist's Toolkit: Essential Research Reagent Solutions
| Item / Solution | Function / Rationale | Example in Context |
|---|---|---|
| Bayesian Optimization Algorithms (e.g., Phoenics) | Proposes new experiments by balancing exploration and exploitation, efficiently navigating high-dimensional parameter spaces even with noisy data [11]. | Optimizing a multi-component reaction mixture (e.g., for organic photovoltaics or Suzuki-Miyaura cross-couplings) to find the global maximum in performance [11]. |
| Orchestration Software (e.g., ChemOS) | Democratizes autonomous discovery by providing hardware-agnostic software to orchestrate experiment scheduling, machine learning, and database management [11]. | Managing a geographically distributed "meta-laboratory" where synthesis and characterization equipment are in different locations but function as a single, closed-loop system [11]. |
| Standardized Data Frameworks (e.g., Molar DB) | Ensures no data is lost and allows rolling back the database to any point in time. Critical for reproducibility and for reusing past data to guide future campaigns [11]. | Creating a shareable, high-quality dataset of both positive and negative results from a self-driving lab campaign, which is essential for training robust machine learning models [11]. |
| Cellular Thermal Shift Assay (CETSA) | Validates direct target engagement of a drug candidate in intact cells and tissues, providing physiologically relevant confirmation of mechanistic action [52]. | Confirming that a newly synthesized molecule intended to inhibit a specific kinase actually binds to and stabilizes that target within a complex cellular environment [52]. |
| Multi-Functional Surface Modification | A materials strategy that involves coating a core material to enhance interfacial properties without changing its bulk structure, addressing kinetics and stability issues directly [51]. | Coating a Li-rich manganese-based cathode particle with a lithium molybdate layer to accelerate Li-ion transport and suppress side reactions in an all-solid-state battery [51]. |
Error Detection and Recovery Protocols for Unanticipated Kinetic Barriers
Foundational Concepts: Kinetic Barriers in Autonomous Synthesis
In autonomous materials discovery, a kinetic barrier is any reaction pathway obstacle that prevents a thermodynamically favorable synthesis from proceeding at an observable rate within standard experimental timeframes. The A-Lab, an autonomous laboratory for solid-state synthesis, identified sluggish reaction kinetics as the primary cause of failure in nearly 65% of its unobtained target materials [1]. These barriers often manifest when reaction steps have low thermodynamic driving forces, typically below 50 meV per atom [1]. Effective protocols must therefore focus on detecting these barriers in real-time and implementing corrective actions through adaptive experimental workflows.
Detection Protocols: Identifying Kinetic Barriers
What experimental signatures indicate a kinetic barrier is present?
Kinetic barriers present several observable signatures during autonomous synthesis experiments:
Phase Persistence: Intermediate phases identified via X-ray diffraction (XRD) persist through standard heating profiles and fail to convert to the target material despite thermodynamic favorability [1]. The A-Lab used automated XRD analysis with machine learning interpretation to detect these stalled intermediates in real-time.
Low Driving Force Metrics: Reactions with computed decomposition energies below 50 meV per atom, as calculated using formation energies from databases like the Materials Project, are prime candidates for kinetic limitations [1].
Reaction Profile Deviations: In liquid-phase organic synthesis, kinetic barriers manifest as incomplete conversions detected via real-time analytical monitoring. Benchtop NMR spectroscopy can identify persistent starting materials or stable intermediates when tracked kinetically [53] [54].
What quantitative thresholds define a kinetic barrier?
The table below summarizes key quantitative indicators of kinetic barriers established through high-throughput experimentation:
Table: Quantitative Thresholds for Kinetic Barrier Identification
| Parameter | Threshold Value | Measurement Technique |
|---|---|---|
| Driving Force per Atom | <50 meV/atom | Computational Thermodynamics (DFT) [1] |
| Reaction Yield | <10% after standard duration | XRD Phase Analysis [1] |
| Intermediate Phase Conversion | <5% per hour at optimal temperature | XRD Time-Series Analysis [1] |
| Synthetic Error Rate | >2 errors/kb in DNA synthesis | Next-Generation Sequencing [55] |
Recovery Protocols: Overcoming Kinetic Barriers
How do I modify synthesis parameters to overcome kinetic limitations?
The Autonomous Reaction Route Optimization with Solid-State Synthesis (ARROWS³) algorithm successfully recovered six initially failed targets in the A-Lab by implementing these parameter modifications [1]:
Precursor Substitution: Replace precursors that form low-driving-force intermediates (e.g., for CaFe₂P₂O₉ synthesis, avoiding FePO₄ and Ca₃(PO₄)₂ intermediates with only 8 meV/atom driving force) [1].
Temperature Profile Optimization: Implement stepped heating profiles with extended dwell times at critical transition temperatures identified through active learning.
Reaction Pathway Engineering: Design alternative synthesis routes that form intermediates with substantially larger driving forces to the target material (>70 meV/atom) [1].
What algorithmic approaches enable autonomous recovery?
The following workflow illustrates the core decision-making process for autonomous kinetic barrier recovery:
Autonomous Kinetic Barrier Recovery Workflow
Implementation Framework
What hardware systems are essential for implementing these protocols?
Successful implementation requires an integrated hardware-software architecture:
Robotic Material Handling: Three integrated stations for powder dispensing, mixing, and crucible transfer, as implemented in the A-Lab, enable rapid iteration of synthesis recipes [1].
Real-Time Characterization: Inline X-ray diffraction (XRD) with automated Rietveld refinement provides immediate feedback on phase composition and conversion percentages [1].
Flow Chemistry Systems: For solution-phase synthesis, automated platforms with real-time NMR monitoring (e.g., Spinsolve systems) enable continuous tracking of reaction progress and intermediate detection [53].
What computational infrastructure supports these protocols?
Reaction Database Integration: Access to computed thermodynamic data from sources like the Materials Project provides essential driving force calculations [1].
Active Learning Algorithms: Bayesian optimization approaches leverage historical data to propose improved synthesis recipes with minimal experimental iterations [1].
Natural Language Processing: Models trained on literature synthesis data propose initial recipes based on analogy to known materials, mimicking human expert reasoning [1].
The Scientist's Toolkit: Research Reagent Solutions
Table: Essential Materials and Technologies for Kinetic Barrier Research
| Reagent/Technology | Function | Application Example |
|---|---|---|
| Non-canonical Nucleosides (7-deaza-2'-deoxyguanosine) | Error-proof nucleosides that resist synthetic errors | 50-fold reduction in G-to-A substitution rates in DNA synthesis [55] |
| Phenoxyacetic Anhydride | Capping reagent that minimizes side reactions | Suppresses G-to-A substitutions when used instead of standard capping agents [55] |
| Benchtop NMR Spectrometers (e.g., Spinsolve) | Real-time reaction monitoring | Tracking reaction kinetics and identifying stable intermediates in flow chemistry [53] |
| Control Barrier Functions (CBFs) | Safety filters for robotic systems | Limits kinetic energy in collaborative robots to ensure operational safety [56] |
Frequently Asked Questions
Our autonomous platform consistently fails to synthesize targets with low decomposition energies. Which recovery strategy should we prioritize?
Precursor substitution should be your primary recovery strategy. The A-Lab demonstrated that 6 of 17 initially failed targets were successfully recovered by identifying and avoiding precursors that form low-driving-force intermediates [1]. Implement a database of alternative precursors ranked by computed driving forces to your target material, prioritizing those with predicted driving forces >70 meV/atom.
How can we distinguish between thermodynamic instability and kinetic barriers in failed syntheses?
Compute the decomposition energy of your target material using databases like the Materials Project. For targets on or near the convex hull (decomposition energy <10 meV/atom), thermodynamic instability is unlikely [1]. Instead, characterize synthesis products via XRD - persistent intermediates with low driving forces to the target (<50 meV/atom) indicate kinetic barriers, not thermodynamic instability.
