Closed-Loop Autonomous Laboratories: Accelerating Novel Materials Discovery from AI to Reality
This article explores the transformative potential of closed-loop autonomous laboratories, or self-driving labs (SDLs), for researchers and professionals in materials science and drug development.
Closed-Loop Autonomous Laboratories: Accelerating Novel Materials Discovery from AI to Reality
Abstract
This article explores the transformative potential of closed-loop autonomous laboratories, or self-driving labs (SDLs), for researchers and professionals in materials science and drug development. It covers the foundational principles of SDLs, which integrate robotics, artificial intelligence, and advanced data analytics to automate the entire research cycle. The piece delves into the core methodology—the Design-Make-Test-Analyze (DMTA) loop—and showcases real-world applications, including the discovery of inorganic materials and organic molecules. It also addresses critical troubleshooting strategies for overcoming synthesis barriers and provides a comparative analysis of different SDL architectures and their validation through national initiatives. The conclusion synthesizes key takeaways and outlines the future impact of this technology on the pace and efficiency of biomedical and clinical research.
What Are Closed-Loop Autonomous Labs? The Foundation of Next-Gen Materials Discovery
The field of scientific research is undergoing a profound transformation, shifting from simple automation to full autonomy. This paradigm shift represents a fundamental change in the role of the researcher and the capabilities of the laboratory. While automation focuses on executing predefined, repetitive tasks without human intervention, full autonomy introduces systems capable of intelligent decision-making, adaptive learning, and self-directed experimentation. This evolution is particularly transformative within the context of closed-loop autonomous laboratories for novel materials research, where the integration of artificial intelligence (AI), robotics, and data science is creating a new generation of "self-driving labs" that can hypothesize, experiment, and discover at unprecedented speeds [1].
The core of this shift lies in the transition from tools that extend human physical capabilities to systems that augment and, in specific domains, replace human cognitive functions. Where automated systems follow predetermined protocols, autonomous systems generate and refine these protocols based on real-time experimental outcomes. This creates a continuous, closed-loop cycle of learning and discovery that operates at a scale and pace impossible for human researchers alone. The implications for materials science and drug development are staggering, promising to compress discovery timelines that traditionally span decades into years or even months [1] [2].
Deconstructing the Spectrum: From Automation to Autonomy
Understanding the continuum from automation to full autonomy is critical to appreciating the current paradigm shift. These terms are often used interchangeably but represent fundamentally different levels of capability and intelligence.
Defining the Terms
Automation involves using technology to perform predefined, repetitive tasks with high efficiency and precision. In a research context, this includes robotic liquid handlers, automated high-throughput screening systems, and programmable instrumentation. The key limitation is that automated systems lack decision-making capacity; they execute a human-designed protocol without deviation or interpretation [3]. For example, an automated testing platform can run surveys at high volumes but relies on humans to design the experiments and interpret the results [3].
Full Autonomy describes systems that can independently perform the complete research cycle: generating hypotheses, planning and executing experiments, analyzing results, and using those insights to determine subsequent actions. These systems operate within a defined goal but are not constrained to a fixed path, allowing them to explore complex, multi-dimensional problem spaces and discover novel solutions that might elude human intuition [4] [1]. The definition of autonomy itself is "the system's ability to select an intermediate goal and/or course of action for achieving that goal, as well as approve or disapprove any previous and future choices while achieving its overall goal" [5].
The Five-Layer Architecture of Self-Driving Labs
Fully autonomous research systems, or Self-Driving Labs (SDLs), are built upon an integrated architecture consisting of five distinct layers [1]:
- Actuation Layer: Robotic systems that perform physical tasks such as dispensing, heating, mixing, and synthesizing materials.
- Sensing Layer: Sensors and analytical instruments that capture real-time data on process and product properties.
- Control Layer: Software that orchestrates experimental sequences, ensuring synchronization, safety, and precision.
- Autonomy Layer: AI agents that plan experiments, interpret results, and update experimental strategies. This is the "cognitive" core of the system.
- Data Layer: Infrastructure for storing, managing, and sharing data, including metadata, uncertainty estimates, and provenance.
This architecture enables a system where, for instance, a materials SDL can autonomously explore composition-spread films to enhance properties like the anomalous Hall effect, making decisions about which elements to compositionally grade and which experimental conditions to explore next [4].
Visualizing the Autonomous Research Workflow
The following diagram illustrates the core closed-loop workflow that defines an autonomous research system, integrating the five architectural layers into a continuous cycle of learning and discovery.
Core Components of the Autonomous Research Laboratory
The implementation of full autonomy relies on the seamless integration of several advanced technological components. Each plays a distinct and critical role in the closed-loop system.
The Role of Artificial Intelligence and Machine Learning
AI and machine learning form the cognitive engine of autonomous laboratories. These systems are responsible for the higher-order decision-making that distinguishes autonomy from simple automation.
Bayesian Optimization: This is a powerful machine learning approach for optimizing expensive-to-evaluate functions. In materials research, it is used to efficiently navigate complex compositional spaces with minimal experiments. For instance, researchers have developed Bayesian optimization methods specifically for composition-spread films, enabling the selection of promising compositions and identifying which elements should be compositionally graded to maximize target properties like the anomalous Hall effect [4]. The algorithm balances exploration of unknown regions with exploitation of known promising areas.
Multi-Objective Optimization and Generative Models: Advanced AI frameworks can balance multiple, often competing objectives simultaneously (e.g., performance, cost, and safety). Generative AI models can also propose entirely novel molecular structures or material compositions that are predicted to possess desired properties, effectively acting as a co-inventor in the discovery process [1] [2].
Robotic Platforms and Automated Instrumentation
The physical layer of the autonomous laboratory consists of robotic platforms that translate digital decisions into physical experiments. These systems provide the precision, reproducibility, and high-throughput capability essential for autonomous operation. Key advancements include:
- Combinatorial Sputtering Systems: These allow for the fabrication of a large number of compounds with varying compositions on a single substrate in a single experiment. This high-throughput approach is critical for rapidly exploring material spaces [4].
- Laser Patterning and Multichannel Probes: These enable rapid, photoresist-free device fabrication and simultaneous measurement of multiple samples, drastically reducing the time between synthesis and characterization [4].
- Modular Robotic Chemistries: Systems that can be reconfigured for different synthesis and processing tasks, providing the flexibility needed for a general-purpose discovery platform [1].
Data Infrastructure and Provenance
The data layer is the foundational memory of the autonomous laboratory. It must capture not only the final results but the complete context of each experiment—the full digital provenance. This includes:
- All reagent identities, volumes, and lot numbers.
- Equipment settings, calibration records, and environmental conditions.
- The chain of decisions made by the AI and the rationale behind them [1]. This comprehensive data capture is essential for reproducibility, model retraining, and extracting maximum knowledge from every experiment.
Quantitative Frameworks for Measuring Autonomy
To move beyond qualitative descriptions, researchers have developed frameworks for quantifying autonomy. One such framework proposes a two-part measure distinguishing between the level of autonomy and the degree of autonomy [5].
Key Autonomy Metrics
This quantitative approach is based on metrics derived from robot task characteristics, recognizing that autonomy is purposive and domain-specific [5].
Table 1: Key Metrics for Quantifying Autonomy
| Metric | Description | Significance |
|---|---|---|
| Requisite Capability Set | The set of core capabilities (e.g., perception, planning, manipulation) required to complete a task without external intervention. | Determines the Level of Autonomy – what the system is capable of doing. |
| Reliability | The probability that a system will perform its required function under stated conditions for a specified period of time. | A measure of how trustworthy the system's capabilities are. |
| Responsiveness | The system's ability to complete tasks within a required timeframe, particularly in dynamic environments. | Measures performance quality and suitability for time-critical applications. |
The Level of Autonomy is a binary measure of whether a specific capability exists within the system, while the Degree of Autonomy is a continuous measure (from 0 to 1) of how well that capability performs, based on reliability and responsiveness [5]. This framework provides a more nuanced tool for assessing and comparing autonomous systems beyond the simpler, discrete-level charts used in some domains like automotive driving.
Case Study: Autonomous Discovery of Materials with Enhanced Anomalous Hall Effect
A landmark demonstration of full autonomy in materials research is the closed-loop exploration of composition-spread films for the anomalous Hall effect (AHE) [4]. This case study exemplifies the entire paradigm in action.
Experimental Objective and Setup
The goal was to optimize the composition of a five-element alloy system (Fe, Co, Ni, and two from Ta, W, or Ir) to maximize the anomalous Hall resistivity (({\rho}_{{yx}}^{A})), with a target of over 10 µΩ cm [4]. The autonomous system integrated combinatorial sputtering, laser patterning, and a multichannel measurement probe.
Table 2: Research Reagent Solutions for AHE Experiment
| Material/Reagent | Function/Description | Role in Experiment |
|---|---|---|
| Fe, Co, Ni (3d elements) | Room-temperature ferromagnetic elements | Form the base ferromagnetic matrix of the alloy system. |
| Ta, W, Ir (5d elements) | Heavy metals with strong spin-orbit coupling | Key additives to enhance the Anomalous Hall Effect by introducing spin-dependent scattering. |
| SiO2/Si Substrate | Thermally oxidized silicon wafer | Amorphous substrate for depositing thin films at room temperature, relevant for practical applications. |
| Custom Bayesian Optimization Algorithm | AI for selecting experimental conditions | The "brain" of the experiment, deciding which composition-spread films to fabricate and measure next. |
Detailed Autonomous Protocol and Workflow
The closed-loop operation followed a precise, iterative protocol with minimal human intervention:
- Initialization: A search space of 18,594 candidate compositions was defined and loaded into the system's "candidates.csv" file [4].
- AI-Driven Proposal: A custom Bayesian optimization algorithm (using the PHYSBO library) selected the most promising two elements to be compositionally graded and proposed L compositions with different mixing ratios [4].
- Automated Fabrication: The system automatically generated an input recipe file for the combinatorial sputtering system to deposit the composition-spread film (1-2 hours) [4].
- Sample Transfer (Human Role): A human transferred the sample from the sputtering system to the laser patterning system. This was one of the only manual steps [4].
- Device Fabrication: The laser patterning system automatically fabricated 13 devices on the film without photoresist (≈1.5 hours) [4].
- Sample Transfer (Human Role): A human transferred the patterned sample to the AHE measurement system [4].
- High-Throughput Characterization: A customized multichannel probe performed simultaneous AHE measurements on all 13 devices at room temperature (≈0.2 hours) [4].
- Automated Data Analysis: A Python program automatically analyzed the raw AHE data and calculated the anomalous Hall resistivity [4].
- Loop Closure: The results were fed back into the Bayesian optimization model, which updated its internal state and generated the next set of proposals, restarting the cycle at step 2 [4].
Outcome and Significance
Through this autonomous closed-loop exploration, the system discovered and validated a novel composition, Fe44.9Co27.9Ni12.1Ta3.3Ir11.7, which achieved a high anomalous Hall resistivity of 10.9 µΩ cm when deposited at room temperature on an SiO2/Si substrate [4]. This success was achieved with a dramatically accelerated experimental pace, demonstrating the power of full autonomy to not only execute tasks but to intelligently guide a research campaign to a successful outcome.
Implications and Future Outlook
The shift to full autonomy in research laboratories promises to fundamentally reshape the scientific enterprise. The implications are profound:
- Radical Acceleration of Discovery: SDLs can reduce time-to-solution by 100 to 1,000 times compared to the status quo, particularly for challenges in decarbonization, next-generation batteries, and sustainable polymers [1].
- Enhanced Reproducibility and Data Quality: The digital provenance and automated recording of every experimental parameter eliminate human error and variability, leading to more robust and reproducible results [1].
- Democratization of Advanced Research: Centralized "SDL Foundries" and distributed modular networks could provide researchers worldwide with access to state-of-the-art experimentation through a cloud-like interface, lowering barriers to entry [1].
- Evolution of the Researcher's Role: As autonomous systems handle routine discovery and optimization, human researchers will be freed to focus on higher-level tasks: asking profound questions, formulating complex problems, designing novel AI architectures, and interpreting the most surprising discoveries generated by the machines [2].
The vision of a "Material Intelligence" is emerging, where AI and robotics are so deeply integrated that they form a new, persistent substrate for discovery—a system that can "read" existing literature, "do" experiments, and "think" of new directions, potentially operating across the globe or even on distant planets [2]. This represents the ultimate expression of the paradigm shift from automation to full autonomy, heralding a new era in research and development.
The field of materials science is undergoing a profound transformation driven by the integration of artificial intelligence (AI), robotics, and robust data infrastructure. These core components form the foundation of closed-loop autonomous laboratories, which aim to bridge the critical gap between computational materials prediction and experimental realization [6]. The traditional approach to materials discovery, often characterized by slow, sequential, and human-intensive experimentation, struggles to keep pace with the vast design spaces identified by high-throughput computational screening. Autonomous laboratories represent a paradigm shift, leveraging intelligent automation to accelerate the synthesis and characterization of novel materials. This whitepaper details the core technical components and methodologies that underpin these self-driving labs, providing a framework for researchers in both materials science and drug development to understand and implement these advanced systems.
Core Architectural Components
The operational efficacy of an autonomous laboratory hinges on the seamless interaction of three core technological pillars: Artificial Intelligence for decision-making, robotics for physical execution, and a unified data infrastructure for knowledge integration.
Artificial Intelligence: The Cognitive Core
AI serves as the cognitive center of the autonomous laboratory, responsible for planning experiments, interpreting results, and guiding the research trajectory without human intervention. Key AI functionalities include:
Experimental Planning and Precursor Selection: Machine learning models, particularly those trained on vast historical datasets extracted from scientific literature using natural-language processing, can propose initial synthesis recipes by assessing target "similarity." This mimics the human approach of basing new experiments on analogies to known materials [6]. For example, the A-Lab utilized such models to generate initial synthesis recipes for novel inorganic powders, achieving a high success rate for targets deemed similar to previously documented compounds.
Active Learning and Bayesian Optimization: When initial recipes fail, active learning algorithms close the loop by proposing improved follow-up experiments. The ARROWS3 (Autonomous Reaction Route Optimization with Solid-State Synthesis) algorithm, used in the A-Lab, integrates ab initio computed reaction energies with observed experimental outcomes to predict optimal solid-state reaction pathways [6]. Similarly, specialized Bayesian optimization methods have been developed for high-throughput combinatorial experimentation. One implementation for composition-spread films uses a physics-based Bayesian optimization (PHYSBO) to select which elements to compositionally grade and identifies promising compositions to maximize a target property, such as the anomalous Hall effect [4].
Data Interpretation and Analysis: AI is critical for the rapid analysis of complex characterization data. In the A-Lab, probabilistic machine learning models were employed to extract phase and weight fractions of synthesis products from their X-ray diffraction (XRD) patterns. The identified phases were then confirmed with automated Rietveld refinement, allowing for near-real-time assessment of experimental success [6].
Robotics: The Physical Executor
Robotics translate AI-derived decisions into physical actions, handling tasks from sample preparation to characterization. This automation enables continuous, high-throughput operation and manages the physical challenges of handling solid powders, which can vary widely in density, flow behavior, and particle size [6].
- Integrated Robotic Stations: A fully autonomous lab, such as the A-Lab, typically integrates multiple robotic stations. These include a station for dispensing and mixing precursor powders, a second station with robotic arms to load crucibles into box furnaces for heating, and a third station for grinding synthesized samples into fine powders and preparing them for characterization like XRD [6].
- Combinatorial and High-Throughput Systems: Specialized robotic systems enable high-throughput experimentation. For instance, autonomous exploration of composition-spread films involves combinatorial sputtering for deposition, laser patterning for photoresist-free device fabrication, and customized multichannel probes for simultaneous property measurements [4]. This system allowed for the optimization of a five-element alloy for the anomalous Hall effect with minimal human intervention, requiring only sample transfer between systems.
Data Infrastructure: The Unifying Backbone
A unified data infrastructure is the central nervous system that connects AI and robotics, enabling the closed-loop functionality. It manages the vast streams of data generated and ensures that information flows seamlessly between computational and experimental components.