What is the minimum detectable synthetic error rate we should design our protocols to handle?
Next-generation sequencing studies of synthetic DNA have quantified baseline error rates as low as 2 errors per kilobase [55]. Your protocols should be sensitive enough to detect and correct errors at this frequency, particularly G-to-A substitutions which occur most frequently and can be suppressed 50-fold using error-proof nucleosides like 7-deaza-2'-deoxyguanosine [55].
Which real-time monitoring technique provides the most comprehensive data for kinetic barrier detection?
While XRD is ideal for solid-state synthesis [1], benchtop NMR spectroscopy provides superior capability for solution-phase reactions. Modern systems can be installed directly in fume hoods and provide quantitative, non-destructive analysis with continuous flow capabilities, enabling real-time tracking of reaction kinetics and intermediate formation [53].
Benchmarking Success: Validating Kinetic Solutions Across Platforms
Troubleshooting Guides and FAQs
FAQ: What are the primary causes of sluggish reaction kinetics, and how do A-Lab and AutoBot address them?
Sluggish kinetics, a major barrier to synthesis, often arise from reaction steps with low driving forces (typically <50 meV per atom). Both A-Labs and AutoBot identify this through real-time characterization and use active learning to circumvent these pathways. A-Lab specifically uses thermodynamic data from sources like the Materials Project to avoid intermediates with small driving forces to form the final target [1]. AutoBot addresses this by holistically optimizing multiple synthesis parameters (e.g., temperature, timing, humidity) to find conditions that favor faster kinetics, even in less-stringent environments [57].
FAQ: An experiment in our autonomous lab failed to produce the target material. What is the systematic troubleshooting process?
Follow this logical troubleshooting pathway, which synthesizes the decision-making of advanced platforms:
FAQ: Our AI model seems to be learning slowly, requiring too many experiments. How can we improve the learning rate?
This is often due to inefficient experimental sampling. AutoBot demonstrated a solution by using machine learning algorithms that prioritize the most informative parameter combinations, maximizing information gain with each iteration. It achieved a "super-fast learning rate," needing to sample only about 1% of a 5,000-combination parameter space to find the optimal synthesis "sweet spot" [57]. Ensure your active learning algorithm is designed for optimal experimental design (OED) rather than just random or grid sampling.
FAQ: How do we handle multimodal data (e.g., spectroscopy and imaging) to generate a single, actionable metric for the AI?
This requires a "multimodal data fusion" strategy. The approach is to use data science and mathematical tools to integrate disparate datasets into a single quantitative score. For example, in AutoBot, photoluminescence images were converted into a single number based on the variation of light intensity across the images. This quantified film homogeneity was then combined with UV-Vis and PL spectroscopy data into a single score representing overall film quality, which the AI could use for decision-making [57].
Comparative Performance Data
The table below summarizes key quantitative data from the operations of A-Lab and AutoBot, highlighting their performance in optimizing synthesis kinetics.
| Performance Metric | A-Lab | AutoBot |
|---|---|---|
| Primary Synthesis Focus | Inorganic powders (e.g., oxides, phosphates) [1] | Thin-film metal halide perovskites [57] |
| Experiment Duration | 17 days of continuous operation [1] | Several weeks [57] |
| Traditional Method Timeline | Up to a year (estimated for manual parameter search) [57] | Up to a year (manual trial-and-error) [57] |
| Success Rate | 41 of 58 novel compounds synthesized (71%) [1] | Pinpointed optimal synthesis combinations [57] |
| Key Kinetics Insight | Identified sluggish kinetics (<50 meV/atom driving force) as primary failure mode for ~65% of unobtained targets [1] | Determined that high humidity (>25%) destabilizes precursors and slows film formation kinetics [57] |
| Optimization Strategy | Active learning (ARROWS3) using ab initio reaction energies to avoid low-driving-force intermediates [1] | Iterative ML-guided adjustment of 4 synthesis parameters (time, temp, duration, humidity) [57] |
| Sampling Efficiency | Not explicitly quantified | Sampled only ~1% of >5,000 parameter combinations to find optimum [57] |
Detailed Experimental Protocols
Protocol 1: AutoBot Workflow for Perovskite Thin-Film Optimization
This protocol outlines the iterative loop for optimizing the synthesis of metal halide perovskite films, a process that can overcome kinetic barriers in higher-humidity environments [57].
- Automated Synthesis: The robotic system prepares perovskite films from chemical precursor solutions. Four key parameters are varied autonomously:
- Timing of crystallization agent treatment.
- Heating temperature.
- Heating duration.
- Relative humidity in the deposition chamber.
- Multimodal Characterization: Immediately after synthesis, each sample is characterized using three techniques concurrently:
- UV-Vis Spectroscopy: Measures the transmission of ultraviolet and visible light to assess basic optical properties.
- Photoluminescence (PL) Spectroscopy: Shines light on the sample and measures the emitted light to evaluate optoelectronic quality.
- PL Imaging: Uses the emitted light to generate a spatial image of the sample, which is used to compute thin-film homogeneity.
- Data Fusion and Scoring: A custom data workflow extracts features from all three characterization results. These are analyzed and fused into a single numerical score that quantifies the overall film quality.
- Machine Learning and Decision: The film quality score is fed into a machine learning algorithm. The algorithm updates its model of the relationship between the four synthesis parameters and the resulting film quality. It then uses an "informative sampling" strategy to select the parameter combination for the next experiment that is expected to provide the most information, thereby accelerating the convergence to the optimal recipe.
Protocol 2: A-Lab Workflow for Novel Inorganic Powder Synthesis
This protocol describes the closed-loop cycle for synthesizing and optimizing inorganic compounds, designed to navigate around kinetic limitations [1].
- Target Selection & Recipe Proposal:
- Targets are selected from computational databases (e.g., Materials Project) predicted to be thermodynamically stable.
- Up to five initial synthesis recipes are generated using natural language models trained on historical literature data, mimicking a human's analogy-based approach.
- A synthesis temperature is proposed by a second ML model trained on heating data.
- Robotic Synthesis:
- Precursor powders are automatically dispensed and mixed by a robotic arm in an alumina crucible.
- The crucible is loaded into one of four box furnaces for heating according to the proposed recipe.
- Automated Characterization & Analysis:
- After cooling, the sample is robotically transferred, ground into a fine powder, and measured by X-ray Diffraction (XRD).
- The XRD pattern is analyzed by probabilistic machine learning models to identify phases and their weight fractions. The target's pattern is from computed structures.
- Results are confirmed with automated Rietveld refinement.
- Active Learning Optimization:
- If the target yield is below 50%, the active learning algorithm (ARROWS3) takes over.
- The algorithm integrates the experimental outcome with ab initio computed reaction energies from databases.
- It identifies and prioritizes reaction pathways that avoid intermediates with a low driving force to form the target, thereby overcoming sluggish kinetics. It also leverages a growing database of observed pairwise solid-state reactions to prune the search space of ineffective recipes.
Research Reagent Solutions
The following table lists key materials and their functions as utilized in the featured autonomous laboratories.
| Reagent/Material | Function in Experiment |
|---|---|
| Metal Halide Perovskite Precursors (e.g., PbBr₂, CsBr) | Chemical starting materials for forming the desired light-absorbing/emitting perovskite thin films in AutoBot [57]. |
| Inorganic Oxide & Phosphate Precursors | Powdered solid-state reactants (e.g., metal oxides) used by A-Lab to synthesize novel inorganic compounds via solid-state reaction [1]. |
| Crystallization Agent (e.g., antisolvent) | A chemical treatment used in thin-film deposition to control the crystallization kinetics and morphology of the perovskite layer in AutoBot [57]. |
| Alumina Crucibles | High-temperature resistant containers used in box furnaces for solid-state reactions in A-Lab [1]. |
| Ligands (e.g., organic acids/bases) | Surface-binding molecules used in nanocrystal synthesis to control growth, stability, and optical properties, as explored in systems like Rainbow [58]. |
A fundamental challenge in autonomous synthesis research is overcoming intrinsically sluggish reaction kinetics, which traditionally create significant bottlenecks in the discovery and optimization of novel materials. The iterative "design-make-test-analyze" cycle often required months of laboratory work, as each new candidate demanded extensive experimental iterations with high costs and frequent failures due to unforeseen toxicity or poor performance [59]. However, the integration of artificial intelligence (AI) with advanced experimental platforms is now dramatically accelerating this pipeline. AI is transforming materials science by accelerating the design, synthesis, and characterization of novel materials, enabling rapid property prediction and inverse design [60]. This technical support center provides targeted guidance for researchers leveraging these advanced tools to overcome kinetic barriers and achieve unprecedented speed in materials development.
Quantifying the Acceleration: Data-Driven Insights
The integration of AI and automation is producing measurable, quantifiable reductions in development timelines across multiple stages of materials and drug discovery. The table below summarizes documented accelerations.
Table 1: Documented Timeline Reductions in AI-Driven Discovery
| Discovery Phase | Traditional Timeline | AI-Accelerated Timeline | Acceleration Factor | Key Enabling Technology |
|---|---|---|---|---|
| Early Drug Discovery (Target ID to Lead Optimization) [59] | 18-24 months | ~3 months | ~6-8x | Generative AI, Predictive Modeling |
| Lead Generation & Virtual Screening [61] | Not Specified | 28% reduction in timeline | >1.25x | Machine Learning Platforms |
| Substrate Scope Screening [62] | 1-2 years | 3-4 weeks | ~12-17x | High-Throughput Experimentation (HTE) |
| General AI-Driven Discovery [63] | Several months | A few weeks | ~4x | AI Coding Tools (e.g., Claude, Cursor) |
| Chemical Synthesis & Optimization [44] | Iterative manual cycles | End-to-end autonomous development | Significant | LLM-based Reaction Framework (LLM-RDF) |
These accelerations are driven by core technological shifts. Machine learning-based force fields now offer the accuracy of ab initio methods at a fraction of the computational cost, while generative models can propose new materials and synthesis routes intelligently [60]. In one notable case, the development of a cloud-agnostic software development kit (SDK) was accelerated from months to weeks using AI-assisted coding tools, demonstrating the pervasive effect of AI on research and development infrastructure [63].
To successfully implement these accelerated workflows, researchers require a set of core tools and reagents. The following table details key components of the modern materials discovery pipeline.
Table 2: Key Research Reagent Solutions for Accelerated Discovery
| Tool / Reagent | Function in Accelerated Discovery | Specific Role in Overcoming Bottlenecks |
|---|---|---|
| Graph Neural Networks (GNNs) [64] | Predicts crystal structure stability and energy. | Enumerates stable materials computationally, bypassing costly trial-and-error; improves hit rate for stable crystals from <6% to >80%. |
| Large Language Model (LLM) Agents [44] | Autonomous end-to-end synthesis planning and execution. | Replaces manual literature review and experimental design; integrates tasks (literature scouting, experiment design, analysis) into a single automated workflow. |
| Flow Chemistry Reactors [62] | Enables high-throughput experimentation (HTE) under controlled conditions. | Allows safe use of hazardous reagents, provides superior heat/mass transfer, and enables access to wider process windows (e.g., high temp/pressure) to accelerate reaction rates. |
| Generative AI Models [61] | Designs novel molecular structures with tailored properties. | Rapidly generates vast libraries of candidate molecules optimized for specific criteria (e.g., solubility, potency), compressing the initial design phase. |
| Autonomous Robotic Platforms [60] [44] | Executes synthesis and testing physically without human intervention. | Closes the "make-test" loop, enabling 24/7 experimentation and rapid, unbiased data acquisition for kinetic modeling and optimization. |
| Machine-Learning Force Fields [60] | Provides accurate energy calculations for molecular dynamics simulations. | Allows large-scale, high-fidelity simulation of material behavior and properties (e.g., ionic conductivity) at a fraction of the computational cost of traditional methods. |
Experimental Protocols & Workflows
Protocol: LLM-Driven End-to-End Synthesis Development
This protocol outlines the methodology for using a framework like LLM-RDF (LLM-based Reaction Development Framework) for autonomous synthesis development [44].
- Task Definition: Input the target transformation or compound to the centralized web application using natural language (e.g., "Develop a synthetic method to oxidize alcohols to aldehydes using air").
- Literature Review & Information Extraction: The Literature Scouter agent automatically queries academic databases (e.g., Semantic Scholar) to identify relevant methodologies and extract detailed experimental procedures, reagents, and catalysts.
- Experimental Design: The Experiment Designer agent formulates a hypothesis and designs an experimental plan, including substrate scope screening and condition optimization.
- Automated Execution: The Hardware Executor agent translates the experimental plan into machine-readable instructions for automated high-throughput experimentation (HTE) platforms.
- Real-Time Analysis: The Spectrum Analyzer and Result Interpreter agents process analytical data (e.g., from GC-MS) in real-time to evaluate reaction outcomes, such as conversion and yield.
- Iterative Optimization & Scale-Up: Based on results, the framework iteratively refines conditions. The Separation Instructor can then guide subsequent steps for purification and scale-up, demonstrating the end-to-end capability.
Protocol: High-Throughput Screening with Flow Chemistry
This protocol is adapted for screening photochemical reactions, a common area where sluggish kinetics are a challenge [62].
- Reactor Setup: Employ a continuous-flow photochemical reactor (e.g., Vapourtec UV150) with narrow tubing for efficient light penetration and mass/heat transfer.
- Parameter Definition: Use the LLM agent or human researcher to define a broad screening space, including photocatalysts, bases, and reagents. Continuous variables like residence time and temperature can be dynamically altered.
- Automated Screening: The flow system continuously processes reaction mixtures under different conditions, collecting samples for analysis.
- In-line Analysis: Integrate Process Analytical Technology (PAT), such as in-line IR or UV spectroscopy, for real-time reaction monitoring.
- Data-Driven Optimization: Feed results into a Design of Experiments (DoE) model or a closed-loop optimization algorithm to identify the optimal combination of parameters for overcoming kinetic limitations and maximizing throughput.
Technical Support: FAQs and Troubleshooting
Q1: Our AI model for predicting reaction yields performs well on training data but generalizes poorly to new substrate classes. What steps can we take?
- A1: This is often a data quality and model robustness issue.
- Increase Data Diversity: Actively seek out or generate data for underrepresented chemical spaces. Implement an active learning cycle where the model's uncertain predictions on new substrates are validated by experiment and added to the training set [64]. The GNoME project demonstrated that model performance improves as a power law with the amount of diverse data.
- Leverage Explainable AI (XAI): Use XAI tools to interpret your model's predictions and identify any spurious correlations or lack of physical interpretability it may be relying on [60]. This can guide a more targeted data collection strategy.
- Ensemble Models: Use an ensemble of models (deep ensembles) rather than a single model. This provides uncertainty quantification and can improve generalization and robustness on out-of-distribution examples [64].
Q2: We are facing bottlenecks in translating high-throughput screening (HTS) results from microliter plates to gram-scale synthesis. How can this be resolved?
- A2: This is a common scale-up challenge.
- Adopt Flow Chemistry: Transition from batch-wise HTS in plates to a flow chemistry approach. Parameters optimized in flow are directly scalable by increasing runtime, as the enhanced heat and mass transfer characteristics are maintained from small to large scale [62]. This minimizes re-optimization.
- Use Scale-Up Rules Early: Consider scale-up constraints (e.g., heat removal, mixing efficiency) during the initial screening phase by using scale-up rules or models to filter out conditions that are unlikely to work at larger scales.