- Orchestration Software: Software platforms like NIMO (NIMS orchestration system) are crucial for supporting autonomous closed-loop exploration [4]. These systems orchestrate a series of programs that control the entire experimental cycle: predicting next experimental conditions from raw measurement data, generating input files for deposition systems, and analyzing results.
- Computational Databases and Knowledge Integration: Successful autonomous platforms leverage large-scale ab initio phase-stability databases, such as the Materials Project and data from Google DeepMind, to identify viable target materials [6]. The integration of this computational data with historical knowledge from text-mined literature and the lab's own growing database of observed pairwise reactions creates a powerful, self-improving knowledge base that informs subsequent experimental iterations.
Table 1: Core Components of an Autonomous Laboratory
| Component | Key Functions | Examples & Technologies |
|---|---|---|
| Artificial Intelligence (AI) | Experimental planning, data analysis, active learning optimization | Bayesian optimization (PHYSBO [4]), natural-language processing for precursor selection, probabilistic ML for XRD analysis [6] |
| Robotics & Automation | Sample synthesis, handling, transfer, and preparation | Robotic arms for furnace loading [6], combinatorial sputtering systems [4], automated grinding and characterization stations [6] |
| Data Infrastructure | Data orchestration, knowledge integration, closed-loop control | NIMO orchestration software [4], ab initio databases (Materials Project), literature-derived knowledge graphs [6] |
Experimental Protocols and Methodologies
This section provides detailed methodologies for key experiments that demonstrate the implementation of closed-loop autonomy in materials research.
Protocol 1: Closed-Loop Optimization of Composition-Spread Films
This protocol details the procedure for autonomous discovery of materials with enhanced functional properties, such as the anomalous Hall effect (AHE), using combinatorial thin-film deposition and Bayesian optimization [4].
1. Objective: To autonomously optimize the composition of a five-element alloy system (Fe, Co, Ni, and two from Ta, W, Ir) to maximize the anomalous Hall resistivity (({\rho }_{yx}^{A})).
2. Experimental Workflow:
- Step 1 - Candidate Definition: Define the search space of possible compositions. For example, set concentration ranges for Fe, Co, Ni (10-70 at.%) and the heavy metals (1-29 at.%), resulting in thousands of candidate compositions stored in a "candidates.csv" file.
- Step 2 - AI-Driven Proposal: The orchestration software (NIMO) runs a Bayesian optimization function ("nimo.selection" in "COMBI" mode). This algorithm selects two elements to be compositionally graded and proposes L compositions with different mixing ratios of these two elements at equal intervals, while fixing the others.
- Step 3 - Automated Synthesis: An input recipe file for the combinatorial sputtering system is automatically generated from the AI's proposal. The composition-spread film is deposited on a substrate (e.g., SiO2/Si) at room temperature.
- Step 4 - Automated Characterization & Measurement: The sample is transferred (manually or by robot) to a laser patterning system for photoresist-free device fabrication, and then to a customized multichannel probe for simultaneous AHE measurement of multiple devices at room temperature.
- Step 5 - Automated Data Analysis: A Python program automatically analyzes the raw AHE measurement data and calculates the anomalous Hall resistivity (({\rho }_{yx}^{A})).
- Step 6 - Closed-Loop Feedback: The results are fed back into the "candidates.csv" file, and the process repeats from Step 2. The AI algorithm uses the new data to update its model and propose the next most informative experiment.
3. Key Outcome: Using this protocol, researchers achieved a maximum anomalous Hall resistivity of 10.9 µΩ cm in a Fe44.9Co27.9Ni12.1Ta3.3Ir11.7 amorphous thin film, demonstrating the effectiveness of the closed-loop system for optimizing complex multi-element compositions [4].
Diagram 1: Closed-loop optimization for composition-spread films.
Protocol 2: Autonomous Synthesis of Novel Inorganic Powders
This protocol outlines the workflow used by the A-Lab for the solid-state synthesis of novel inorganic compounds, integrating diverse data sources and active learning [6].
1. Objective: To synthesize target inorganic powder materials identified from computational databases (e.g., Materials Project) as air-stable and on or near the thermodynamic convex hull.
2. Experimental Workflow:
- Step 1 - Target Identification: Select target materials predicted to be stable using large-scale ab initio phase-stability data. Filter for compounds that are not expected to react with O2, CO2, and H2O to ensure compatibility with open-air handling.
- Step 2 - Literature-Inspired Recipe Generation: Generate up to five initial synthesis recipes using a machine learning model that assesses target "similarity" through natural-language processing of a large database of literature syntheses. A second ML model proposes a synthesis temperature based on historical heating data.
- Step 3 - Robotic Synthesis Execution: A robotic arm dispenses and mixes precursor powders into an alumina crucible. Another robotic arm loads the crucible into a box furnace for heating.
- Step 4 - Robotic Characterization and Analysis: After cooling, a robot transfers the sample to a station where it is ground into a fine powder and measured by XRD. Probabilistic ML models analyze the XRD pattern to identify phases and estimate weight fractions, which are confirmed via automated Rietveld refinement.
- Step 5 - Active Learning Optimization: If the target yield is below a threshold (e.g., 50%), the active learning algorithm (ARROWS3) takes over. It uses the lab's growing database of observed pairwise reactions and computed reaction energies from the Materials Project to propose a new synthesis route with a higher probability of success, avoiding intermediates with low driving forces to form the target.
- Step 6 - Iteration: Steps 3-5 are repeated until the target is obtained as the majority phase or all possible recipes are exhausted.
3. Key Outcome: In a 17-day continuous run, the A-Lab successfully synthesized 41 out of 58 novel target compounds, a 71% success rate, demonstrating the power of integrating computation, historical knowledge, and robotics [6].
Diagram 2: Autonomous synthesis workflow for inorganic powders.
Quantitative Performance Data
The performance of autonomous laboratories is quantifiable through metrics such as success rates, acceleration factors, and optimization efficiency. The data below, derived from operational systems, underscores the transformative impact of this integrated approach.
Table 2: Quantitative Performance of Autonomous Experimentation Systems
| System / Platform | Key Performance Metric | Result / Outcome | Experimental Context |
|---|---|---|---|
| A-Lab [6] | Success Rate in Novel Material Synthesis | 71% (41/58 compounds synthesized) | 17-day continuous operation targeting novel oxides and phosphates. |
| A-Lab [6] | Potential Improved Success Rate | 78% (with improved computations) | Analysis of failure modes suggested achievable improvements. |
| Combinatorial AHE Optimization [4] | Optimized Property (Anomalous Hall Resistivity) | 10.9 µΩ cm | Achieved in a FeCoNiTaIr amorphous thin film via closed-loop Bayesian optimization. |
| Closed-Loop System [4] | Experiment Cycle Time | Synthesis: 1-2 hrs, Patterning: 1.5 hrs, Measurement: 0.2 hrs | Timeline for one cycle in the autonomous exploration of composition-spread films. |
| Data Center Robotics Market [7] | Projected Global Market Growth (CAGR 2024-2030) | 21.6% | Reflects broader adoption and investment in automated infrastructure. |
The Scientist's Toolkit: Essential Research Reagents and Materials
The implementation of the experimental protocols described relies on a suite of specific reagents, software, and hardware.
Table 3: Essential Research Reagents and Materials for Autonomous Materials Research
| Item Name | Type | Function / Application |
|---|---|---|
| Precursor Powders | Chemical Reagent | High-purity starting materials for solid-state synthesis of target inorganic compounds [6]. |
| Alumina Crucibles | Laboratory Consumable | Containment vessels for powder samples during high-temperature reactions in box furnaces [6]. |
| SiO2/Si Substrates | Substrate | Thermally oxidized silicon wafers used as substrates for the deposition of composition-spread thin films [4]. |
| NIMO (NIMS Orchestration System) | Software | Orchestration software for managing autonomous closed-loop exploration, including AI proposal generation and data analysis [4]. |
| PHYSBO | Software / Algorithm | Optimization tools for physics-based Bayesian optimization, used for selecting experimental conditions [4]. |
| Combinatorial Sputtering System | Hardware / Instrument | Deposition system for fabricating composition-spread films with graded elemental compositions [4]. |
| Automated XRD System | Hardware / Instrument | Integrated with robotic sample handling for high-throughput phase identification and analysis of synthesis products [6]. |
The field of materials science and chemistry is undergoing a profound transformation with the advent of Self-Driving Labs (SDLs). These autonomous systems represent the integration of automated experimental workflows in the physical world with algorithm-selected experimental parameters in the digital world [8]. The core value proposition of SDLs lies in their ability to navigate complex and exponentially expanding reaction spaces with an efficiency unachievable through human-led manual experimentation, thereby enabling researchers to explore larger and more complicated experimental systems [8]. This technological evolution mirrors similar advancements in other scientific domains, such as the Human-AI Collaborative Refinement Process used for categorizing surgical feedback, which demonstrates how artificial intelligence can enhance pattern discovery and prediction beyond human capabilities alone [9].
The classification of autonomy levels in SDLs is not merely an academic exercise but a critical framework for comparing systems, guiding development priorities, and understanding the operational requirements for different research applications. Just as performance metrics are essential for evaluating clinical decision support systems in healthcare [10], a standardized approach to classifying SDL autonomy provides researchers with the necessary tools to select appropriate systems for their specific experimental challenges. This classification system becomes increasingly important as SDLs evolve from simple automated tools toward partners in scientific discovery, capable of defining and pursuing novel research objectives without direct human intervention.
A Framework for Classifying SDL Autonomy Levels
Defining the Spectrum of Autonomy
The autonomy of self-driving labs can be systematically categorized into four distinct levels, each representing a different degree of human involvement and AI-driven decision-making. This classification is fundamental to understanding both the current capabilities and future trajectory of autonomous experimentation systems [8].
Piecewise Systems (Algorithm-Guided Studies) represent the foundational level of SDL autonomy. In these systems, a complete separation exists between the physical platform and the experimental selection algorithm. A human scientist must manually collect experimental data and transfer it to the algorithm, which then selects the next experimental conditions. These selected conditions must subsequently be transferred back to the physical platform by the researcher for testing [8]. This level of autonomy is particularly useful for informatics-based studies, high-cost experiments, and systems with low operational lifetimes, as human scientists can manually filter out erroneous conditions and correct system issues as they arise [8]. However, this approach is typically impractical for studies requiring dense data spaces, such as high-dimensional Bayesian optimization or reinforcement learning.
Semi-Closed-Loop Systems represent an intermediate stage where human intervention is still required for certain steps in the experimental process, but direct communication exists between the physical platform and the experiment-selection algorithm. Typically, researchers must either collect measurements after the experiment or reset aspects of the experimental system before studies can continue [8]. This approach is most applicable to batch or parallel processing of experimental conditions, studies requiring detailed offline measurement techniques, and highly complex systems that cannot conduct experiments continuously in series. Semi-closed-loop systems generally offer higher efficiency than piecewise strategies while still accommodating measurement techniques not amenable to inline integration, though they often remain ineffective for generating very large datasets [8].
Closed-Loop Systems represent a significant advancement in autonomy, requiring no human interference to carry out experiments. In these systems, the entirety of experimental conduction, system resetting, data collection and analysis, and experiment selection occurs without any human intervention or interfacing [8]. Although challenging to implement, closed-loop systems offer extremely high data generation rates and enable otherwise inaccessible data-greedy algorithms such as reinforcement learning and Bayesian optimization [8]. A prominent example is the A-Lab for solid-state synthesis of inorganic powders, which integrates robotics with computations, historical data, machine learning, and active learning to plan and interpret experiments autonomously [6].
Self-Motivated Experimental Systems represent the highest conceptual level of autonomy, where platforms define and pursue novel scientific objectives without user direction. These systems merge closed-loop capabilities with autonomous identification of novel synthetic goals, thereby completely removing human influence from the research direction-setting process [8]. While no platform has yet achieved this level of autonomy, it represents the theoretical endpoint for replacing human-guided scientific discovery with AI-driven research entities.
Quantitative Metrics for Comparing SDL Performance
Table 1: Key Performance Metrics for Self-Driving Labs
| Metric Category | Specific Measures | Description | Application Considerations |
|---|---|---|---|
| Degree of Autonomy | Piecewise, Semi-Closed Loop, Closed-Loop, Self-Motivated | Classification based on required human intervention level | Higher autonomy enables data-greedy algorithms but increases implementation complexity |
| Operational Lifetime | Demonstrated Unassisted/Assisted, Theoretical Unassisted/Assisted | Duration of continuous operation without human intervention | Critical for budgeting data, labor, and platform generation; reported values should specify chemical source limitations [8] |
| Throughput | Theoretical vs. Demonstrated Samples/Hour | Rate of experimental iteration and data generation | Highly dependent on reaction times and characterization methods; non-destructive characterization enables higher effective throughput [8] |
| Experimental Precision | Standard Deviation of Replicates | Reproducibility of experimental results under identical conditions | High precision is essential for effective optimization; imprecise data generation cannot be compensated for by high throughput alone [8] |
| Material Usage | Total Quantity, High-Value Materials, Hazardous Materials | Consumption of chemical resources per experiment | Lower volumes expand explorable parameter space and reduce costs; particularly important for expensive or environmentally harmful materials [8] |
Table 2: Autonomy Level Comparison with Implementation Requirements
| Autonomy Level | Human Role | Data Transfer Mechanism | Suitable Experiment Types | Limitations |
|---|---|---|---|---|
| Piecewise | Manually transfers data and conditions between platform and algorithm | Manual human intervention | Informatics studies, high-cost experiments, low-lifetime systems | Impractical for dense data spaces, limited scalability [8] |
| Semi-Closed-Loop | Interferes with specific steps (measurement collection or system resetting) | Direct platform-algorithm communication with human gaps | Batch processing, offline measurements, non-continuous systems | Limited very large dataset generation [8] |
| Closed-Loop | No intervention required during operation | Fully automated data and instruction transfer | Continuous experimentation, data-greedy algorithms (BO, RL) | Challenging to create, requires robust automation [8] |
| Self-Motivated | Defines overarching research goals | Fully autonomous goal-setting and experimentation | Novel scientific discovery without human direction | Theoretical stage, not yet demonstrated [8] |
Experimental Protocols for Autonomous Materials Research
The A-Lab Workflow for Novel Materials Synthesis
The A-Lab represents a state-of-the-art implementation of a highly autonomous materials research platform, specifically designed for the solid-state synthesis of inorganic powders. Its operational workflow provides a template for how autonomous systems can integrate various AI components and robotic systems to accelerate materials discovery [6].
The process begins with Target Identification and Validation. The A-Lab receives target materials predicted to be stable through large-scale ab initio phase-stability data from computational resources like the Materials Project and Google DeepMind. To ensure practical synthesizability, the system only considers targets predicted to be air-stable, meaning they will not react with O₂, CO₂, or H₂O during handling in open air [6]. This integration of computational screening with practical constraints demonstrates how autonomous systems can balance theoretical predictions with experimental realities.
The second stage involves AI-Driven Synthesis Planning. For each proposed compound, the A-Lab generates up to five initial synthesis recipes using a machine learning model that assesses target "similarity" through natural-language processing of a large database of syntheses extracted from the literature [6]. This approach mimics how human researchers base initial synthesis attempts on analogies to known related materials. A synthesis temperature is then proposed by a second ML model trained on heating data from the literature [6]. This dual-model approach reflects the complex, multi-factor decision-making typically associated with expert human researchers.
The Robotic Execution Phase utilizes three integrated stations for sample preparation, heating, and characterization. The preparation station dispenses and mixes precursor powders before transferring them into alumina crucibles. A robotic arm then loads these crucibles into one of four available box furnaces for heating. After cooling, another robotic arm transfers samples to the characterization station, where they are ground into fine powder and measured by X-ray diffraction (XRD) [6]. This physical automation enables continuous operation over extended periods—17 days in the reported study—far exceeding typical human endurance.
The Analysis and Active Learning Cycle represents the most advanced aspect of the autonomy. Synthesis products are characterized by XRD, with two ML models working together to analyze patterns. The phase and weight fractions of synthesis products are extracted using probabilistic ML models trained on experimental structures, with patterns for novel materials simulated from computed structures and corrected to reduce density functional theory errors [6]. When initial recipes fail to produce >50% yield, the system employs an active learning algorithm called ARROWS³ (Autonomous Reaction Route Optimization with Solid-State Synthesis) that integrates ab initio computed reaction energies with observed synthesis outcomes to predict improved solid-state reaction pathways [6].
Implementation of Human-AI Collaboration
The A-Lab exemplifies how human expertise can be encoded into autonomous systems while still leveraging AI's pattern recognition capabilities. This approach mirrors the Human-AI Collaborative Refinement Process demonstrated in surgical feedback analysis, which uses unsupervised machine learning with human refinement to discover meaningful categories from complex datasets [9]. In the A-Lab context, this collaboration manifests in several ways:
The system uses Historical Knowledge Integration through natural language processing of existing literature, effectively distilling decades of human research experience into actionable synthesis strategies [6]. This allows the autonomous system to benefit from the collective knowledge of the materials science community without requiring direct human consultation for each decision.
The Active Learning with Thermodynamic Grounding demonstrates how AI can extend beyond human capabilities. The ARROWS³ algorithm uses two key hypotheses: (1) solid-state reactions tend to occur between two phases at a time (pairwise), and (2) intermediate phases that leave only a small driving force to form the target material should be avoided [6]. These principles, while grounded in materials science theory, are systematically applied by the AI across a much broader range of reactions than would be practical for human researchers.
The system continuously builds a Database of Pairwise Reactions observed in its experiments—88 unique pairwise reactions were identified during its initial operation [6]. This growing knowledge base allows the system to progressively improve its predictions and avoid repeating unsuccessful pathways, demonstrating how autonomous systems can build on their experience in ways that transcend individual human memory and recall limitations.
Visualization of SDL Architectures and Workflows
The Autonomous Research Loop
Diagram 1: The closed-loop autonomous research workflow as implemented in systems like the A-Lab, showing the iterative cycle of planning, execution, analysis, and learning that enables continuous materials discovery without human intervention.
SDL Autonomy Classification Framework
Diagram 2: The spectrum of SDL autonomy levels, illustrating the decreasing human involvement and increasing integration between digital algorithms and physical platforms as systems progress from piecewise to self-motivated operation.
Essential Research Reagents and Materials for Autonomous Materials Synthesis
Table 3: Key Research Reagent Solutions for Autonomous Materials Synthesis
| Reagent/Material Category | Specific Examples | Function in Autonomous Workflow | Implementation Considerations |
|---|---|---|---|
| Precursor Materials | Oxide and phosphate powders (e.g., Fe₂O₃, Ca₃(PO₄)₂) | Source compounds for solid-state reactions | Must exhibit appropriate reactivity, purity, and handling characteristics for robotic dispensing [6] |
| Sample Containers | Alumina crucibles | Hold precursor mixtures during high-temperature processing | Must withstand repeated heating cycles and be compatible with robotic handling systems [6] |
| Characterization Standards | Silicon standard for XRD calibration | Ensure accurate phase identification and quantification | Critical for maintaining data quality across extended autonomous operation [6] |
| Robotic System Components | Robotic arms, powder dispensers, milling apparatus | Enable automated sample preparation and transfer | Reliability and maintenance requirements directly impact operational lifetime metrics [6] |
| Heating Systems | Box furnaces with robotic loading/unloading | Provide controlled thermal environments for reactions | Multiple units enable parallel processing; temperature uniformity is critical for reproducibility [6] |
| Analysis Instruments | X-ray diffractometers with automated sample changers | Characterize synthesis products and quantify yields | Throughput must align with synthesis capacity to avoid bottlenecks [6] |
The classification of Self-Driving Labs across the autonomy spectrum from assisted operation to AI researchers provides an essential framework for understanding and advancing this transformative technology. As demonstrated by systems like the A-Lab, which successfully synthesized 41 of 58 novel target compounds through continuous autonomous operation [6], the integration of computational screening, historical knowledge, machine learning, and robotics represents a paradigm shift in materials research methodology. The progression from piecewise to closed-loop systems highlights both the current capabilities and future potential of SDLs to dramatically accelerate the discovery and optimization of novel materials.
The critical importance of standardized performance metrics—including degree of autonomy, operational lifetime, throughput, experimental precision, and material usage [8]—cannot be overstated for meaningful comparison and selection of SDL platforms. These metrics enable researchers to match system capabilities with experimental requirements, ensuring that the unique challenges of different research questions are addressed with appropriate technological solutions. As the field continues to evolve toward fully self-motivated research systems, this classification framework will serve as both a roadmap for development and a benchmark for assessing progress in the ongoing integration of artificial intelligence with scientific discovery.
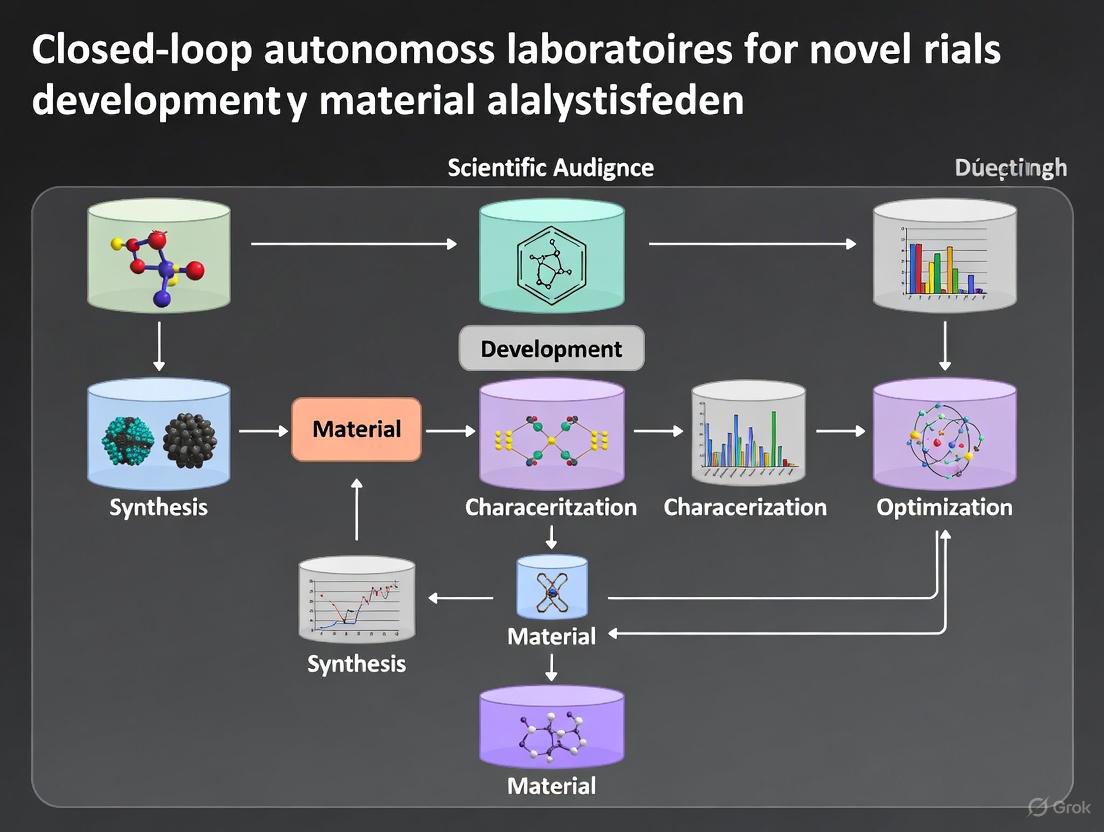
The Design-Make-Test-Analyze (DMTA) cycle serves as the fundamental operational engine driving modern scientific discovery, particularly in fields such as drug development and novel materials research. This iterative process involves designing new molecular entities or materials, synthesizing them, testing their properties, and analyzing the results to inform the next design iteration [11] [12]. Within the context of autonomous laboratories for novel materials research, the DMTA cycle transforms from a human-driven process to a fully automated, closed-loop system capable of continuous, unsupervised operation and learning [6] [13]. This evolution represents a paradigm shift in research methodology, enabling unprecedented acceleration of discovery timelines through the integration of artificial intelligence, robotics, and data science.
The transition toward autonomous experimentation addresses significant bottlenecks in traditional research approaches. While computational methods can identify promising new materials at scale, their experimental realization has traditionally been challenging and time-consuming [6]. Autonomous laboratories bridge this gap by combining automated physical hardware for sample handling and synthesis with intelligent software that plans experiments and interprets results. This convergence creates a virtuous cycle where digital tools enhance physical processes, and feedback from these improved processes informs further digital advancements [12].
Core Principles of the DMTA Cycle
The DMTA framework provides a structured approach to research and development, breaking down the complex process of optimization into manageable, iterative phases. Each phase addresses specific aspects of the discovery process, from conceptual design through experimental validation to data interpretation.
Table: The Four Phases of the DMTA Cycle
| Phase | Core Objective | Key Activities | Primary Outputs |
|---|---|---|---|
| Design | Define what to make and how to make it | Generative AI, retrosynthetic analysis, building block identification [11] [12] | Target compound structures, synthetic routes [12] |
| Make | Execute physical synthesis | Reaction setup, purification, characterization, sample preparation [11] | Synthesized compounds, analytical data [12] |
| Test | Evaluate compound properties | Biological assays, physicochemical measurements, analytical characterization [12] [13] | Experimental data on properties and performance [13] |
| Analyze | Derive insights from data | Data interpretation, pattern recognition, statistical analysis [12] [13] | Actionable insights, next-step hypotheses [13] |
In traditional research environments, the DMTA cycle faces significant implementation challenges that limit its effectiveness. These include sequential rather than parallel execution of phases, creating significant delays; data integration barriers between different specialized teams; and resource coordination inefficiencies that result in suboptimal utilization of both human expertise and analytical capabilities [14] [13]. The transition to autonomous laboratories addresses these limitations through digital integration and automation.
DMTA in Autonomous Materials Research
The application of the DMTA cycle within autonomous laboratories represents the cutting edge of materials research methodology. These systems combine robotics, artificial intelligence, and extensive data integration to create self-driving laboratories that can operate continuously with minimal human intervention.
The A-Lab Platform for Inorganic Materials
The A-Lab, an autonomous laboratory for solid-state synthesis of inorganic powders, exemplifies the implementation of closed-loop DMTA for novel materials discovery. This platform uses computations, historical data, machine learning, and active learning to plan and interpret experiments performed using robotics [6]. Over 17 days of continuous operation, the A-Lab successfully synthesized 41 of 58 novel target compounds identified using large-scale ab initio phase-stability data from the Materials Project and Google DeepMind [6].
The autonomous discovery pipeline followed by the A-Lab integrates multiple advanced technologies:
The A-Lab's workflow begins with target materials screened for stability and air compatibility. For each compound, the system generates up to five initial synthesis recipes using machine learning models trained through natural-language processing of a large database of syntheses extracted from literature [6]. This mimics the human approach of basing initial synthesis attempts on analogy to known related materials. If these literature-inspired recipes fail to produce the target with sufficient yield, the system employs an active learning algorithm called ARROWS3 (Autonomous Reaction Route Optimization with Solid-State Synthesis) that integrates ab initio computed reaction energies with observed synthesis outcomes to predict improved solid-state reaction pathways [6].
The physical implementation of the A-Lab consists of three integrated stations for sample preparation, heating, and characterization, with robotic arms transferring samples and labware between them. The preparation station dispenses and mixes precursor powders before transferring them into crucibles. A robotic arm from the heating station loads these crucibles into one of four available box furnaces. After cooling, another robotic arm transfers samples to the characterization station, where they are ground into fine powder and measured by X-ray diffraction (XRD) [6]. This integrated hardware system enables continuous 24/7 operation without human intervention.
Multi-Agent AI Systems for Drug Discovery
In pharmaceutical research, agentic AI systems represent another approach to DMTA automation. The Tippy framework employs five specialized AI agents that work collaboratively to automate the drug discovery process [13]:
This multi-agent architecture enables parallel execution of DMTA phases that would traditionally be performed sequentially. The Molecule Agent generates molecular structures and converts chemical descriptions into standardized formats. The Lab Agent manages HPLC analysis workflows, synthesis procedures, and laboratory job execution. The Analysis Agent processes job performance data and extracts statistical insights, while the Report Agent generates documentation. The Safety Guardrail Agent provides critical oversight, validating all requests for potential safety violations before execution [13]. This specialized approach allows each agent to develop deep expertise in its domain while maintaining seamless coordination across the entire DMTA cycle.
Key Methodologies and Experimental Protocols
AI-Enhanced Synthesis Planning
Computer-Assisted Synthesis Planning (CASP) has evolved from early rule-based expert systems to data-driven machine learning models [11]. Modern CASP methodologies involve both single-step retrosynthesis prediction, which proposes individual disconnections, and multi-step synthesis planning, which chains these steps into complete routes using search algorithms like Monte Carlo Tree Search or A* Search [11].
For the "Make" phase, automated synthesis platforms require precise experimental protocols. The A-Lab employs the following general methodology for solid-state synthesis:
Precursor Preparation: Precursors are dispensed by an automated system according to stoichiometric calculations and mixed thoroughly using a ball mill or similar automated mixing system.
Reaction Execution: Mixed powders are transferred to alumina crucibles and loaded into box furnaces using robotic arms. Heating profiles are applied according to predicted optimal temperatures from ML models trained on literature data [6].
Product Characterization: Synthesized materials are ground into fine powders and analyzed by X-ray diffraction. Phase and weight fractions of synthesis products are extracted from XRD patterns by probabilistic ML models trained on experimental structures [6].
Iterative Optimization: When initial synthesis recipes fail to produce >50% yield, active learning algorithms propose improved follow-up recipes based on observed reaction pathways and thermodynamic calculations [6].
Active Learning and Bayesian Optimization
Closed-loop autonomous systems employ sophisticated active learning approaches to optimize experimental outcomes. The ARROWS3 algorithm used in the A-Lab operates on two key hypotheses: (1) solid-state reactions tend to occur between two phases at a time (pairwise), and (2) intermediate phases that leave only a small driving force to form the target material should be avoided [6].
The CAMEO (Autonomous System for Materials Exploration and Optimization) platform implements on-the-fly closed-loop autonomous materials discovery using Bayesian active learning [15]. This approach enables the system to simultaneously address phase mapping and property optimization, with each cycle taking seconds to minutes. The methodology involves:
Hypothesis Definition: The AI defines testable hypotheses based on existing data and theoretical predictions.
Experiment Selection: Using Bayesian optimization, the system selects experiments that maximize information gain while minimizing resource consumption.
Rapid Characterization: High-throughput techniques like synchrotron XRD provide immediate feedback on experimental outcomes.
Model Updating: Results inform updates to the AI's predictive models, creating an increasingly accurate representation of the materials landscape [15].
Table: Key Research Reagent Solutions in Autonomous Materials Synthesis
| Reagent Category | Specific Examples | Function in Experiments |
|---|---|---|
| Precursor Oxides | Binary and ternary metal oxides (e.g., Li₂O, Fe₂O₃, P₂O₅) | Provide elemental components for solid-state reactions of oxide materials [6] |
| Phosphate Precursors | NH₄H₂PO₄, (NH₄)₂HPO₄, metal phosphates | Source of phosphorus for phosphate compound synthesis [6] |
| Building Blocks for Organic Synthesis | Carboxylic acids, amines, boronic acids, halides [11] | Provide functional handles for carbon-carbon bond formation and scaffold diversification [11] |
| Catalysts | Palladium catalysts for cross-coupling (e.g., Suzuki, Buchwald-Hartwig) [11] | Enable key bond-forming reactions in complex molecule synthesis [11] |
Quantitative Performance Metrics
Autonomous DMTA implementations have demonstrated significant improvements in research efficiency and success rates. The A-Lab achieved a 71% success rate (41 of 58 compounds) in synthesizing novel inorganic materials over 17 days of continuous operation [6]. Analysis revealed this success rate could be improved to 74% with minor modifications to the decision-making algorithm, and further to 78% with enhanced computational techniques [6].