- Implement PAT: Integrate in-line/on-line analytics (e.g., ReactIR, GC) in your flow setup to closely monitor the reaction as you scale, allowing for rapid detection and correction of issues [62].
Q3: Our automated platform generates large volumes of failed experimental data. How can this data be useful?
- A3: So-called "negative data" is extremely valuable for improving AI models.
- Create Structured Repositories: Log all experimental outcomes—both positive and negative—in standardized, annotated data formats. Include all relevant parameters (reactant structures, concentrations, temperature, time, etc.) and the measured outcomes [60].
- Train Robust Models: Use this comprehensive dataset to train machine learning models to recognize not only what leads to success but also what leads to failure. This significantly improves the model's predictive accuracy and its ability to avoid unproductive regions of chemical space.
- Community Sharing: Advocate for and participate in open-access datasets that include negative data. This allows the entire research community to benefit and avoids redundant repetition of failed experiments [60].
Q4: How can we ensure consistent and reproducible behavior when our AI agents interact with different physical hardware or software environments?
- A4: This is a critical challenge for reliable autonomous experimentation.
- Adopt a Layered Architecture: Design your system with a abstraction layer, similar to the cloud-agnostic SDK (MultiCloudJ). This layer provides a stable, portable API contract that normalizes behavior across different provider implementations (e.g., different robotic arms or analytical instruments) [63].
- Implement Rigorous Conformance Testing: Develop a suite of tests that validate the consistent behavior of your system across all hardware/software environments. Using tools like WireMock to record and replay interactions can ensure deterministic behavior in continuous integration (CI) pipelines, even without physical hardware access [63].
Workflow Visualization: AI-Driven Materials Discovery
The following diagram illustrates the integrated human-AI workflow that enables the dramatic acceleration of materials discovery, from initial computational screening to final experimental validation.
Autonomous synthesis represents a transformative advancement in materials science and chemistry, leveraging artificial intelligence, robotics, and closed-loop experimentation to accelerate discovery. The benchmark performance of these systems was demonstrated by the A-Lab, which achieved a 71% success rate in synthesizing 41 of 58 novel inorganic target compounds over 17 days of continuous operation [40]. This achievement highlights the significant potential of autonomous laboratories while also revealing opportunities for improvement. Critical analysis of failed syntheses suggests that with optimized decision-making algorithms and enhanced computational techniques, this success rate could potentially be increased to 78% [40].
The challenge of sluggish reaction kinetics presents a substantial barrier to achieving these higher success rates, particularly in solid-state synthesis of inorganic powders where diffusion limitations and kinetic barriers can dominate reaction outcomes. This technical support center provides targeted guidance for researchers seeking to overcome these challenges through improved experimental protocols, better precursor selection, and enhanced computational approaches.
Core Performance Metrics & Failure Analysis
Understanding the quantitative performance of autonomous synthesis systems and the specific reasons for synthetic failures is essential for designing effective improvement strategies. The following table summarizes the key experimental outcomes and failure modes observed in the A-Lab study:
| Performance Metric | Value | Context & Implications |
|---|---|---|
| Overall Success Rate | 71% (41/58 compounds) | Demonstrated effectiveness of AI-driven platforms for autonomous materials discovery [40] |
| Potential Improved Rate | Up to 78% | Achievable with minor modifications to decision-making and computational techniques [40] |
| Literature-Inspired Recipe Success | 35 compounds | ML models trained on historical literature data effectively proposed initial synthesis routes [40] |
| Active Learning Optimizations | 9 targets | ARROWS³ algorithm improved yields for targets where initial recipes failed [40] |
| Primary Failure Modes | Slow kinetics, precursor volatility, amorphization, computational inaccuracies | Identified barriers requiring specific mitigation strategies [40] |
Analysis of the 17 unsuccessful syntheses revealed critical failure modes that must be addressed to improve success rates:
- Slow Reaction Kinetics: Particularly problematic in solid-state synthesis where diffusion limitations impede target formation [40]
- Precursor Volatility: Loss of key reactants during heating stages disrupts stoichiometric balances [40]
- Amorphization: Failure to develop crystalline structures detectable by characterization methods [40]
- Computational Inaccuracies: Errors in predicted phase stability or reaction pathways [40]
Autonomous Synthesis Workflow & Architecture
The following diagram illustrates the integrated workflow of a typical autonomous synthesis laboratory, showing how computational planning, robotic execution, and analytical feedback create a closed-loop optimization system:
Autonomous Synthesis Closed-Loop Workflow: This integrated system combines computational planning with robotic execution and analytical feedback to optimize synthesis outcomes iteratively [40].
Frequently Asked Questions: Troubleshooting Synthesis Failures
How can I improve synthesis outcomes for targets with slow reaction kinetics?
Slow reaction kinetics represents one of the most common challenges in solid-state synthesis. Implement the following strategies:
- Increase Reactivity Through Milling: Extend milling time or intensity to reduce particle size and improve interfacial contact between precursors [40]
- Optimize Thermal Profiles: Implement multi-stage heating protocols with intermediate holds to allow nucleation before crystal growth [40]
- Apply Bayesian Optimization: Use algorithms like those in the Rainbow system to efficiently explore temperature-time parameter spaces and identify conditions that overcome kinetic barriers [58]
- Incorporate Mediator Phases: Introduce interfacial mediators that facilitate solid-state ion transport, similar to strategies used in lithium-sulfur battery systems [65]
What approaches address precursor selection challenges?
Precursor selection critically influences reaction pathways and potential kinetic traps:
- Leverage Natural Language Processing: Utilize ML models trained on literature data to assess target similarity and identify proven precursor combinations for analogous materials [40]
- Apply Thermodynamic Screening: Calculate decomposition energies for potential precursor combinations using databases like the Materials Project to avoid intermediates with small driving forces to form targets [40]
- Implement Pairwise Reaction Analysis: Build a database of observed pairwise reactions to predict and avoid pathways that form persistent intermediate phases [40]
- Address Volatility Issues: For precursors with volatility concerns, consider sealed reaction vessels or alternative precursor compounds with higher decomposition temperatures
How can I enhance computational predictions to improve synthesis planning?
Computational inaccuracies contribute significantly to synthesis failures:
- Incorporate Experimental Validation: Refine computational models using experimental data from both successful and failed syntheses to improve predictive accuracy [40]
- Utilize Multi-Fidelity Modeling: Combine high-quality experimental data with lower-fidelity computational predictions to expand the effective training dataset [66]
- Implement Active Learning: Use systems like ARROWS³ that integrate ab initio computed reaction energies with observed synthesis outcomes to predict improved solid-state reaction pathways [40]
- Account for Kinetic Factors: Supplement thermodynamic predictions with kinetic considerations, as materials with similar decomposition energies can exhibit vastly different synthetic accessibility [40]
What strategies improve optimization efficiency in autonomous systems?
Optimizing the exploration-exploitation balance is crucial for efficient materials discovery:
- Implement Multi-Objective Optimization: Use Pareto-front optimization approaches like those in the Rainbow system to simultaneously maximize multiple target properties (e.g., PLQY and emission linewidth for perovskites) [58]
- Balance Exploration and Exploitation: Deploy acquisition functions that systematically balance between searching unexplored regions (exploration) and refining promising conditions (exploitation) [66]
- Transfer Learning Between Campaigns: Leverage knowledge gained from previous optimization campaigns to inform initial conditions for new target materials [58]
- Utilize Multi-Agent Systems: Implement specialized agents for planning, execution, and analysis that collaborate through a coordinated framework [67]
Experimental Protocols for Kinetic Optimization
Protocol: Active Learning for Reaction Pathway Optimization
This protocol implements the ARROWS³ approach for optimizing synthesis routes through active learning:
Initialization Phase:
Iterative Optimization Loop:
- Execute proposed synthesis recipes using robotic handling systems [40]
- Characterize products using XRD with automated Rietveld refinement for phase quantification [40]
- Build database of observed pairwise reactions between precursors and intermediates [40]
- Calculate driving forces to form target from observed intermediates using formation energies from materials databases [40]
- Prioritize synthesis routes that avoid intermediates with small driving forces (<10 meV per atom) to form target [40]
- Continue iteration until target yield exceeds 50% or all candidate recipes are exhausted
Knowledge Capture:
- Document successful and failed pathways in searchable database
- Update ML models with new experimental outcomes
- Identify generalizable rules for precursor selection and thermal profiles
Protocol: Multi-Robot Perovskite Nanocrystal Optimization
The Rainbow system provides a specialized protocol for optimizing metal halide perovskite nanocrystals:
System Configuration:
- Deploy liquid handling robot for precursor preparation and multi-step synthesis [58]
- Integrate characterization robot for UV-Vis absorption and emission spectra acquisition [58]
- Implement robotic plate feeder for labware replenishment [58]
- Coordinate systems using robotic arm for sample and labware transfer [58]
Closed-Loop Optimization:
- Define multi-objective target function combining PLQY, FWHM, and target emission energy [58]
- Explore mixed-variable parameter spaces including ligand structures and precursor conditions [58]
- Execute parallelized experiments using miniaturized batch reactors [58]
- Characterize optical properties in real-time with spectroscopic feedback [58]
- Update Bayesian optimization model with experimental outcomes [58]
- Select subsequent experiments balancing exploration and exploitation [58]
Knowledge Extraction:
The Scientist's Toolkit: Essential Research Reagents & Materials
The following table details key reagents, materials, and computational resources essential for implementing successful autonomous synthesis campaigns:
| Resource Category | Specific Examples | Function & Application |
|---|---|---|
| Computational Databases | Materials Project, Google DeepMind phase-stability data [40] | Provide ab initio phase-stability calculations and formation energies for target identification and reaction planning |
| Literature Knowledge Bases | Text-mined synthesis databases [40] | Enable ML models to propose initial synthesis recipes based on historical analogies |
| Precursor Materials | Metal oxides, phosphates, halide salts [40] | Serve as starting materials for solid-state synthesis of inorganic powders |
| Ligand Systems | Organic acids with varying alkyl chain lengths [58] | Control growth, stabilization, and optical properties of perovskite nanocrystals |
| Characterization Tools | X-ray diffraction (XRD), UV-Vis spectroscopy, photoluminescence measurement [40] [58] | Provide real-time feedback on synthesis outcomes and material properties |
| Optimization Algorithms | Bayesian optimization, ARROWS³, Pareto-front identification [40] [58] | Enable efficient navigation of high-dimensional parameter spaces |
| Robotic Platforms | Liquid handlers, robotic arms, automated furnaces [40] [58] | Execute reproducible synthesis and characterization protocols without human intervention |
Kinetic Mediation Strategies for Enhanced Reactivity
The following diagram illustrates strategic approaches to overcoming sluggish reaction kinetics through interfacial mediation and pathway engineering:
Kinetic Mediation Strategy Framework: This diagram outlines the relationship between common kinetic limitations and targeted intervention strategies to improve synthesis success rates [40] [65].
The autonomous synthesis of complex systems, such as novel materials or drug formulations, represents a frontier in scientific research. A significant bottleneck in this process is overcoming sluggish reaction kinetics, which can prevent the successful formation of target compounds even when they are thermodynamically stable. The Helmsman framework offers a novel approach to this challenge by employing multi-agent collaboration to automate the design, implementation, and validation of complex synthesis pathways. Inspired by autonomous materials discovery platforms like the A-Lab, which identified slow kinetics as a primary failure mode in 11 out of 17 unsuccessful synthesis attempts [1], Helmsman introduces a structured, closed-loop validation system. This technical support center provides targeted troubleshooting guidance for researchers deploying such autonomous systems in drug development and materials science.
Frequently Asked Questions (FAQs) and Troubleshooting
Q1: Our autonomous synthesis runs are failing to produce the target compound, and the system log indicates "low driving force" in several reaction steps. What is the likely cause and recommended action?
A: This error typically indicates that the synthesis is hindered by sluggish reaction kinetics. This was the most common failure mode in the A-Lab, affecting 65% of unobtained targets [1].
- Diagnosis: Confirm that the intermediate phases in your synthesis pathway have a sufficient driving force (recommended >50 meV per atom) to form the next desired compound. Steps with a driving force below this threshold often have slow reaction rates.
- Solution: Helmsman's active learning cycle, specifically its ARROWS3 algorithm, is designed to address this. It will automatically:
- Consult its database of observed pairwise reactions to avoid known low-driving-force intermediates.
- Propose alternative precursor sets or reaction pathways that prioritize intermediates with a larger thermodynamic driving force, thereby accelerating the kinetics [1].
Q2: During the autonomous evaluation phase, the simulation fails in the first few rounds. What are the first things I should check?
A: A first-round failure often points to a fundamental flaw in the generated code, which Helmsman's Evaluator Agent is designed to catch. Follow this diagnostic workflow:
- Step 1: Check for Runtime Integrity (Level 1 Verification). The log will flag explicit errors like Python exceptions, missing modules, or failed client participation. The Debugger Agent will typically auto-correct these, such as fixing API misuse in the Flower framework [67] [68].
- Step 2: Verify Semantic Correctness (Level 2 Verification). If the code runs but produces illogical results, the system checks for stagnant accuracy, divergent training losses, or zero aggregation results. This often uncovers flaws in the core FL algorithm, such as incorrect aggregation logic [68].
- Step 3: Consult the Report. The system generates a structured error report after each evaluation cycle. This report is the primary input for the Debugger Agent and provides the most direct insight into the failure's root cause [68].
Q3: The multi-agent system has generated a research plan that seems suboptimal for my specific drug discovery problem. Can I intervene?
A: Yes. Helmsman incorporates a critical human-in-the-loop (HITL) planning phase for this exact reason.
- Process: After the Planning Agent drafts a research plan and a Reflection Agent critiques it, the refined plan is presented to you for approval.
- Action: You can reject the plan and provide specific feedback, such as guiding the system towards strategies known to work well with proteomics data or away from methods unsuitable for your specific data heterogeneity. This feedback is used to regenerate a more suitable plan, ensuring alignment with your expert knowledge and intent [67] [68].
Q4: How does the framework ensure that the final synthesized FL code is robust and not just syntactically correct?
A: Robustness is ensured through the closed-loop Autonomous Evaluation and Refinement phase.
- The generated code is not just compiled; it is executed in a sandboxed simulation environment (e.g., using the Flower framework) for multiple rounds of federated learning.
- The system performs hierarchical verification, checking both runtime integrity and semantic correctness.
- Any failure triggers an automatic debugging cycle where a Debugger Agent analyzes the error and generates a patch. This loop continues until the system passes all checks or a pre-set iteration limit is reached, guaranteeing a functionally robust output [68].
Experimental Protocols for Validating Synthesis Pathways
To systematically address sluggish kinetics, the following experimental protocols, derived from the operational principles of the A-Lab and Helmsman, should be implemented.
Protocol 1: Active Learning for Kinetic Optimization
This protocol uses autonomous analysis to identify and avoid kinetic traps.
- Initial Recipe Generation: Propose up to five initial synthesis recipes using natural-language models trained on historical literature data to assess target similarity [1].
- Execution and Characterization: Perform the synthesis using automated robotics and characterize the products via X-ray diffraction (XRD) or other relevant analytical techniques [1].
- Phase and Yield Analysis: Use probabilistic machine learning models to extract phase and weight fractions of the synthesis products from the characterization data [1].
- Pathway Optimization: If the target yield is below a threshold (e.g., 50%), invoke an active learning algorithm (e.g., ARROWS3). This algorithm uses a database of observed pairwise reactions to avoid low-driving-force intermediates and proposes alternative synthesis routes with more favorable kinetics [1].