The efficiency gains stem from multiple factors:
Table: Efficiency Metrics in Autonomous DMTA Cycles
| Metric | Traditional DMTA | Autonomous DMTA | Improvement Factor |
|---|---|---|---|
| Cycle Time | Weeks to months [13] | Continuous operation with cycles of "seconds to minutes" [15] | 10-100x acceleration [15] |
| Success Rate for Novel Materials | Highly variable, often <50% for first attempts | 71% for first attempts on novel compounds [6] | ~40% improvement for challenging targets [6] |
| Experimental Throughput | Limited by human capacity | 355 recipes tested in 17 days [6] | 20+ experiments per day [6] |
| Resource Utilization | Sequential use of instruments | Parallel operation of multiple furnaces and characterization tools [6] | 3-4x better equipment utilization [6] |
For the 17 targets not obtained by the A-Lab, analysis revealed specific failure modes: sluggish reaction kinetics (11 targets), precursor volatility (2 targets), amorphization (2 targets), and computational inaccuracy (2 targets) [6]. This detailed failure analysis provides actionable insights for improving both computational predictions and experimental approaches in future iterations.
Implementation Challenges and Future Directions
While autonomous DMTA cycles offer tremendous potential, several challenges remain in their widespread implementation. Effective autonomous systems require high-quality, FAIR (Findable, Accessible, Interoperable, Reusable) data principles to build robust predictive models [11]. The "analysis gap" between single-step model performance metrics and overall route-finding success represents another significant challenge [11].
Future developments in autonomous DMTA cycles will likely focus on several key areas:
Enhanced Human-AI Collaboration: Systems will evolve toward more natural interfaces, potentially including "Chemical ChatBots" that allow researchers to interact with AI systems through conversational dialogue [11].
Cross-Domain Knowledge Transfer: Techniques that enable learning across different materials classes and synthesis methodologies will reduce the need for extensive training data in new domains.
Integrated Multi-Scale Modeling: Combining quantum calculations, molecular dynamics, and macro-scale process modeling will improve prediction accuracy across different length and time scales.
Adaptive Experimentation: Systems that can dynamically adjust their hypothesis-testing strategies based on real-time results and changing research priorities.
The evolution toward fully autonomous research systems represents a fundamental transformation in scientific methodology. By closing the DMTA loop through integrated AI and robotics, these systems enable a virtuous cycle of continuous learning and optimization that dramatically accelerates the pace of discovery while potentially increasing reproducibility and reducing costs [6] [12] [13]. As these technologies mature, they promise to redefine the roles of human researchers, freeing them from routine experimental tasks to focus on higher-level scientific questions and strategic direction.
The Materials Genome Initiative (MGI), launched in 2011, is a multi-agency U.S. initiative with a bold vision: to discover, manufacture, and deploy advanced materials at twice the speed and a fraction of the cost of traditional methods [1] [16]. While substantial progress has been made through computational tools and data infrastructures, a critical barrier remains: empirical validation. Physical experimentation, often reliant on manual, low-throughput processes, has become the primary bottleneck, hampering the overall pace of materials innovation [1].
Self-Driving Laboratories (SDLs) represent a transformative pathway to overcome this limitation. These systems integrate robotics, artificial intelligence (AI), and autonomous experimentation into a closed-loop, capable of rapid hypothesis generation, execution, and refinement without human intervention [1]. This technical guide explores the strategic imperative of aligning SDL development with the MGI framework, detailing how this synergy is essential for creating a national Autonomous Materials Innovation Infrastructure that can secure U.S. leadership in critical technology sectors [1].
The MGI Strategic Framework: Creating a Conducive Environment for SDLs
The MGI has evolved to explicitly recognize and address the experimental gap. Its 2021 strategic plan outlines three core goals that create a conducive policy and technical environment for SDLs [16]:
- Unify the Materials Innovation Infrastructure (MII): The MII is a framework that integrates advanced modeling, computational and experimental tools, and quantitative data. SDLs are poised to become the experimental pillar of this infrastructure [1] [16] [17].
- Harness the power of materials data: SDLs inherently generate vast amounts of high-quality, machine-readable data, including detailed digital provenance (metadata), which is crucial for building robust, reusable data resources [1] [16].
- Educate, train, and connect the materials R&D workforce: The operation and management of SDLs require a new skill set, fostering a workforce proficient in data science, robotics, and AI, alongside traditional materials science [16].
Furthermore, the MGI has spurred flagship funding programs that directly support the SDL ecosystem, including the NSF's Designing Materials to Revolutionize and Engineer our Future (DMREF) and Materials Innovation Platforms (MIP), which provide large-scale scientific ecosystems for accelerated discovery [17].
The Technical Architecture of Self-Driving Labs
At its core, an SDL is a closed-loop system that automates the entire Design-Make-Test-Analyze (DMTA) cycle [18]. Its technical architecture can be decomposed into five interlocking layers, each with distinct components and functions essential for autonomous operation.
Table 1: The Five-Layer Architecture of a Self-Driving Lab
| Layer | Key Components | Primary Function |
|---|---|---|
| Actuation Layer | Robotic arms, powder dispensers, syringe pumps, box furnaces, milling modules | Executes physical tasks for synthesis and processing [1] [6]. |
| Sensing Layer | X-ray diffraction (XRD), spectrometers, microscopes, environmental sensors | Captures real-time data on material properties and process conditions [1] [6]. |
| Control Layer | Laboratory Operating System, schedulers, safety interlocks, device drivers | Orchestrates and synchronizes hardware operations for precise experimental sequences [1]. |
| Autonomy Layer | Bayesian optimization, reinforcement learning, active learning, large language models (LLMs) | Plans experiments, interprets outcomes, and updates the research strategy adaptively [1] [6]. |
| Data Layer | Cloud databases, data lakes, metadata schemas, ontologies, APIs | Manages, stores, and provides access to experimental data, models, and provenance information [1]. |
The autonomy layer is what distinguishes an SDL from simple automation. Rather than executing a fixed script, the AI in this layer uses algorithms like Bayesian optimization and reinforcement learning to decide which experiment to perform next based on all prior results, efficiently navigating complex, multidimensional design spaces [1]. The integration of large language models (LLMs) further enhances this by allowing researchers to interact with the SDL using natural language or by enabling the system to parse scientific literature to inform its initial experimental plans [1].
Exemplar SDL Implementation: The A-Lab for Novel Inorganic Materials
The A-Lab, developed and reported in Nature in 2023, serves as a premier case study for a fully autonomous solid-state synthesis laboratory [6]. Its workflow and performance metrics provide a concrete template for how SDLs align with and advance the goals of the MGI.
Experimental Workflow and Protocol
The A-Lab's operation exemplifies a complete MGI approach, integrating computation, data, and autonomous experimentation into a seamless, iterative workflow [6]:
- Target Identification: Targets are novel, air-stable inorganic powders identified through large-scale ab initio phase-stability calculations from databases like the Materials Project and Google DeepMind.
- Literature-Inspired Recipe Generation: A natural-language processing model, trained on a vast corpus of historical synthesis literature, proposes initial precursor combinations and a heating temperature.
- Robotic Execution:
- Preparation: Precursor powders are automatically dispensed and mixed by a robotic arm and transferred to an alumina crucible.
- Heating: The crucible is loaded into one of four box furnaces for firing.
- Characterization: After cooling, the sample is ground and analyzed by X-ray Diffraction (XRD).
- Autonomous Data Analysis: The XRD pattern is analyzed by machine learning models to identify phases and quantify yield via automated Rietveld refinement.
- Active Learning Optimization: If the target yield is below a threshold (e.g., 50%), the ARROWS³ active learning algorithm proposes a new recipe. This algorithm uses a growing database of observed solid-state reactions and thermodynamic data from the Materials Project to avoid intermediates with low driving forces and prioritize more favorable reaction pathways.
Performance and Quantitative Outcomes
Over 17 days of continuous operation, the A-Lab successfully synthesized 41 out of 58 novel target compounds, demonstrating a 71% success rate in realizing computationally predicted materials [6]. This result validates the effectiveness of AI-driven platforms and high-throughput ab initio calculations for identifying synthesizable materials.
Table 2: A-Lab Experimental Outcomes and Failure Analysis
| Metric | Value | Context / Implication |
|---|---|---|
| Operation Duration | 17 days | Continuous, unattended operation [6]. |
| Novel Targets Attempted | 58 | Compounds with no prior synthesis reports [6]. |
| Successfully Synthesized | 41 | Demonstrates high fidelity of computational predictions [6]. |
| Success Rate | 71% | Could be improved to 78% with enhanced algorithms [6]. |
| Primary Failure Mode | Slow kinetics (11/17 failures) | Reactions with low driving force (<50 meV/atom) [6]. |
| Other Failure Modes | Precursor volatility, amorphization, computational inaccuracy | Highlights areas for improvement in SDL design [6]. |
The Scientist's Toolkit: Key Research Reagent Solutions
The operation of an SDL like the A-Lab relies on a suite of integrated hardware and software "reagents" that enable its autonomous function.
Table 3: Essential Research Reagent Solutions for an SDL
| Item / Solution | Function | Role in the Autonomous Workflow |
|---|---|---|
| Robotic Arm | Sample and labware transfer between stations. | Physically connects the synthesis, heating, and characterization modules [6]. |
| Precursor Powder Library | Raw chemical ingredients for solid-state reactions. | The "chemical space" the SDL can explore; must be compatible with automated dispensing [6]. |
| Automated Box Furnaces | Provide controlled high-temperature environments for reactions. | Enable unattended heating and cooling cycles for solid-state synthesis [6]. |
| X-ray Diffractometer (XRD) | Provides crystal structure and phase composition data. | The primary sensor for characterizing synthesis output; data is fed directly to AI for analysis [6]. |
| Bayesian Optimization Algorithm | AI for navigating complex parameter spaces. | The core of the autonomy layer; decides the next best experiment to maximize learning or performance [1]. |
| ARROWS³ Active Learning | Plans optimized solid-state reaction pathways. | Uses thermodynamic data and observed reactions to avoid kinetic traps and improve yield [6]. |
Strategic Deployment Models for National Impact
To fully integrate SDLs into the MGI and achieve national-scale impact, several deployment models are being advanced [1]:
- Centralized SDL Foundries: These facilities, housed in national laboratories or large consortia, would concentrate high-end, specialized, or hazardous experimentation capabilities. They would function as national user facilities, allowing researchers to submit digital workflows for remote execution, thus providing broad access to cutting-edge tools [1].
- Distributed Modular Networks: This model involves deploying lower-cost, modular SDL platforms in individual university or industrial labs. These distributed systems offer flexibility and local ownership. When connected via cloud platforms and shared metadata standards, they can function as a "virtual foundry," pooling data and accelerating collective progress across the community [1].
- Hybrid Approach: A layered model, analogous to cloud computing, where preliminary research is conducted on local distributed SDLs, and more complex, resource-intensive tasks are escalated to centralized foundries. This maximizes both accessibility and overall efficiency [1].
The alignment of Self-Driving Labs with the Materials Genome Initiative represents a paradigm shift in materials science. SDLs provide the missing experimental pillar to the MGI vision, transforming physical experimentation from a manual, low-throughput art into a programmable, scalable, and data-rich infrastructure [1]. The demonstrated success of platforms like the A-Lab in rapidly realizing novel materials proves the viability of this approach.
Fully realizing this potential requires continued investment in the Materials Innovation Infrastructure, including the development of open data standards, shared software APIs, and a trained workforce capable of operating at the intersection of materials science, robotics, and AI [1] [17]. By strategically deploying SDLs through centralized and distributed models, the MGI can achieve its foundational goal: dramatically accelerating the discovery and deployment of advanced materials to address pressing challenges in energy, security, and economic competitiveness.
How Autonomous Labs Work: The DMTA Cycle and Breakthrough Applications
In the pursuit of accelerated materials discovery, closed-loop autonomous laboratories represent a paradigm shift. These self-driving labs iteratively plan, execute, and analyze experiments with minimal human intervention. The Spatial Data Lab (SDL) project provides a powerful, spatiotemporal-data-driven architectural blueprint for such systems [19]. This whitepaper details a five-layer architecture for an SDL, deconstructing its core components from physical actuation to data-driven intelligence, specifically contextualized for novel materials research.
The Spatial Data Lab (SDL) is a collaborative initiative aimed at advancing applied research through an open-source infrastructure for data linkage, analysis, and collaboration [19]. When applied to autonomous materials research, an SDL transcends being a mere data repository; it becomes an active, reasoning system. It integrates experimental synthesis, high-throughput characterization, and multiscale simulation data to guide the discovery of materials with targeted properties.
The core challenge lies in harmonizing diverse, complex data streams—from atomistic simulations to panoramic electron microscopy images [20]—into a coherent, actionable knowledge graph. The five-layer architecture proposed herein addresses this by creating a reproducible, replicable, and expandable (RRE) framework [19], essential for establishing a robust foundation for autonomous scientific discovery.
The Five-Layer Architecture: A Detailed Breakdown
The architecture of an SDL for materials design is stratified into five distinct yet interconnected layers, each serving a specific function in the journey from a research hypothesis to empirical data and insight.
Layer 1: Perception & Actuation Layer
This is the physical interface of the SDL, where the digital world interacts with the material environment. It consists of sensors that collect raw data from experiments and actuators that perform physical tasks.
- Function: To observe the material world and execute physical actions based on decisions from higher layers.
- Key Components:
- Sensors: Advanced characterization tools such as Scanning Electron Microscopes (SEM) and Atom Probe Tomography (APT) that generate high-resolution, panoramic images and near-atomic-scale chemical composition data [20].
- Actuators: Robotic arms for sample handling, automated pipetting systems for solution-based synthesis, and stage controllers that position samples for characterization or processing.
- Data Output: Raw, unstructured data from sensors (e.g., micrograph images, spectral data) and status logs from actuators.
Layer 2: Network & Connectivity Layer
This layer is the central nervous system, responsible for the secure and reliable transmission of data and commands.
- Function: To facilitate bidirectional communication between the Perception Layer, data processing units, and control systems.
- Key Components & Protocols:
- Communication Protocols: Depending on latency, bandwidth, and distance requirements, a mix of protocols is used. For device-level communication, MQTT is ideal for its lightweight nature. For reliable message queuing in industrial settings, AMQP may be employed [21].
- Edge Gateways: Devices that perform initial data preprocessing and aggregation at the source, reducing latency and bandwidth usage by transmitting only critical information [21].
Layer 3: Data Processing & Middleware Layer
This is the computational brain of the SDL, where raw data is transformed into structured information. It employs advanced deep learning for automated analysis and simulation.
- Function: To store, process, and analyze spatiotemporal data, enabling automated feature extraction and initial insight generation.
- Key Technologies & Methodologies:
- Deep Learning Models: Convolutional Neural Networks (CNNs) are used for tasks like semantic segmentation, object detection, and classification of microstructures from SEM images [20]. Spatio-Temporal Deep Learning (SDL) models, such as ConvLSTM networks, can simulate physical phenomena like ultrasonic wave propagation faster than traditional finite element solvers [22].
- Data Storage: A centralized, highly reliable data store, akin to a Shared Data Layer, which consolidates subscription, session, and results data, making it accessible to all other layers and functions [23]. This aligns with the SDL's commitment to building comprehensive spatiotemporal data services [19].
Table 1: Deep Learning Applications in the Data Processing Layer for Materials Science
| Deep Learning Model | Application in Materials Research | Function | Output |
|---|---|---|---|
| Convolutional Neural Network (CNN) | Microstructural analysis of SEM images [20] | Semantic segmentation, damage site detection | Labeled images identifying phases and defects |
| 3D Convolutional Model | Analysis of 3D Atom Probe Tomography (APT) data [20] | 3D segmentation and classification | 3D maps of phase transformations at atomic scale |
| Spatio-Temporal Deep Learning (SDL/ConvLSTM) | Modelling wave propagation for non-destructive testing [22] | Predicting spatiotemporal sequence of wave dynamics | Simulated wave interaction with material defects |
Layer 4: Application & Workflow Layer
This layer translates processed data into executable scientific workflows and user-facing applications. It is where the "autonomous" logic is codified.
- Function: To host the tools that control the experimental workflow, enable data visualization, and facilitate human-SDL interaction.