- Iteration: Repeat steps 2-4 until the target is obtained as the majority phase or all viable synthesis recipes are exhausted.
Protocol 2: Multi-Agent Code Synthesis and Validation
This protocol details the workflow for generating and validating the FL code that controls the autonomous synthesis process, as exemplified by Helmsman.
Autonomous FL System Synthesis Workflow
Interactive Planning:
- Input: A high-level user query is provided using a structured template detailing the application domain, data characteristics, and FL objectives [68].
- Agentic Plan Generation: A Planning Agent, equipped with web search and access to a curated literature database, drafts an initial research plan [67].
- Self-Reflection and Human Approval: A Reflection Agent critiques the plan for coherence and feasibility. The refined plan is then presented to the user for explicit approval, ensuring alignment with research goals [68].
Modular Code Generation:
- A Supervisor Agent decomposes the approved plan into a modular blueprint (e.g., Task, Client, Strategy, Server modules) [68].
- Specialized agent teams, each with a Coder and a Tester, implement and verify the respective modules.
- The Supervisor enforces a dependency-aware integration order to build the complete codebase [67] [68].
Autonomous Evaluation and Refinement:
- The integrated code is executed in a sandboxed simulation environment (e.g., Flower framework) [68].
- An Evaluator Agent performs a two-level check:
- Level 1 (Runtime Integrity): Scans for crashes, exceptions, or failed client connections.
- Level 2 (Semantic Correctness): Analyzes simulation logs for logical errors like stagnant metrics or divergence [68].
- If a failure is detected, a Debugger Agent generates a patch based on the error report. The cycle repeats until the system passes verification or a maximum iteration limit is reached [68].
Key Experimental and Diagnostic Data
The following tables consolidate quantitative data and key reagents relevant to diagnosing and overcoming synthesis challenges in autonomous systems.
Table 1: Analysis of Synthesis Failures in an Autonomous Laboratory
This table summarizes data from a large-scale autonomous synthesis campaign, highlighting the primary barriers to success.
| Failure Mode | Number of Affected Targets | Key Characteristic | Potential Solution |
|---|---|---|---|
| Sluggish Reaction Kinetics | 11 | Reaction steps with low driving force (<50 meV per atom) [1] | Active learning to bypass low-driving-force intermediates [1] |
| Precursor Volatility | 3 | Loss of precursor material during heating [1] | Modify precursor selection or use sealed containers |
| Amorphization | 2 | Product fails to crystallize [1] | Adjust cooling rates or annealing steps |
| Computational Inaccuracy | 1 | Error in ab initio phase-stability data [1] | Use updated computational data or hybrid models |
Table 2: Hierarchical Verification in Autonomous Evaluation
This table outlines the checks performed by Helmsman's Evaluator Agent to ensure the synthesized FL system is functionally correct.
| Verification Level | Check Type | Specific Checks Performed |
|---|---|---|
| Level 1 | Runtime Integrity | Python exceptions, failed imports, client dropout, GPU/OOM errors [68] |
| Level 2 | Semantic Correctness | Stagnant accuracy/loss, client model divergence, zero aggregated model updates [68] |
The Scientist's Toolkit: Research Reagent Solutions
This section details essential components for building and validating autonomous synthesis systems.
Table 3: Essential Components for Autonomous Synthesis Research
| Item | Function in the Experiment |
|---|---|
| Sandboxed Simulation Environment (e.g., Flower) | Provides a safe, isolated platform for executing and testing the generated federated learning code without risk to physical hardware or real data [68]. |
| Curated Literature Database | A knowledge base of prior synthesis recipes and FL strategies, used by the Planning Agent to ground its proposals in established research and best practices [67] [1]. |
| Active Learning Algorithm (e.g., ARROWS3) | The core logic that optimizes synthesis pathways by leveraging observed reaction data and thermodynamic calculations to overcome kinetic barriers [1]. |
| Robotic Stations for Sample Handling | Integrated automation for dispensing, mixing, heating, and characterizing powder samples, enabling continuous and reproducible 24/7 experimentation [1]. |
Frequently Asked Questions
What are the most common causes of failed experiments in autonomous synthesis? Research indicates that sluggish reaction kinetics is the predominant failure mode, affecting approximately 65% of unsuccessful synthesis targets [1]. These are reactions with low driving forces (typically below 50 meV per atom), which proceed too slowly to form the target material within standard experimental timeframes. Other common causes include precursor volatility (unexpected evaporation or degradation of starting materials), amorphization (formation of non-crystalline products that complicate analysis), and computational inaccuracies where simulation-based predictions don't align with experimental behavior [1].
How does active learning reduce experimental failures? Active learning systems continuously refine synthesis strategies based on experimental outcomes [1]. When initial recipes fail, these systems propose improved follow-up recipes by avoiding intermediate phases with small driving forces and prioritizing reaction pathways with larger thermodynamic driving forces. This approach successfully identified improved synthesis routes for multiple targets that had zero yield from initial literature-inspired recipes [1].
What is the limitation of traditional One-Factor-at-a-Time (OFAT) experimentation? The OFAT approach varies one variable while holding others constant, which fails to capture interaction effects between factors and can lead to misleading results [69]. This method is inefficient in resource utilization, requires numerous experimental runs, and provides no systematic approach for optimization. Modern Design of Experiments (DOE) methodologies simultaneously vary multiple factors, enabling researchers to study interaction effects and identify optimal conditions with significantly fewer experiments [69].
How do self-driving laboratories improve experimental success rates? Autonomous laboratories integrate artificial intelligence with robotic platforms to execute closed-loop workflows comprising design, make, test, and analyze (DMTA) cycles [11]. These systems increase reproducibility by eliminating human error, maintain better records of both successful and failed experiments, and can handle hazardous materials with minimal human exposure. The precise experimental control and comprehensive data collection enable more systematic optimization and higher-quality data for machine learning models [11].
Troubleshooting Guides
Issue: Slow Reaction Kinetics Delaying Material Formation
Problem Identification
- Symptoms: Low target yield despite extended reaction times; formation of intermediate phases that persist through multiple experimental iterations.
- Diagnostic Tools: Use XRD analysis to identify persistent intermediate phases. Calculate driving forces for remaining reaction steps using formation energies from computational databases [1].
Resolution Strategies
- Precursor Selection: Utilize active learning algorithms to identify alternative precursor sets that form intermediates with larger driving forces to the target material [1].
- Temperature Optimization: Implement Bayesian optimization to find optimal temperature profiles that accelerate kinetics without causing precursor decomposition [11].
- Pathway Engineering: Design synthesis routes that avoid intermediates with driving forces below 50 meV per atom, as these typically exhibit sluggish kinetics [1].
Prevention Measures
- During experimental planning, prioritize reaction pathways where all steps exceed 50 meV per atom driving force.
- Incorporate kinetic predictions alongside thermodynamic stability assessments when selecting target materials for synthesis campaigns.
Issue: Inconsistent Results Across Experimental Platforms
Problem Identification
- Symptoms: Successful synthesis in manual laboratories failing in automated platforms; variable yields between experimental batches.
- Root Causes: Differences in solid mixing efficiency; variations in heating and cooling profiles; material handling differences between manual and automated processes [11].
Standardization Protocols
- Powder Processing: Implement standardized milling procedures to ensure consistent particle sizes and reactivity across experiments [1].
- Hardware Calibration: Establish regular calibration schedules for temperature sensors, robotic dispensers, and characterization equipment.
- Data Documentation: Record comprehensive metadata including exact experimental conditions, precursor lot numbers, and environmental factors [11].
Validation Approach
- Run control experiments with known outcomes when transitioning between experimental platforms.
- Implement digital twins of physical processes to predict and compensate for system-specific variations.
Experimental Success Metrics and Economic Impact
Table 1: Autonomous Laboratory Performance Metrics
| Performance Indicator | Value | Measurement Context |
|---|---|---|
| Overall Success Rate | 71% (41/58 compounds) | 17-day continuous operation [1] |
| Literature-Inspired Recipe Success | 35 successful syntheses | Initial attempts based on historical data [1] |
| Active Learning Optimization Success | 6 additional syntheses | Targets with zero initial yield [1] |
| Potential Improved Success Rate | 74-78% | With algorithmic and computational improvements [1] |
| Experimental Duration | 17 days | Continuous operation for 58 targets [1] |
Table 2: Economic Impact of Reduced Experimental Failures
| Factor | Traditional Approach | Autonomous Laboratory | Economic Impact |
|---|---|---|---|
| Human Labor Requirements | High (manual operation) | Reduced (automated workflows) | Freed for higher-level tasks [11] |
| Material Consumption | Variable and often high | Optimized and minimized | Reduced reagent costs [11] |
| Experimental Reproducibility | Subject to human error | High (robotic precision) | Reduced repeat experiments [11] |
| Data Quality | Inconsistent metadata | Comprehensive with full metadata | Better predictive models [11] |
| Failure Analysis | Incomplete records | Systematic documentation | Faster problem resolution [1] |
Experimental Protocols and Methodologies
Active Learning for Synthesis Optimization
Purpose: To autonomously improve synthesis recipes when initial attempts produce low target yields.
Procedure:
- Initialization: Start with literature-inspired recipes generated from natural language processing of historical synthesis data [1].
- Execution: Perform synthesis using robotic platforms with solid handling capabilities for powder mixing and heating [1].
- Characterization: Analyze products using XRD with phase identification through machine learning models trained on experimental structures [1].
- Database Building: Record all observed pairwise reactions between precursors and intermediates [1].
- Pathway Evaluation: Identify synthesis routes that avoid intermediates with small driving forces to the target material (<50 meV per atom) [1].
- Recipe Proposal: Use thermodynamic calculations to prioritize precursors and intermediates with larger driving forces for subsequent attempts [1].
- Iteration: Continue until target yield exceeds 50% or all available synthesis routes are exhausted [1].
Key Considerations:
- The algorithm leverages ab initio computed reaction energies from databases like the Materials Project [1].
- Maintain a continuously updated database of observed pairwise reactions to reduce redundant experimental testing [1].
- Focus on avoiding intermediate phases that consume the driving force early in the reaction pathway.
Genetic Algorithm Optimization for Reaction Mechanisms
Purpose: To determine optimal reaction rate coefficients in complex chemical systems where traditional methods fail.
Procedure:
- Problem Formulation: Define the objective function to minimize the difference between simulated and experimental data [70].
- Parameter Encoding: Represent reaction rate coefficients as individuals in the population using real-value encoding [70].
- Fitness Evaluation: Calculate fitness based on how well simulated results match experimental measurements [70].
- Selection: Apply tournament selection to choose parents for reproduction based on fitness [70].
- Crossover: Use simulated binary crossover (SBX) to create offspring by combining parent parameters [70].
- Mutation: Apply polynomial mutation to maintain population diversity [70].
- Termination Check: Continue until convergence criteria are met or maximum generations reached [70].
Multi-Objective Extension:
- For complex systems, implement multi-objective genetic algorithms that can simultaneously optimize for multiple experimental data types [70].
- Use non-dominated sorting to handle conflicting objectives in reaction mechanism optimization [70].
Research Reagent Solutions
Table 3: Essential Materials for Autonomous Synthesis Research
| Reagent/Material | Function | Application Notes |
|---|---|---|
| Oxide and Phosphate Precursors | Starting materials for inorganic powder synthesis | Wide variety of compositions; handle 33+ elements [1] |
| Alumina Crucibles | Sample containers for high-temperature reactions | Withstand repeated heating cycles; compatible with robotic handling [1] |
| Reference Standards | XRD calibration and phase identification | Certified materials for quantitative analysis [1] |
| Hydrogen/Methane/Kerosene Feeds | Fuel sources for combustion kinetics studies | Used in optimized reaction mechanisms [70] |
| Organic Semiconductor Compounds | Active materials for OSL development | Suzuki-Miyaura cross-coupling compatibility [11] |
Workflow Visualization
Autonomous Lab Workflow - This diagram illustrates the DMTA (Design-Make-Test-Analyze) cycle implemented in self-driving laboratories, showing how failed experiments feed back into the optimization process rather than representing complete failures.
Kinetics Optimization Strategies - This diagram shows the relationship between different optimization approaches for addressing sluggish reaction kinetics and their collective economic impact through reduced experimental failures.
Conclusion
The integration of AI-driven methodologies with robotic experimentation is fundamentally transforming our ability to overcome sluggish reaction kinetics in autonomous synthesis. Through foundational understanding of kinetic barriers, implementation of sophisticated optimization algorithms, practical troubleshooting frameworks, and rigorous validation, researchers can dramatically accelerate discovery timelines. The demonstrated success of platforms like A-Lab and AutoBot, achieving up to 78% synthesis success rates for novel compounds, provides a compelling roadmap for biomedical research. Future directions must focus on developing more generalized AI models that transfer across reaction types, creating standardized data formats for kinetics analysis, and establishing ethical frameworks for autonomous discovery. As these technologies mature, they promise to unlock unprecedented capabilities in drug development and materials science, potentially reducing discovery cycles from years to weeks while significantly lowering development costs.
References
- 1. An autonomous laboratory for the accelerated synthesis of ... [https://www.nature.com/articles/s41586-023-06734-w]
- 2. Molecular Drivers of Crystallization Kinetics for Drugs in ... [https://www.sciencedirect.com/science/article/pii/S0022354918307081]
- 3. Unexpected Slow Kinetics of Poly(Methacrylic Acid) Phase ... [https://www.mdpi.com/2073-4360/14/21/4708]
- 4. Facile synthesis of nanoporous Mg crystalline structure by ... [https://www.nature.com/articles/s41467-024-55018-y]
- 5. Overcoming slow removal efficiency-induced highly toxic I ... [https://www.sciencedirect.com/science/article/abs/pii/S0304389423013699]
- 6. Resolving Fast Relative Kinetics in Inorganic Solid-State ... [https://pubmed.ncbi.nlm.nih.gov/38019924/]
- 7. Why 90% of clinical drug development fails and how to ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9293739/]
- 8. ADDME – Avoiding Drug Development Mistakes Early [https://bmcneurol.biomedcentral.com/articles/10.1186/1471-2377-9-S1-S1]
- 9. learning from unsuccessful proof-of-concept trials [https://www.sciencedirect.com/science/article/abs/pii/S1359644608001487]
- 10. What Is Reaction Optimization? A Beginner's Guide for Chemists [http://autorxn.com/blog/what-is-reaction-optimization-a-beginners-guide-for-chemists/]
- 11. Challenges and Perspectives on Establishing a Self-Driving Lab [https://pmc.ncbi.nlm.nih.gov/articles/PMC9454899/]
- 12. Thermodynamic and kinetic reaction control [https://en.wikipedia.org/wiki/Thermodynamic_and_kinetic_reaction_control]