- Key Components:
- Workflow-Driven Platforms: KNIME is a pivotal no-code/low-code platform used to construct reproducible, scalable, and workflow-driven methodologies [24] [19]. For example, a workflow can automatically take segmented SEM images from Layer 3, use them to generate a Finite Element (FE) mesh, and launch a simulation to evaluate elastoplastic behavior [20].
- Data Visualization Tools: Dashboards and interfaces for monitoring experiment progress and results.
Layer 5: Business & Intelligence Layer
This is the strategic apex of the SDL, responsible for project governance, resource allocation, and high-level decision-making to ensure research efficacy and return on investment.
- Function: To oversee the entire SDL operation, analyze outcomes, and make strategic decisions about future research directions.
- Key Processes:
- Governance: Enforcing data management policies and ensuring compliance with scientific and ethical standards [21].
- Performance Analysis: Evaluating the success of discovery campaigns using key performance indicators (KPIs).
- Strategy & Planning: Using insights from all layers to define new hypotheses and allocate resources for subsequent closed-loop cycles.
Implementation & Experimental Protocols
Implementing an SDL requires a meticulous approach to workflow design and data management. Below is a core protocol for a typical autonomous analysis cycle.
Core Experimental Protocol: Automated Microstructural Analysis & Simulation
Objective: To automatically characterize a material's microstructure from an SEM image and predict its mechanical properties through simulation.
- Sample Imaging & Data Acquisition (Layer 1): A synthesized material sample is automatically loaded into an SEM. A high-resolution, panoramic micrograph is collected [20].
- Data Transmission (Layer 2): The image data is securely transmitted to the central data processing unit.
- Microstructural Segmentation (Layer 3): A pre-trained CNN model performs semantic segmentation on the SEM image, identifying and labeling different phases and detecting damage sites or defects [20].
- Workflow Execution (Layer 4): A pre-built KNIME workflow is triggered:
- The segmented image is converted into a computational mesh.
- This mesh is passed as input to a Finite Element (FE) simulation package (e.g., MOOSE) [20].
- The FE simulation runs to calculate the homogenized elastoplastic and fracture behavior of the material.
- Decision & Analysis (Layer 5): The simulation results are analyzed against target properties. The outcome informs the planning system to either synthesize a new material variant, conduct further characterization, or validate the finding.
Data Flow Visualization
The following diagram illustrates the logical flow of data and commands through the five layers during the automated experimental protocol.
Data Flow in a Closed-Loop SDL for Materials Research
The Scientist's Toolkit: Essential Research Reagents & Solutions
Beyond the architectural framework, the practical operation of an SDL relies on a suite of computational and data "reagents."
Table 2: Key Research Reagent Solutions for an SDL
| Tool / Solution | Type | Primary Function in SDL |
|---|---|---|
| KNIME Analytics Platform | Software Platform | Provides a no-code/low-code environment for building reproducible, workflow-driven data analysis and orchestration [24] [19]. |
| Harvard SDL Dataverse | Data Repository | Curated, open-access repository of spatiotemporal datasets used for training models and foundational research [19]. |
| Geospatial Extension for KNIME | Software Tool | Enables advanced geospatial and spatiotemporal analysis within the KNIME workflow environment [19]. |
| ConvLSTM Algorithm | AI Model | A spatio-temporal deep learning architecture for simulating complex physical phenomena like wave propagation [22]. |
| OVITO | Software Tool | Open-source visualization and analysis software for atomistic and microstructural simulation data [20]. |
The five-layer architecture for a Spatial Data Lab provides a comprehensive and scalable framework for building closed-loop autonomous laboratories. By logically separating the concerns of actuation, connectivity, data processing, workflow, and strategy, this architecture brings clarity and order to the immense complexity of automated materials research. The integration of workflow-driven platforms like KNIME and advanced AI models for data analysis and simulation is the cornerstone of this approach, enabling the RRE principles that are critical for scientific progress [19]. As these technologies mature, this SDL architecture will become the standard operating system for the accelerated discovery and design of the next generation of novel materials.
The integration of artificial intelligence (AI) into the design phase of materials science represents a paradigm shift in research methodology. This whitepaper details how AI-driven hypothesis generation and synthesis planning serve as the core intellectual engine within closed-loop autonomous laboratories. By leveraging multimodal data fusion, active learning, and robotic experimentation, these systems accelerate the discovery and development of novel materials and pharmaceutical compounds. This technical guide provides an in-depth analysis of the methodologies, protocols, and reagent solutions that underpin this transformative approach, with a specific focus on applications in drug development and materials research.
Core AI Methodologies in Design and Planning
The design phase in autonomous laboratories is governed by sophisticated AI models that move beyond traditional computational tools. These systems integrate diverse data sources and learning strategies to form hypotheses and plan syntheses with minimal human intervention.
Multimodal Data Fusion: Modern AI platforms, such as the CRESt (Copilot for Real-world Experimental Scientists) system developed at MIT, incorporate heterogeneous data types including experimental results, scientific literature, chemical compositions, and microstructural images [25]. This approach mimics the collaborative environment of human scientists, who consider personal experience, intuition, and peer feedback alongside raw data. Natural language interfaces allow researchers to converse with these systems without coding, making advanced AI accessible to domain experts.
Active Learning with Bayesian Optimization: AI systems employ active learning paired with Bayesian optimization (BO) to make efficient use of experimental data [25]. Unlike basic BO that operates in a constrained design space, advanced implementations use literature-derived knowledge embeddings to create a reduced search space that captures most performance variability. As one MIT researcher explains, "Bayesian optimization is like Netflix recommending the next movie to watch based on your viewing history, except instead it recommends the next experiment to do" [25]. This methodology enables the system to learn from each experimental iteration and refine its hypotheses continuously.
Knowledge-Based Synthesis Planning: Systems like the A-Lab leverage natural language processing of extensive synthesis databases to assess target similarity and propose initial synthesis recipes [6]. This mimics the human approach of basing new synthesis attempts on analogies to known materials. The A-Lab employs machine learning models trained on historical data from literature to propose precursor combinations and heating parameters, achieving a remarkable success rate in synthesizing novel inorganic compounds.
Experimental Protocols and Workflows
The transformation of AI-generated hypotheses into tangible materials requires structured experimental protocols executed through automated workflows. The following section details specific methodologies from pioneering systems in the field.
CRESt Platform for Fuel Cell Catalyst Discovery
MIT researchers developed the CRESt platform specifically for addressing complex materials discovery challenges, exemplified by their work on fuel cell catalysts [25].
Table 1: Key Reagent Solutions for Fuel Cell Catalyst Discovery
| Research Reagent | Function/Explanation |
|---|---|
| Palladium Precursors | Serves as primary catalytic base; expensive precious metal component requiring optimization or replacement [25]. |
| Non-Precious Metal Additives | Cheap elements (e.g., Fe, Co, Ni) incorporated to create optimal coordination environment and reduce costs [25]. |
| Formate Fuel Solution | Energy source for direct formate fuel cell testing; performance measured by power density output [25]. |
| Liquid Handling Robot Reagents | Up to 20 precursor molecules and substrates can be incorporated into automated recipe formulation [25]. |
Experimental Workflow:
- Literature Analysis and Hypothesis Generation: CRESt's models search scientific papers for descriptions of elements or precursor molecules with potential utility for the target application.
- Knowledge Embedding and Space Reduction: The system creates representations of each recipe based on prior knowledge, then performs principal component analysis to reduce the search space.
- Bayesian Optimization: The AI proposes specific material compositions within this reduced space for experimental testing.
- Robotic Synthesis: A liquid-handling robot and carbothermal shock system rapidly synthesize materials based on the proposed recipes.
- Automated Characterization and Testing: An electrochemical workstation tests performance, while automated electron microscopy provides structural analysis.
- Active Learning Loop: Newly acquired multimodal data and human feedback are incorporated to refine the search space and hypotheses.
This workflow enabled the exploration of over 900 chemistries and 3,500 electrochemical tests, resulting in a catalyst material delivering record power density in a direct formate fuel cell with just one-fourth the precious metals of previous devices [25].
A-Lab for Novel Inorganic Powder Synthesis
The A-Lab, documented in a landmark Nature publication, focuses on the solid-state synthesis of inorganic powders, addressing unique challenges in handling and characterizing solid materials [6].
Table 2: A-Lab Synthesis and Characterization Parameters
| Experimental Parameter | Specification/Implementation |
|---|---|
| Target Materials | Air-stable inorganic powders identified via the Materials Project and Google DeepMind databases [6]. |
| Precursor Preparation | Solid powders milled to ensure good reactivity despite differences in density, flow behavior, and particle size [6]. |
| Heating System | Four box furnaces for solid-state reactions at various temperatures [6]. |
| Primary Characterization | X-ray diffraction (XRD) with automated Rietveld refinement for phase identification and weight fraction analysis [6]. |
| Success Metric | Target yield >50% as the majority phase in the synthesis product [6]. |
Experimental Protocol:
- Computational Target Identification: The process begins with targets predicted to be on or near the convex hull of stable phases from ab initio calculations.
- Literature-Informed Recipe Proposal: Initial synthesis recipes (up to five per target) are generated by ML models trained on text-mined literature data.
- Robotic Execution: Robotic arms handle precursor dispensing, mixing, furnace loading, and sample transfer.
- XRD Analysis and Phase Identification: Probabilistic ML models analyze XRD patterns to identify phases and weight fractions.
- Active Learning Optimization: If initial recipes fail, the ARROWS³ algorithm uses observed reaction pathways and thermodynamic calculations to propose improved synthesis routes.
In continuous operation, the A-Lab successfully synthesized 41 of 58 novel target compounds over 17 days, demonstrating the effectiveness of AI-driven platforms for autonomous materials discovery [6].
Quantitative Performance Analysis
The implementation of AI-driven design and planning systems has yielded measurable improvements in the efficiency and success of materials discovery efforts.
Table 3: Performance Metrics of AI-Driven Discovery Platforms
| Platform/System | Key Performance Indicators | Experimental Outcomes |
|---|---|---|
| CRESt Platform [25] | - 900+ chemistries explored- 3,500+ electrochemical tests- 3-month discovery timeline | 9.3-fold improvement in power density per dollar over pure palladium; record power density for direct formate fuel cell |
| A-Lab [6] | - 41/58 novel compounds synthesized- 17 days of continuous operation- 33 elements, 41 structural prototypes | 71% success rate in synthesizing computationally-predicted materials; 74-78% potential success with algorithm improvements |
| AlphaSynthesis [26] | - Forward and reverse synthesis planning- Chemical and biological catalyst integration- Dynamic database optimization | Framework for identifying effective and automatable synthetic routes for small molecule discovery and manufacturing |
Technical Implementation Requirements
Implementing an effective AI-driven design system requires specific technical components and infrastructure to support the complex workflow from hypothesis to validation.
Table 4: Core Technical Requirements for Autonomous Research Systems
| System Component | Technical Specifications | Function in Design Phase |
|---|---|---|
| Computational Infrastructure | High-performance computing for knowledge embedding, Bayesian optimization, and multimodal data processing [25]. | Enables rapid hypothesis generation and search space reduction prior to experimental validation. |
| Robotic Synthesis Systems | Liquid-handling robots, carbothermal shock systems, and solid powder handling capabilities [25] [6]. | Executes AI-proposed synthesis recipes with precision and reproducibility at scale. |
| Automated Characterization | XRD, automated electron microscopy, electrochemical workstations, optical microscopy [25] [6]. | Provides immediate feedback on synthesis outcomes to inform subsequent hypothesis refinement. |
| Computer Vision Systems | Cameras coupled with visual language models for experiment monitoring and issue detection [25]. | Identifies reproducibility problems and suggests corrections during experimental execution. |
Workflow Visualization
AI-Driven Design Phase Workflow
The diagram above illustrates the integrated workflow of AI-driven hypothesis and synthesis planning within a closed-loop autonomous laboratory. The process begins with computational target identification, proceeds through AI-driven planning and robotic execution, and incorporates active learning to iteratively refine hypotheses based on experimental outcomes.
The 'Design' phase, powered by AI-driven hypothesis generation and synthesis planning, constitutes the intellectual core of closed-loop autonomous laboratories. By integrating multimodal data sources, implementing active learning strategies, and leveraging robotic experimentation, these systems dramatically accelerate the discovery of novel materials with tailored properties. The experimental protocols and technical requirements outlined in this whitepaper provide a framework for research institutions and pharmaceutical companies seeking to implement these transformative technologies. As AI systems continue to evolve, their role in scientific discovery will expand from automated assistants to genuine collaborative partners in research, pushing the boundaries of materials science and drug development into new frontiers.
Within the framework of closed-loop autonomous laboratories, the 'Make' (robotic synthesis) and 'Test' (automated characterization) phases form the core physical engine that transforms digital hypotheses into tangible, validated materials. These systems close the critical gap between AI-predicted materials and their experimental realization, enabling a continuous, iterative discovery process that operates at a scale and speed unattainable through traditional manual methods [6] [27]. Self-driving labs (SDLs) integrate robotics, artificial intelligence, and automated experimentation to execute and analyze thousands of experiments in real-time, dramatically accelerating the pace of research [28]. This technical guide details the components, methodologies, and data flows of these systems, providing a foundation for researchers and drug development professionals aiming to implement or collaborate with autonomous materials discovery platforms.
Robotic Synthesis: The 'Make' Phase
The 'Make' phase involves the physical synthesis of target materials, a process fully automated through specialized robotic systems and informed by computational design.
Core Synthesis Platform Components
Fully autonomous labs, such as the A-Lab, integrate several key physical stations to handle solid-state synthesis of inorganic powders [6]:
- Sample Preparation Station: This module is responsible for the automated dispensing and mixing of precursor powders. The blended powders are then transferred into crucibles, ready for heating.
- Robotic Heating Station: A robotic arm loads the prepared crucibles into one of multiple available box furnaces. The system manages the heating and subsequent cooling of samples according to computationally derived recipes.
- Robotic Transfer Systems: Robotic arms facilitate the transfer of samples and labware between the preparation, heating, and characterization stations, creating a continuous workflow.
Computational Recipe Generation and Optimization
Synthesis is guided by intelligent planning systems that move beyond simple automation to embodied AI:
- Literature-Inspired Recipe Proposal: Initial synthesis recipes are generated by machine learning models that use natural-language processing to assess target material "similarity" from a large database of historical syntheses [6]. This mimics a human researcher's approach of basing initial attempts on analogous known materials.
- Active Learning Optimization: When initial recipes fail to produce a high target yield (>50%), active learning algorithms, such as ARROWS3, close the loop. These systems integrate ab initio computed reaction energies with observed experimental outcomes to predict and propose improved solid-state reaction pathways [6]. This approach prioritizes reaction routes that avoid intermediate phases with low driving forces for the target material.
The following workflow diagram illustrates the integrated process of the 'Make' and 'Test' phases within a closed-loop autonomous laboratory.
Key Reagent Solutions & Robotic Components
Table 1: Essential Materials and Robotic Components for Robotic Solid-State Synthesis
| Item Name | Function/Role in Synthesis |
|---|---|
| Precursor Powders | High-purity starting materials that react to form the target inorganic compound. The A-Lab has successfully worked with precursors for oxides and phosphates spanning 33 elements [6]. |
| Alumina Crucibles | Containers that hold precursor powders during high-temperature reactions in box furnaces, providing stability and resistance to reaction [6]. |
| Robotic Liquid Handlers | Automated systems that handle liquid reagents, minimizing manual pipetting errors and increasing efficiency in tasks like high-throughput screening and serial dilutions [29]. |
| AI-Powered Pipetting Systems | Advanced liquid handling systems that incorporate real-time decision-making to optimize volume transfers based on sample properties, enhancing consistency in complex protocols [29]. |
Automated Characterization: The 'Test' Phase
The 'Test' phase involves the automated analysis of synthesis products to determine success and guide subsequent experimentation.
Core Characterization Methodology: X-Ray Diffraction
The primary characterization technique used for automated phase identification is X-ray diffraction (XRD):
- Automated Sample Preparation: After heating and cooling, a robotic arm transfers the sample to a station where it is ground into a fine powder and prepared for XRD measurement [6].