- 13. 14.3: Kinetic vs. Thermodynamic Control of Reactions [https://chem.libretexts.org/Courses/Athabasca_University/Chemistry_350%3A_Organic_Chemistry_I/14%3A_Conjugated_Compounds_and_Ultraviolet_Spectroscopy/14.03%3A_Kinetic_vs._Thermodynamic_Control_of_Reactions]
- 14. Slow Kinetics - an overview [https://www.sciencedirect.com/topics/engineering/slow-kinetics]
- 15. Mechanisms of kinetic trapping in self-assembly and phase ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3292593/]
- 16. Fully-automated Reaction Screening ... [https://www.bruker.com/en/news-and-events/webinars/2025/fully-automated-reaction-screening-reaction-optimization-and-on-the-fly-end-to-end-nmr-data-analysis.html]
- 17. Autonomous materials synthesis via hierarchical active ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8682983/]
- 18. Automated Synthesis Forum 2025 is underway - Day 1 in ... [https://www.reactwise.com/news/automated-synthesis-forum-2025-is-underway---day-1-in-london]
- 19. 18. Kinetics Problems – First Year General Chemistry [https://ecampusontario.pressbooks.pub/queenschem1/chapter/18-kinetics-problems/]
- 20. Autonomous closed-loop exploration of composition ... [https://www.nature.com/articles/s41524-025-01828-7]
- 21. Bayesian optimization - Martin Krasser's Blog [http://krasserm.github.io/2018/03/21/bayesian-optimization/]
- 22. Algorithm Breakdown: Bayesian Optimization [https://www.ritchievink.com/blog/2019/08/25/algorithm-breakdown-bayesian-optimization/]
- 23. Exploring Bayesian Optimization [https://distill.pub/2020/bayesian-optimization]
- 24. Bayesian optimisation for chemical problems - RSC Publishing [https://pubs.rsc.org/en/content/articlehtml/2024/dd/d3dd00234a]
- 25. High-throughput materials exploration system for the ... [https://www.nature.com/articles/s41524-025-01757-5]
- 26. On-the-fly closed-loop materials discovery via Bayesian ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7686338/]
- 27. Surface Current Measurement and Route Using... Optimization [https://www.holdentechnology.com/2024/12/10/surface-current-measurement-and-route-optimization-using-autonomous-boats/]
- 28. Comparison Analysis of Multimodal Fusion for Dangerous ... [https://www.mdpi.com/2079-9292/13/12/2294]
- 29. Effective Techniques for Multimodal Data Fusion [https://pmc.ncbi.nlm.nih.gov/articles/PMC10007548/]
- 30. Data fusion of spectroscopic data for enhancing machine ... [https://www.sciencedirect.com/science/article/pii/S2772508125000559]
- 31. 13.1 Spectroscopic methods for kinetic measurements [https://fiveable.me/chemical-kinetics/unit-13/spectroscopic-methods-kinetic-measurements/study-guide/OfIWLveEIkSXbmOd]
- 32. Imaging and Kinetics Spectroscopy Laboratory [https://chemistry.sciences.ncsu.edu/research/facilities-and-research-centers/imaks/]
- 33. A roadmap for large language models in chemical research [https://engineering.cmu.edu/news-events/news/2025/06/24-roadmap-for-llms.html]
- 34. Augmenting large language models with chemistry tools [https://www.nature.com/articles/s42256-024-00832-8]
- 35. Large Language Models Transform Organic Synthesis ... [https://arxiv.org/html/2508.05427v1]
- 36. SynAsk: unleashing the power of large language models in ... [https://pubs.rsc.org/en/content/articlehtml/2025/sc/d4sc04757e]
- 37. A review of large language models and autonomous agents in ... [https://pubs.rsc.org/en/content/articlehtml/2025/sc/d4sc03921a]
- 38. Accurate prediction of synthesizability and precursors of 3D ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12264133/]
- 39. 6.3: A Quick Review of Thermodynamics and Kinetics [https://chem.libretexts.org/Courses/Westminster_College/CHE_261_-_Organic_Chemistry_I/06%3A_Introduction_to_Reaction_Mechanisms/6.3%3A_A_Quick_Review_of_Thermodynamics_and_Kinetics]
- 40. An autonomous laboratory for the accelerated synthesis of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10700133/]
- 41. Observation of reaction intermediates and kinetic mistakes ... [https://pubs.rsc.org/en/content/articlelanding/2009/cc/b914750k]
- 42. A Guide to Synthetic Data Generation [https://www.orientsoftware.com/blog/synthetic-data-generation/]
- 43. Everything You Should Know About Synthetic Data in 2025 [https://insights.daffodilsw.com/blog/everything-you-should-know-about-synthetic-data-in-2025]
- 44. An automatic end-to-end chemical synthesis development ... [https://www.nature.com/articles/s41467-024-54457-x]
- 45. Advanced Guide to Training Data Collection in 2025 [https://sparkco.ai/blog/advanced-guide-to-training-data-collection-in-2025]
- 46. Importance of Temperature in Milling [https://hockmeyer.com/blog/articles/the-crucial-role-of-temperature-in-mixing-dispersion-and-milling-processes/]
- 47. Synthesizer common question and troubleshooting [https://www.biosearchtech.com/support/nac/synthesizer-common-question-and-troubleshooting]
- 48. Knowing When to Pivot, Persevere, or Stop [https://1cmo.com/knowing-when-to-pivot-persevere-or-stop/]
- 49. Pivot, Patch, or Persevere: Why Change Company Strategy [https://ubiminds.com/en-us/pivot-patch-or-persevere/]
- 50. Pivot or Persevere? How to Make Startup Decisions That ... [https://www.thinslices.com/insights/pivot-or-persevere-make-startup-decisions-that-drive-success]
- 51. Alleviating the sluggish kinetics of all-solid-state batteries ... [https://www.sciencedirect.com/science/article/abs/pii/S2095495624004157]
- 52. Top 5 Drug Discovery Trends 2025 Driving Breakthroughs [https://www.pelagobio.com/cetsa-drug-discovery-resources/blog/drug-discovery-trends-2025/]
- 53. Reaction Monitoring [https://magritek.com/applications/reaction-monitoring/]
- 54. Reaction Monitoring & Optimization [https://mestrelab.com/applications/reaction-monitoring]
- 55. Quantification of synthetic errors during chemical synthesis ... [https://www.nature.com/articles/s41598-022-16222-2]
- 56. Limiting Kinetic Energy through Control Barrier Functions [https://arxiv.org/html/2411.02186v1]
- 57. Optimized Materials in a Flash - Berkeley Lab News Center [https://newscenter.lbl.gov/2025/09/18/optimized-materials-in-a-flash/]
- 58. Autonomous multi-robot synthesis and optimization of ... [https://www.nature.com/articles/s41467-025-63209-4]
- 59. Artificial Intelligence (AI) in Drug Discovery Market Size ... [https://www.biospace.com/press-releases/artificial-intelligence-ai-in-drug-discovery-market-size-expected-to-reach-usd-16-52-billion-by-2034]
- 60. Advancing materials discovery through artificial intelligence [https://www.sciencedirect.com/science/article/pii/S2352940725003981]
- 61. AI-Powered Molecular Innovation: Breakthroughs and ... [https://www.mantellassociates.com/ai-powered-molecular-innovation-breakthroughs-and-2025-growth/]
- 62. Flow chemistry as a tool for high throughput experimentation [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d5dd00129c]
- 63. How AI Tools Accelerated Building Cloud-Agnostic SDK ... [https://engineering.salesforce.com/how-ai-tools-accelerated-building-and-adopting-cloud-agnostic-sdk-tasks-from-months-to-weeks/]
- 64. Scaling deep learning for materials discovery [https://www.nature.com/articles/s41586-023-06735-9]
- 65. Fast Reaction Kinetics via Interfacial Mediation in Quasi [https://pubmed.ncbi.nlm.nih.gov/41079674/]
- 66. Autonomous Experimentation and Self-Driving Labs for ... [https://www.nae.edu/340966/Autonomous-Experimentation-and-SelfDriving-Labs-for-Materials-Synthesis-Using-Deposition-Techniques]
- 67. Helmsman: Autonomous Synthesis of Federated Learning ... [https://arxiv.org/html/2510.14512v1]
- 68. Helmsman: Autonomous Synthesis of Federated Learning ... [https://chatpaper.com/paper/200310]
- 69. OFAT (One-Factor-at-a-Time). All You Need to Know [https://www.6sigma.us/six-sigma-in-focus/ofat-one-factor-at-a-time/]
- 70. Genetic algorithms for optimisation of chemical kinetics ... [https://www.sciencedirect.com/science/article/abs/pii/S0360128504000115]