- Machine Learning-Powered Phase Analysis: The resulting XRD patterns are analyzed by probabilistic ML models trained on experimental structures from the Inorganic Crystal Structure Database (ICSD). For novel materials with no experimental reports, diffraction patterns are simulated from computed structures and corrected for density functional theory (DFT) errors [6].
- Automated Validation: The phases identified by ML are confirmed through automated Rietveld refinement, which provides accurate weight fractions of all phases present in the product. These quantitative results are reported to the lab's management server to inform the next experimental iteration [6].
Key Characterization Tools & Data Analysis
Table 2: Key Tools for Automated Characterization and Data Analysis
| Tool / Technique | Function/Role in Characterization |
|---|---|
| X-ray Diffractometer (XRD) | The primary instrument for determining the crystalline phases present in a synthesized powder. It is integrated directly into the automated workflow [6]. |
| Probabilistic ML Models | Machine learning models that interpret multi-phase diffraction spectra to identify the phases present in a sample and estimate their weight fractions [6]. |
| Automated Rietveld Refinement | A computational method used to refine crystal structure parameters against the entire XRD pattern, providing a final, validated quantitative analysis of the sample's composition [6]. |
| Cloud-Integrated Digital Lab Notebooks | Software systems that automatically document experiments, data, and analysis, enabling real-time collaboration, secure data storage, and maintaining organized, accessible records [29]. |
Integrated Workflows & Performance Data
The true power of autonomous labs emerges from the tight integration of the 'Make' and 'Test' phases into a single, continuous workflow.
Experimental Outcomes and Performance Metrics
In a landmark demonstration, an A-Lab operated continuously for 17 days, attempting to synthesize 58 novel inorganic compounds identified through large-scale ab initio calculations from the Materials Project and Google DeepMind [6]. The results validate the effectiveness of this integrated approach.
Table 3: Quantitative Performance Outcomes from a 17-Day A-Lab Campaign [6]
| Metric | Result | Implication |
|---|---|---|
| Successfully Synthesized Novel Compounds | 41 out of 58 | A 71% success rate in first attempts at novel materials, demonstrating the predictive power of computational screening combined with automated synthesis. |
| Compounds with No Prior Synthesis Reports | 52 out of 58 | The system is capable of pioneering the synthesis of truly novel materials, not just reproducing known ones. |
| Novel Compounds Synthesized from Literature Recipes | 35 out of 41 | Highlights the utility of ML models trained on historical data for proposing viable initial synthesis recipes. |
| Targets Optimized via Active Learning | 9 out of 58 | For cases where initial recipes failed, the closed-loop system autonomously identified improved synthesis routes. |
Analysis of Failure Modes
Of the 17 targets not obtained, analysis revealed specific failure modes, providing actionable insights for improving both computational and experimental methods [6]:
- Slow Reaction Kinetics: The most common issue, affecting 11 targets, was linked to reaction steps with low thermodynamic driving forces (<50 meV per atom).
- Other Identified Modes: Additional barriers included precursor volatility, amorphization of products, and inaccuracies in the computational data itself [6].
Future Directions & Community-Driven Labs
The next evolution of these labs moves from automation to collaboration. Research groups are now working to transform SDLs from isolated, lab-centric tools into shared, community-driven platforms [28]. This involves:
- Developing Public-Facing Interfaces: Creating web interfaces that allow external researchers to design experiments, submit requests, and explore data generated by the SDL [28].
- Integration with Science-Ready LLMs: Developing large language model (LLM) agents to help users navigate complex experimental datasets and propose new experiments using retrieval-augmented generation (RAG) [28].
- Policy and Infrastructure Support: There is a growing push for policymakers to scale autonomous experimentation as a core pillar of national AI infrastructure, with initiatives such as the proposed AI Materials Science Ecosystem (AIMS-EC) aiming to create an open, cloud-based portal for the materials science community [27].
In the context of closed-loop autonomous laboratories for novel materials research, the 'Analyze' phase represents the critical intellectual core of the operation. This phase is where data from high-throughput experiments and computations are transformed into actionable knowledge, guiding the subsequent cycle of experimentation in a continuous feedback loop. The fundamental challenge in accelerated materials discovery is efficiently navigating a vast, high-dimensional search space where trial-and-error approaches are prohibitively expensive and time-consuming [30]. Active learning, a subfield of machine learning, directly addresses this challenge by enabling intelligent, adaptive sampling of the materials space based on the uncertainties and predictions of a surrogate model [30] [31]. This paradigm shift from traditional high-throughput screening to an informed, sequential decision-making process is what allows autonomous laboratories to rapidly converge on materials with targeted properties, such as enhanced anomalous Hall effect or specific optoelectronic characteristics [4] [30].
Core Concepts: Active Learning for Data Interpretation
Active learning is a supervised machine learning approach in which the algorithm proactively selects the most informative data points from a pool of unlabeled data to be labeled by an oracle, typically a human expert or a high-fidelity simulation [32] [33]. The core premise is that an machine learning model can achieve higher accuracy with fewer training labels if it is allowed to choose the data from which it learns [32]. This makes it exceptionally powerful for materials science applications, where obtaining labeled data—through either complex simulations or resource-intensive experiments—is often the primary bottleneck [30].
Active learning operates through an iterative loop that can be summarized in three key stages [31]:
- Model Training: An initial model is trained on a small, labeled dataset.
- Query Selection: The model identifies the most valuable or informative unlabeled data points from the available pool.
- Data Annotation & Model Update: The selected data points are labeled (e.g., through an experiment or calculation) and added to the training set. The model is then retrained on the augmented dataset [33].
This process is distinct from passive supervised learning, where the model is trained on a static, pre-defined dataset. The key difference lies in the selective and interactive nature of data acquisition, which significantly reduces labeling costs and improves model performance and convergence [33].
Active Learning Query Strategies and Methodologies
The "query strategy" is the decision-making engine of an active learning system. It determines which unlabeled instances are most valuable for improving the model. Different strategies are suited to different problem structures and data types.
Table 1: Active Learning Query Strategies
| Strategy | Core Principle | Applicability in Materials Science |
|---|---|---|
| Uncertainty Sampling [31] [33] | Selects data points where the model's prediction confidence is lowest (e.g., closest to a decision boundary). | Ideal for refining models when the property landscape is complex and the goal is to pinpoint compositions or conditions with specific characteristics. |
| Query-by-Committee (QBC) [31] | Utilizes an ensemble (committee) of models; selects data points where committee members disagree the most. | Reduces model bias and is useful when multiple surrogate models or physical theories exist for a property. |
| Expected Model Change [31] | Selects data points that are expected to induce the largest change (e.g., in gradients) to the current model. | Aims for maximum learning efficiency per experiment, valuable when each new data point is computationally or experimentally very costly. |
| Diversity Sampling [31] [33] | Selects a diverse set of data points to ensure broad coverage of the feature space and avoid overfitting. | Crucial for the initial exploration stages of a new materials system to build a robust and general model. |
| Stream-Based Selective Sampling [32] [33] | Evaluates each incoming data instance one-at-a-time and immediately decides whether to query its label. | Less common in materials science, but could be applied to real-time, continuous data streams from certain characterization tools. |
| Pool-Based Sampling [32] | The algorithm evaluates the entire pool of unlabeled data to select the best queries, often in batches. | The most prevalent scenario in materials informatics, where a large virtual library of candidate compositions or structures exists [30]. |
| Membership Query Synthesis [32] | The active learner generates its own synthetic data instances for labeling. | Applicable where it is easy to generate valid, realistic data instances, such as generating new molecular structures within defined chemical rules. |
Bayesian Optimization as a Utility-Driven Strategy
Beyond the standard query strategies, Bayesian Optimization (BO) represents a powerful framework for global optimization of black-box functions that are expensive to evaluate, making it exceptionally well-suited for guiding materials experiments [30]. In the context of active learning, BO uses a surrogate model, typically a Gaussian Process (GP), to model the target property (e.g., anomalous Hall resistivity) across the search space. It then uses an acquisition function to decide the next experiment by balancing exploration (probing uncertain regions) and exploitation (probing regions predicted to be high-performing) [4] [30].
The general workflow for a BO-driven experiment is:
- Surrogate Modeling: A Gaussian Process is used to build a probabilistic surrogate model from the currently available data.
- Acquisition Maximization: An acquisition function (e.g., Expected Improvement, Upper Confidence Bound), which quantizes the utility of performing an experiment at a given point, is maximized to propose the next experimental condition.
- Experiment and Update: The proposed experiment is conducted, the new data point is added to the training set, and the GP model is updated.
This approach has been successfully demonstrated in autonomous closed-loop exploration, such as the optimization of five-element alloy composition-spread films to maximize the anomalous Hall effect [4].
Table 2: Common Acquisition Functions in Bayesian Optimization
| Acquisition Function | Formula (Simplified) | Behavior |
|---|---|---|
| Expected Improvement (EI) [30] | ( EI(\mathbf{x}) = \mathbb{E}[\max(f(\mathbf{x}) - f(\mathbf{x}^+), 0)] ) | Selects points offering the highest expected improvement over the current best observation ( f(\mathbf{x}^+) ). |
| Upper Confidence Bound (UCB) | ( UCB(\mathbf{x}) = \mu(\mathbf{x}) + \kappa \sigma(\mathbf{x}) ) | Selects points based on a weighted sum of the predicted mean ( \mu(\mathbf{x}) ) and uncertainty ( \sigma(\mathbf{x}) ). The parameter ( \kappa ) controls the exploration-exploitation trade-off. |
| Probability of Improvement (PI) | ( PI(\mathbf{x}) = P(f(\mathbf{x}) \geq f(\mathbf{x}^+) + \xi) ) | Selects points with the highest probability of exceeding the current best by a margin ( \xi ). |
Experimental Protocols for Autonomous Materials Discovery
The following section details a specific implementation of an active learning-driven closed loop for materials discovery, as demonstrated in the autonomous exploration of composition-spread films.
Protocol: Bayesian Optimization of Five-Element Alloy Films for Anomalous Hall Effect
This protocol details the closed-loop experimentation from [4].
1. Objective: Maximize the anomalous Hall resistivity (( \rho_{yx}^{A} )) of a five-element alloy system at room temperature. The system consists of three 3d ferromagnetic elements (Fe, Co, Ni) and two 5d heavy elements selected from Ta, W, or Ir.
2. Initialization and Candidate Pool:
- A candidate pool of 18,594 possible compositions was generated algorithmically. Fe, Co, and Ni were constrained to 10-70 at.% each, with their total between 70-95 at.%. The two heavy metals were constrained to 1-29 at.% each, with their total making up the remaining 5-30 at.% [4].
- This pool was stored in a
candidates.csvfile for the Bayesian optimization algorithm to query.
3. Autonomous Closed-Loop Workflow: The loop involves a sequence of automated steps orchestrated by specialized software (NIMS orchestration system - NIMO) [4]:
- Step 1 - Proposal Generation: The Bayesian optimization algorithm (PHYSBO) selects the most promising composition-spread film to fabricate next. It chooses two elements to be compositionally graded (e.g., Ni and Co) while fixing the others, and proposes
Lcompositions with different mixing ratios of these two elements at equal intervals [4]. - Step 2 - Automated Deposition: An input recipe file for the combinatorial sputtering system is automatically generated. The composition-spread film is deposited on a SiO2/Si substrate at room temperature (duration: ~1–2 hours) [4].
- Step 3 - Automated Device Fabrication: The deposited film is transferred to a laser patterning system, which fabricates 13 devices without photoresist (duration: ~1.5 hours) [4].
- Step 4 - Automated Characterization: The devices are transferred to a customized multichannel probe for simultaneous measurement of the anomalous Hall effect at room temperature (duration: ~0.2 hours) [4].
- Step 5 - Automated Data Analysis: A Python program automatically analyzes the raw measurement data to calculate the anomalous Hall resistivity (( \rho_{yx}^{A} )) for each of the 13 measured compositions [4].
- Step 6 - Data Assimilation: The new composition-property data is automatically added to the
candidates.csvfile, and the Bayesian optimization model is updated. The loop returns to Step 1 [4].
4. Outcome: After multiple cycles, this autonomous process discovered an Fe44.9Co27.9Ni12.1Ta3.3Ir11.7 amorphous thin film with a high anomalous Hall resistivity of 10.9 µΩ cm [4].
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials and Tools for Autonomous Combinatorial Experimentation
| Item / Solution | Function / Role in the Workflow |
|---|---|
| Combinatorial Sputtering System | Enables the deposition of composition-spread films, where the elemental composition varies continuously across a single substrate, creating a library of compounds in one experiment [4]. |
| 5d Heavy Metal Targets (Ta, W, Ir) | Used as sputtering targets. Adding these heavy elements to 3d ferromagnetic alloys (Fe, Co, Ni) can significantly enhance spin-orbit coupling, a key factor for achieving a large anomalous Hall effect [4]. |
| SiO2/Si Substrates | The substrate on which the thin-film materials are deposited. Using an amorphous surface (SiO2) and room-temperature deposition demonstrates the potential for direct integration into practical devices [4]. |
| Laser Patterning System | Provides a photoresist-free method for rapidly fabricating multiple micro-devices (e.g., 13 devices in ~1.5 hours) from the composition-spread film for electrical measurement [4]. |
| Multi-Channel Probe Station | A customized measurement system that allows for the simultaneous electrical characterization of multiple devices, drastically reducing the time required for data collection [4]. |
| Orchestration Software (NIMO) | The central software "brain" that controls the autonomous closed-loop operation, integrating the Bayesian optimization, instrument control, and data analysis modules [4]. |
| Bayesian Optimization Library (PHYSBO) | A specialized Python library for physics-based Bayesian optimization, used here to power the decision-making process for selecting the next experiment [4]. |
Visualization of the Active Learning Workflow
The following diagram illustrates the core active learning feedback loop that forms the 'Analyze' phase within an autonomous laboratory, integrating the computational and experimental components.
Impact and Future Directions
The integration of active learning within autonomous laboratories represents a paradigm shift in materials and drug discovery. By moving beyond brute-force screening to a principled, iterative learning process, researchers can dramatically reduce the time and cost associated with discovering new materials with targeted properties [30] [34]. The successful demonstration of closed-loop systems that autonomously discover materials with enhanced performance, such as the five-element alloy for the anomalous Hall effect, underscores the practical viability of this approach [4].
Future developments in this field are likely to focus on several key areas:
- Multi-fidelity and Multi-objective Optimization: Developing active learning strategies that can intelligently integrate data from computational models of varying accuracy (e.g., from force fields to DFT) and balance competing material objectives (e.g., efficiency vs. stability) [30].
- Integration of Large Language Models (LLMs): Using LLMs to assist in developing control software for instruments, thereby democratizing and accelerating the setup of autonomous experimentation platforms [34].
- Advanced Surrogate Models: Moving beyond Gaussian Processes to incorporate more complex models, including deep learning and physics-informed neural networks, to better capture the underlying phenomena in materials science [30].
The 'Analyze' phase, powered by active learning, is thus not merely a data processing step but the central decision-making engine that enables the autonomous and accelerated realization of novel materials.
The discovery and synthesis of novel inorganic materials are critical for advancing technologies in clean energy, electronics, and sustainable chemistry. However, a significant gap persists between the rate at which new materials can be computationally predicted and the slow, labor-intensive process of their experimental realization [6]. To bridge this gap, autonomous laboratories represent a paradigm shift in materials research. These self-driving labs integrate artificial intelligence (AI), robotics, and rich sources of background knowledge to automate the discovery process. The A-Lab, developed and demonstrated in a landmark 2023 study, stands as a pioneering example of such a system [6]. This case study examines the A-Lab's operation, its success in synthesizing novel inorganic powders, and its implications for the future of materials research within the broader context of closed-loop autonomous discovery.
The Autonomous Discovery Workflow
The A-Lab operates through a sophisticated, closed-loop pipeline that integrates computational prediction, AI-driven planning, robotic execution, and intelligent analysis. This workflow transforms the traditional, linear research process into an iterative, self-correcting cycle of discovery [6].
Core Workflow Diagram
The following diagram illustrates the integrated, closed-loop process that enables the A-Lab's autonomous discovery of novel materials.
Workflow Stage Details
- Target Identification: The process begins with a set of target compounds identified through large-scale ab initio phase-stability data from the Materials Project and Google DeepMind. These targets are predicted to be stable or near-stable (within 10 meV per atom of the convex hull) and air-stable, ensuring compatibility with the A-Lab's open-air environment [6].
- AI-Driven Recipe Generation: For each target, the system generates initial synthesis recipes using a natural-language model trained on a vast database of historical synthesis literature. This model assesses "target similarity" to identify effective precursor combinations, mimicking a human researcher's approach [6]. A second ML model, trained on heating data from the literature, proposes synthesis temperatures [6].
- Robotic Synthesis and Characterization: Robotic arms handle the entire experimental process. A preparation station dispenses and mixes precursor powders into crucibles. Another robotic arm loads these into one of four box furnaces. After heating and cooling, a final arm transfers the sample to a characterization station, where it is ground and measured by X-ray diffraction (XRD) [6].
- Intelligent Analysis and Active Learning: The XRD patterns are analyzed by probabilistic ML models to identify phases and determine target yield. If the yield is below 50%, the loop closes. The system uses an active learning algorithm called ARROWS3 (Autonomous Reaction Route Optimization with Solid-State Synthesis), which integrates computed reaction energies with observed experimental outcomes to propose improved recipes, thus initiating a new cycle of experimentation [6].
Methodology & Experimental Protocols
The A-Lab's methodology is distinguished by its fusion of computational data, historical knowledge, and active learning, all executed with robotic precision.
Bayesian Optimization for Combinatorial Experimentation
A key methodological advancement in autonomous experimentation is the development of specialized optimization algorithms. In related high-throughput work on composition-spread films, researchers developed a Bayesian optimization method specifically designed for combinatorial studies. This algorithm, implemented using the PHYSBO library, selects which elements to compositionally grade and identifies promising composition spreads to maximize a target property, such as the anomalous Hall effect [4]. The process involves scoring possible element pairs by averaging the acquisition function values across multiple compositions, thereby guiding the efficient exploration of complex multi-element spaces [4].
Data Intensification Strategies
A recent breakthrough in self-driving labs involves a shift from steady-state flow experiments to dynamic flow experiments. In this approach, chemical mixtures are continuously varied and monitored in real-time, capturing data every half-second. This "streaming-data" approach generates at least an order-of-magnitude more data than conventional methods, allowing the machine-learning algorithm to make smarter, faster decisions and drastically reduce both time and chemical consumption during discovery and optimization [35].
Key Research Reagents and Materials
The A-Lab and similar platforms rely on a suite of core reagents and instruments to function. The table below details these essential components.
Table 1: Essential Research Reagents and Materials for Autonomous Materials Discovery
| Item/Component | Function/Role in the Experimental Process |
|---|---|
| Precursor Powders | High-purity solid powders serve as starting materials for solid-state reactions. Their selection is initially guided by literature-mined similarity [6]. |
| Alumina Crucibles | Contain precursor powders during high-temperature synthesis in box furnaces [6]. |
| Combinatorial Sputtering System | In thin-film studies, this system fabricates composition-spread films with varying elemental ratios on a single substrate [4]. |
| Box Furnaces | Provide the controlled high-temperature environment required for solid-state reactions to occur [6]. |
| X-ray Diffractometer (XRD) | The primary characterization tool used to identify the crystalline phases present in a synthesized powder and determine their weight fractions [6]. |
| In-situ Sensors (e.g., for Optical Emission) | In fluidic self-driving labs, these provide real-time feedback on reaction conditions, enabling dynamic flow experiments and data intensification [35]. |
Results and Performance Analysis
Over 17 days of continuous operation, the A-Lab successfully synthesized 41 out of 58 novel inorganic target compounds, achieving a 71% success rate [6]. This high yield demonstrates the effectiveness of integrating computation, historical data, and robotics.
Synthesis Outcomes and Failure Analysis
The experimental outcomes provide deep insight into the factors influencing synthesizability.
Table 2: A-Lab Experimental Outcomes and Failure Analysis
| Metric | Result | Implication |
|---|---|---|
| Total Targets | 58 | Compounds from 33 elements and 41 structural prototypes [6]. |
| Successfully Synthesized | 41 | 71% success rate for first attempts on novel compounds [6]. |
| Obtained via Literature Recipes | 35 | Confirms the utility of historical data and target-similarity metrics [6]. |
| Optimized via Active Learning (ARROWS3) | 6 | Active learning successfully rescued targets with initial zero yield [6]. |
| Primary Failure Mode (Sluggish Kinetics) | 11 of 17 failures | Reactions with low driving forces (<50 meV/atom) were kinetically stalled [6]. |
| Potential Improved Success Rate | Up to 78% | Achievable with minor tweaks to decision-making and computational data [6]. |
The Role of Active Learning
The ARROWS3 algorithm enhanced synthesis by leveraging two key hypotheses: 1) solid-state reactions often proceed through pairwise intermediates, and 2) intermediates with a small driving force to form the target should be avoided. By building a database of observed pairwise reactions, the A-Lab could intelligently prune its search space and prioritize reaction pathways with larger driving forces, leading to successful synthesis of otherwise elusive targets [6].
The A-Lab represents a transformative advance in materials science. By successfully integrating computational screening, AI-powered reasoning rooted in historical data, robotic automation, and active learning in a closed-loop system, it dramatically accelerates the discovery of novel, functional materials. Its demonstrated success in synthesizing the majority of its target compounds validates the stability predictions of large-scale ab initio databases and proves the viability of fully autonomous research platforms. The lessons learned from its failure modes offer clear, actionable paths for improving both computational and experimental techniques. As the underlying technologies—from Bayesian optimization for combinatorial spaces [4] to data-intensifying dynamic flow systems [35]—continue to mature, the vision of self-driving laboratories discovering materials for pressing global challenges in days rather than years is rapidly becoming a reality.
The discovery of novel functional molecules and peptides is undergoing a revolutionary transformation, moving from traditional, labor-intensive processes to AI-driven, automated workflows. This paradigm shift is epitomized by the development of closed-loop autonomous laboratories, which integrate artificial intelligence, robotics, and high-throughput experimentation to accelerate discovery at an unprecedented scale. These systems are capable of designing, executing, and analyzing thousands of experiments in real-time with minimal human intervention, compressing discovery timelines from years to weeks [28] [27]. This case study examines the technical architecture and experimental protocols underpinning this new paradigm, with a specific focus on its application in discovering and optimizing peptide-based therapeutics and functional materials. The convergence of machine learning-guided molecular design and autonomous physical validation represents a fundamental advancement in research methodology, enabling the systematic exploration of chemical spaces that were previously inaccessible [36] [37].
Core Technologies and Methodologies
AI-Driven Molecular Design and Optimization
At the heart of accelerated discovery are advanced machine learning models that generate and prioritize molecular candidates. Two complementary approaches have demonstrated significant success:
Denoising Diffusion Models for Peptide Design: Researchers have successfully applied Denoising Diffusion Implicit Models (DDIMs) to mRNA display library data to generate novel peptide ligands against specific protein targets. In a case study targeting B-cell lymphoma extra-large (Bcl-xL), a key cancer target, this approach generated functionally equivalent sequences with comparable binding kinetics and affinity to wildtype peptides. Crucially, the model produced rare sequences not easily accessible through traditional mutation or directed evolution, efficiently exploring underrepresented regions of sequence space [36].
Machine Learning-Guided Peptide Optimization: Platforms like Gubra's streaMLine integrate high-throughput data generation with advanced AI models to guide candidate selection. This system simultaneously optimizes for multiple drug-like properties including potency, selectivity, and stability. In one application focused on developing GLP-1 receptor agonists based on a secretin backbone, AI-driven substitutions enhanced receptor selectivity while abolishing off-target effects, and modifications improved solubility and reduced aggregation. Subsequent in vivo studies demonstrated potent weight-loss effects in diet-induced obese mice and a pharmacokinetic profile compatible with once-weekly dosing [37].
Autonomous Experimentation Systems
The digital design of molecules must be validated through physical experimentation. Self-driving laboratories (SDLs) close this loop by automating the entire experimental workflow:
System Architecture: The MAMA BEAR (Bayesian Experimental Autonomous Researcher) system at Boston University exemplifies this approach, having conducted over 25,000 experiments with minimal human oversight. The system achieved a record-breaking 75.2% energy absorption – the most efficient energy-absorbing material discovered to date, with significant implications for helmet padding and protective packaging [28].
Community-Driven Platforms: Next-generation SDLs are evolving from isolated, lab-centric tools into shared, community-driven experimental platforms. These systems enable external researchers to design experiments, submit requests, and explore data through public-facing interfaces. Pilot initiatives have included developing large language model-based agents that help users navigate experimental datasets and propose new experiments using retrieval-augmented generation (RAG) techniques [28].
Late-Stage Molecular Reshaping
Advanced chemical techniques enable the structural refinement of molecules after initial selection, dramatically expanding chemical diversity:
Peptide Reshaping Strategy: Scientists at 48Hour Discovery have developed a powerful method for late-stage peptide reshaping that efficiently converts macrocyclic peptides into bicyclic structures using a C₂-symmetric linchpin KYL. This approach bridges phage display and chemical modification, overcoming limitations of traditional display techniques [38].
Functional Payload Installation: Beyond cyclization, this methodology enables the late-stage installation of chelators, linkers, and other functional payloads to fine-tune peptide properties for imaging, targeted delivery, and therapeutic performance. The entire reshaping process requires only two days of hands-on work, making it one of the most efficient techniques for refining peptide therapeutics [38].
Experimental Protocols and Workflows
AI-Augmented Peptide Discovery Protocol
AI-Powered Peptide Discovery Workflow
The integrated workflow for AI-augmented peptide discovery involves a tightly-coupled cycle of computational design and experimental validation:
Library Construction and Selection: Begin with an initial physical library (e.g., mRNA display) against the target of interest. Perform several rounds of selection to enrich for binders [36].
High-Throughput Sequencing: Sequence the enriched library populations using next-generation sequencing to obtain comprehensive sequence-function data [36].
AI Model Training: Train denoising diffusion models or other generative architectures on the sequencing data. The model learns the sequence constraints and features associated with target binding [36].
In Silico Generation: Use the trained model to generate novel peptide sequences that occupy underrepresented regions of sequence space while maintaining predicted binding functionality [36].
Synthesis and Validation: Physically synthesize the top AI-generated candidates and validate their binding through experimental assays [36].
Binding Characterization: Quantitatively characterize binding kinetics and affinity using surface plasmon resonance (SPR) or similar biophysical methods. Compare against original library members and wildtype controls [36].
Data Integration and Model Refinement: Incorporate the new experimental data back into the AI model to refine its predictions and initiate another cycle of design [36].
This iterative loop typically identifies optimized lead candidates within multiple cycles, significantly faster than traditional directed evolution approaches [36].
Self-Driving Laboratory Protocol for Materials Discovery
Autonomous Materials Discovery Workflow
The operational protocol for autonomous materials discovery involves a continuous loop of hypothesis generation and testing:
Objective Definition: Clearly define the target properties and performance metrics for the desired material. For energy-absorbing materials, this might include maximizing energy absorption while maintaining specific mechanical properties [28].
AI Hypothesis Generation: Use Bayesian optimization or other machine learning algorithms to propose promising experimental conditions or material compositions based on existing data and physical principles [28] [27].
Robotic Synthesis: Automatically execute material synthesis using robotic systems. For polymers or composites, this might involve precise dispensing of precursors, controlled reaction conditions, and sample formatting [28].
Automated Characterization: Perform high-throughput characterization of the synthesized materials. This may include mechanical testing, structural analysis, thermal properties measurement, or functional performance testing [28].
Data Processing: Automatically process raw experimental data to extract relevant features and performance metrics. Convert unstructured data into structured databases amenable to machine learning [28].
Bayesian Analysis: Update the machine learning model with new experimental results. Calculate the posterior distribution and uncertainty estimates across the design space [28].
Next-Experiment Selection: Use acquisition functions to determine the most informative next experiments, balancing exploration of uncertain regions with exploitation of promising areas [28].
This autonomous loop continues until performance targets are met or the experimental budget is exhausted, typically achieving optimal conditions within hundreds to thousands of iterations rather than the years required for manual approaches [28].
Quantitative Performance Data
Comparative Performance of Discovery Platforms
Table 1: Performance Metrics of Accelerated Discovery Platforms
| Platform/Method | Traditional Timeline | Accelerated Timeline | Throughput (Experiments) | Key Performance Metrics |
|---|---|---|---|---|
| AI-Guided Peptide Discovery [36] [37] | 6-12 months | 2-4 weeks | N/A (Generative) | Generated sequences with equivalent binding affinity (KD < 10 nM); Improved selectivity and stability |
| Self-Driving Labs (MAMA BEAR) [28] | 2-5 years | 3-6 months | 25,000+ | Achieved 75.2% energy absorption; Discovered structures with 55 J/g absorption (2x previous benchmark) |
| Late-Stage Peptide Reshaping [38] | Weeks for optimization | 2 days hands-on | N/A | Efficient conversion to bicyclic peptides; Retained/enhanced binding after structural modification |
| Community-Driven SDL Platform [28] | Limited access | Real-time collaboration | 89+ dataset downloads | External algorithm testing doubled energy absorption benchmarks |
AI-Generated Peptide Binding Performance
Table 2: Experimental Validation of AI-Designed Peptides
| Peptide Source | Target Protein | Binding Affinity (KD) | Selectivity | Stability | Functional Activity |
|---|---|---|---|---|---|
| AI-Generated Sequences [36] | Bcl-xL | Comparable to wildtype | Equivalent to original | N/A | Functionally equivalent to original library members |
| streaMLine-Optimized GLP-1R Agonist [37] | GLP-1 Receptor | High potency | Enhanced receptor specificity | Reduced aggregation; Improved solubility | Potent weight-loss in DIO mice; Once-weekly PK profile |
| Late-Stage Reshaped Bicyclic Peptides [38] | Various targets | Retained or enhanced after reshaping | Maintained or improved | Structural diversity | Binding properties confirmed post-reshaping |
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key Research Reagents and Platforms for Accelerated Discovery
| Reagent/Platform | Function | Application in Workflow |
|---|---|---|
| mRNA Display Libraries [36] | In vitro selection technology presenting peptide libraries as mRNA-peptide fusions | Initial library construction and selection against targets |
| Denoising Diffusion Implicit Models (DDIMs) [36] | Generative AI architecture for creating novel sequences | Learning from sequencing data to generate new functional peptides |
| C₂-Symmetric Linchpin KYL [38] | Chemical reagent for structural conversion | Late-stage reshaping of macrocyclic peptides into bicyclic structures |
| streaMLine Platform [37] | Integrated AI and high-throughput experimentation | Parallel optimization of potency, selectivity, and stability |
| Bayesian Optimization Algorithms [28] | Machine learning for experimental design | Selecting the most informative next experiments in self-driving labs |
| AlphaFold & ProteinMPNN [37] | Structure prediction and sequence design tools | De novo peptide design compatible with target 3D structures |
| Autonomous Robotic Systems [28] [27] | Robotic instrumentation for hands-off experimentation | Executing synthesis and characterization in self-driving labs |
| Phage Display Platforms [38] | Biological selection technology | Initial peptide discovery before chemical reshaping |
The case studies presented demonstrate that accelerated discovery of functional molecules and peptides through closed-loop autonomous laboratories is producing quantitatively superior results in fractions of the time required by traditional methods. The integration of AI-driven design with autonomous experimentation has created a new paradigm where discovery iteration cycles are compressed from months to days, and vast regions of chemical space can be systematically explored [36] [28] [27].
Looking forward, several trends are poised to further accelerate this field. The evolution of self-driving labs from isolated instruments to community resources promises to democratize access to autonomous experimentation [28]. Initiatives like the NSF Artificial Intelligence Materials Institute (AI-MI) aim to create open, cloud-based portals coupling science-ready large language models with targeted data streams [28]. As these platforms become more sophisticated and accessible, they will likely transform not only how we discover new molecules and materials, but also how scientific knowledge is created and shared across the research community. The convergence of human expertise with autonomous AI-driven discovery systems represents the future of scientific innovation, enabling researchers to tackle increasingly complex challenges in therapeutics, materials science, and beyond.
Overcoming Synthesis Barriers: Troubleshooting and Optimizing SDL Performance
In the pursuit of accelerated materials discovery, closed-loop autonomous laboratories represent a paradigm shift, integrating robotics, artificial intelligence (AI), and high-throughput computation to navigate the complex landscape of synthesis. The A-Lab, an autonomous laboratory for solid-state synthesis, exemplifies this approach by leveraging computations, historical data, machine learning, and active learning to plan and interpret experiments [6]. However, the path to novel materials is fraught with failure. Effectively identifying, understanding, and mitigating common failure modes is not merely a corrective task; it is a fundamental mechanism for learning and optimization within an autonomous research framework.
This guide examines three critical failure modes—kinetic stagnation, volatility-driven decomposition, and undesirable amorphization—within the context of autonomous materials discovery. We dissect their root causes, present methodologies for their experimental identification, and frame their management as an integral part of the autonomous loop, where each failure informs subsequent computational and experimental decisions.
Failure Mode Analysis: Causes, Identification, and Protocols
A systematic understanding of failure modes enables proactive design of experiments and robust autonomous decision-making. The following sections provide a detailed analysis of three predominant categories.
Table 1: Summary of Key Failure Modes in Solid-State Synthesis
| Failure Mode | Primary Cause | Key Identification Technique | Characteristic Signature |
|---|---|---|---|
| Slow Reaction Kinetics | Low driving force for solid-state reaction (<50 meV/atom) [6] | X-ray Diffraction (XRD) with Rietveld refinement [6] | Target phase weight fraction <50% after heating; persistence of precursor phases [6] |
| Precursor Volatility | Vaporization of precursor components at synthesis temperature | Post-experiment mass balance calculation; elemental analysis | Mass loss in crucible; non-stoichiometry in the final product [6] |
| Undesirable Amorphization | Mechanical instability under high shear stress or deformation [39] | Transmission Electron Microscopy (TEM) & Selected-Area Electron Diffraction (SAED) [40] | Diffuse halo patterns in SAED; lack of long-range crystalline order in TEM [40] |
| Shear Band Dominated Failure | Localized plastic deformation in alloys [40] | In-situ mechanical compression; electron microscopy | Localized shear bands leading to microcracks and catastrophic fracture [40] |
Kinetic Stagnation
Root Cause: Kinetic stagnation occurs when the energy barrier for atomic rearrangement into the target crystal structure is too high to be overcome within the experimental time and temperature constraints. In solid-state synthesis, this is often linked to reaction steps with a low thermodynamic driving force, specifically a computed energy difference of less than 50 meV per atom between intermediates and the target phase [6]. This small driving force results in exceedingly slow reaction rates, causing the system to reside in metastable intermediate states indefinitely.
Experimental Identification Protocol:
- Synthesis: Execute the proposed solid-state reaction recipe using the automated powder handling and furnace systems.
- Characterization: Transfer the resulting powder to an X-ray diffractometer for analysis.
- Phase Analysis: Employ machine learning models trained on experimental and computed structures to identify phases present in the XRD pattern [6].
- Quantification: Perform automated Rietveld refinement on the XRD pattern to determine the weight fraction of the target phase and all intermediate phases [6].
- Diagnosis: A synthesis is classified as a kinetic failure if the weight fraction of the target phase is below a pre-defined threshold (e.g., 50%) and significant amounts of precursor or intermediate phases remain [6].
Autonomous Mitigation Strategy: The A-Lab utilizes an active-learning algorithm termed ARROWS3 (Autonomous Reaction Route Optimization with Solid-State Synthesis). This system builds a database of observed pairwise solid-state reactions from its experiments [6]. When kinetic failure is detected, the algorithm:
- Avoids Low-Driving-Force Intermediates: It identifies and excludes synthesis pathways that lead to intermediates with a small driving force (<50 meV/atom) to form the target.
- Prioritizes High-Driving-Force Pathways: It proposes alternative precursor sets or intermediates that have a larger computed driving force (e.g., >70 meV per atom) to form the target, thereby accelerating the reaction kinetics [6].
Volatility-Driven Failure
Root Cause: This failure mode arises from the vaporization of one or more precursor elements during high-temperature heating. This loss disrupts the precise stoichiometry required to form the target compound, leading to the formation of incorrect, impurity-stabilized, or incomplete phases.
Experimental Identification Protocol:
- Mass Measurement: Precisely measure the mass of the precursor mixture before reaction using an automated dispensing system.
- Post-Reaction Mass Analysis: Accurately measure the mass of the final product after the synthesis cycle is complete.
- Stoichiometric Verification: Perform elemental analysis (e.g., via X-ray fluorescence or inductively coupled plasma spectroscopy) on the final product to determine its elemental composition.
- Diagnosis: A significant mass loss between the initial precursor mix and the final product, coupled with a non-stoichiometric elemental composition in the final product, confirms a volatility-driven failure [6].
Autonomous Mitigation Strategy: The autonomous system can respond by:
- Precursor Substitution: Replacing the volatile precursor with a more thermally stable compound containing the same target element.
- Process Modification: Switching from a single-step heating profile to a two-step process involving a low-temperature pre-reaction to form a stable intermediate, followed by a high-temperature treatment.
- Atmosphere Control: Performing the synthesis in a sealed capsule or under an overpressure of an inert gas to suppress vaporization.
Undesirable Amorphization and Shear Localization
Root Cause: In metallic systems and under high-stress conditions, failure can occur through the formation of shear bands—highly localized regions of intense plastic deformation [40]. Within these bands, severe lattice distortion can lead to deformation-induced amorphization, where the crystalline structure collapses into a disordered, amorphous state [39]. This mechanism is distinct from melt-quenching and is driven by mechanical instability, often facilitated by a top-down dislocation gradient under high strain-rate loading [40].
Experimental Identification Protocol:
- Mechanical Testing: Deform a micropillar of the material using in-situ uniaxial compression across a range of strain rates.
- Structural Interrogation: Section the deformed micropillar using a focused ion beam (FIB) and analyze its microstructure via double spherical aberration-corrected transmission electron microscopy (DC-TEM).
- Crystallographic Analysis: Acquire Selected-Area Electron Diffraction (SAED) patterns from the deformed region.
- Diagnosis: The presence of diffuse halo rings in the SAED pattern, instead of sharp diffraction spots or rings, confirms an amorphous structure. TEM imaging will show a lack of long-range periodicity, and the material may exhibit "hyper-range amorphization" bands extending micrometers in length [40].
Autonomous Mitigation Strategy: For autonomous labs focused on synthesis, the strategy involves refining processing parameters to enhance crystallinity. For labs studying mechanical properties, a strategy inspired by recent research is Strain-Training:
- Protocol: Apply continuous compression loading to the material across multiple, progressively higher strain rates (from ~8×10⁻⁴ s⁻¹ to ~2×10⁻² s⁻¹) [40].
- Outcome: This process generates a high-density dislocation gradient that can trigger the formation of a widespread, "hyper-range" amorphous network. This network fundamentally replaces the shear-dominated failure mechanism, dissipating stress and leading to a superior combination of strength and plasticity [40].
The Autonomous Laboratory Workflow for Failure Analysis
In a closed-loop autonomous laboratory, the identification and analysis of failure are not endpoints but feedback signals that drive the iterative discovery process. The entire workflow, from target selection to failure-informed resynthesis, can be integrated into a seamless, AI-driven operation.
Diagram 1: Autonomous failure analysis workflow.
The workflow, as illustrated in Diagram 1, creates a self-improving research cycle. Failures are systematically categorized, and their characteristics are fed back into the AI models that plan experiments. For instance, the A-Lab used this approach to successfully synthesize 41 out of 58 novel compounds, with the analysis of the 17 failures providing direct, actionable suggestions for improving both computational screening and synthesis design [6].
The Scientist's Toolkit: Essential Research Reagents & Materials
The experimental protocols and autonomous laboratories discussed rely on a suite of essential materials and instruments. The following table details key components of this toolkit.
Table 2: Key Research Reagents and Materials for Autonomous Synthesis and Failure Analysis
| Item | Function / Rationale | Example Application |
|---|---|---|
| Inorganic Powder Precursors | High-purity (>99%) starting materials for solid-state reactions. Precursor selection is critical and often guided by ML models analyzing historical literature [6]. | Synthesis of novel oxide and phosphate materials in the A-Lab [6]. |
| Alumina Crucibles | Chemically inert containers for high-temperature reactions, compatible with automated robotic handling. | Holding powder mixtures during heating in box furnaces [6]. |
| Multi-principal Element Alloys (MPEAs) | Model material systems with complex deformation mechanics, ideal for studying shear banding and amorphization. | Micropillar compression tests to investigate hyper-range amorphization [40]. |
| Focused Ion Beam (FIB) | A precision instrument for site-specific milling, ablation, and deposition of materials, crucial for creating samples for TEM. | Fabrication of 〈111〉-oriented FCC micropillars from eutectic MPEA clusters [40]. |
| Spherical Aberration-Corrected TEM (DC-TEM) | Advanced microscopy providing atomic-resolution imaging and diffraction to definitively identify amorphous phases and crystal defects. | Observing hyper-range amorphization bands and associated dislocation gradients [40]. |
| VIX Futures & Short Volatility ETPs | (As a financial analogy) Financial instruments that sell market insurance. Their failure modes (e.g., during "Volmageddon") illustrate the risks of concentrated, leveraged positions and negative feedback loops, analogous to material instability [41] [42]. | Analyzing the impact of hedge rebalancing and market crowding on product collapse [42]. |
The integration of failure mode analysis into the core operation of autonomous laboratories is transformative. By treating failures not as dead ends but as rich sources of data, systems like the A-Lab can close the loop between prediction, experimentation, and validation. A deep technical understanding of kinetic, volatile, and amorphic failure mechanisms provides the necessary lexicon for this process. As these autonomous platforms continue to evolve, the systematic encoding of failure will undoubtedly accelerate the reliable discovery of next-generation materials, turning the once-serendipitous process of research into a disciplined, predictive, and continuously self-optimizing engineering science.
The Role of Active Learning and Bayesian Optimization in Route Correction
In the pursuit of novel materials for applications ranging from high-temperature gas turbine engines to phase-change memory devices, researchers face an exponentially vast and complex design space. The traditional Edisonian approach of iterative experimentation is prohibitively costly and time-consuming within this landscape. Active Learning and Bayesian Optimization have emerged as core computational pillars enabling a new paradigm: the closed-loop autonomous laboratory [43] [44]. These systems are capable of "route correction"—intelligently adapting their experimental strategy based on incoming data to efficiently navigate the multi-dimensional search space of materials science. This technical guide details the synergy of these methods within autonomous research platforms, providing the frameworks and methodologies driving the next wave of materials innovation.
Theoretical Foundations
Active Learning in Scientific Discovery
Active learning is a subfield of machine learning dedicated to optimal experiment design. In a scientific context, it formalizes the process of selecting the most informative experiments to perform to achieve a user-defined objective with minimal resource expenditure [45].
The process forms a cyclic loop, as illustrated in the diagram below:
Active Learning Workflow. The closed-loop cycle of an active learning system for scientific discovery.
This loop begins with an initial dataset used to train a predictive model. The model then generates predictions and, crucially, quantifies its uncertainty across the design space. An acquisition function uses this information to propose the most informative subsequent experiment (the "query"). After the experiment is executed, the new data is used to update the model, and the cycle repeats [45] [46]. This approach allows the system to "fail smarter, learn faster, and spend less resources" [43].
Bayesian Optimization for Expensive Black-Box Functions
Bayesian Optimization is a powerful instantiation of the active learning principle, designed for optimizing functions that are expensive to evaluate and whose analytical form is unknown (i.e., "black-box" functions) [46]. The core components of BO are:
- A surrogate model, typically a Gaussian Process, which probabilistically approximates the unknown objective function and provides an estimate of uncertainty at any point in the design space.
- An acquisition function, which leverages the surrogate's predictions to balance exploration (probing regions of high uncertainty) and exploitation (converging toward known high-performance regions) by selecting the next point to evaluate.
The fundamental challenge BO addresses is the exploration-exploitation trade-off. Traditional acquisition functions like Expected Improvement tend to be exploitative, while Upper Confidence Bound favors exploration [46] [47]. Advanced frameworks are emerging to create a more dynamic and efficient balance.
Integration in Closed-Loop Autonomous Laboratories
The true potential of Active Learning and BO is realized when they are embedded within a closed-loop autonomous system. In such a system, the algorithm is not merely a advisor but is in direct control of the experimental instrumentation, enabling real-time, on-the-fly route correction.
A prominent embodiment of this is the Closed-loop Autonomous Materials Exploration and Optimization (CAMEO) framework. CAMEO operates on the fundamental precept that functional property optima are often tied to specific structural phases or phase boundaries [43]. Unlike standard BO, which might treat composition space as a generic landscape, CAMEO integrates physics-informed knowledge, such as the Gibbs phase rule, to guide its search. It combines the dual objectives of learning the phase map and optimizing a target property, thereby accelerating discovery by exploiting the mutual information between structure and property [43].
This paradigm has been successfully applied to discover a novel epitaxial nanocomposite phase-change memory material in the Ge-Sb-Te ternary system, achieving a ten-fold reduction in the number of experiments required compared to conventional methods [43].
For more complex, real-world problems, materials must often satisfy multiple performance constraints (e.g., density, solidus temperature, thermal conductivity). Recent research focuses on extending BO to actively learn these unknown constraints. One approach uses classifiers to model the boundaries between feasible and infeasible regions of the design space. An entropy-based acquisition function can then prioritize experiments that most effectively reduce uncertainty about the location of these constraint boundaries, ensuring optimization occurs only within the viable region [44].
Advanced Frameworks and Quantitative Analysis
The CA-SMART Framework for Resource-Constrained Discovery
The Confidence Adjusted Surprise Measure for Active Resourceful Trials (CA-SMART) framework represents a recent advancement in Bayesian active learning [46]. It introduces the concept of "surprise"—the divergence between expected and observed outcomes—as a driver for experimentation.
- Shannon Surprise: Quantifies the unexpectedness of an observation based on its likelihood.
- Bayesian Surprise: Captures the divergence between prior and posterior beliefs.
- Confidence-Adjusted Surprise: Integrates the magnitude of surprise with the model's prior confidence, amplifying surprises in certain regions and discounting them in highly uncertain ones where observations are less reliable [46].
This approach prevents over-exploration of inherently noisy regions and optimizes the use of limited experimental resources.
Performance Comparison of Acquisition Functions
The table below summarizes a quantitative comparison of different acquisition functions and frameworks based on benchmark studies.
Table 1: Performance comparison of Bayesian optimization acquisition functions and frameworks.
| Method Name | Type | Key Principle | Reported Performance |
|---|---|---|---|
| Expected Improvement | Acquisition Function | Improves over current best known point [47]. | Exploitative; can get stuck in local optima [46]. |
| Upper Confidence Bound | Acquisition Function | Optimism in the face of uncertainty [46]. | Exploratory; can sample inefficiently in low-value regions [46]. |
| Pareto-frontier Entropy Search | Multi-Objective BO | Maximizes information gain about the Pareto front [44]. | Faster convergence than ParEGO in battery material design [44]. |
| CA-SMART | Bayesian Framework | Balances exploration-exploitation with Confidence-Adjusted Surprise [46]. | Superior accuracy & data efficiency on benchmark functions & fatigue strength prediction [46]. |
Experimental Protocol for Autonomous Materials Discovery
A typical workflow for an autonomous discovery campaign, as exemplified by CAMEO, involves the following detailed steps [43]:
- Problem Formulation: Define the design space (e.g., a ternary composition system like Ge-Sb-Te) and the target property to optimize (e.g., optical bandgap difference, ΔEg).
- Initialization: Acquire a small initial dataset, which may include prior experimental data or computational results.
- Loop Execution: a. Model Training: Train a surrogate model (e.g., Gaussian Process for properties, graph-based model for phase mapping) on the current dataset. b. Decision Making: The acquisition function (e.g., one balancing phase map knowledge and property optimization) evaluates the entire design space and selects the next composition to synthesize and characterize. c. Automated Experimentation: The system autonomously executes the recommended experiment. In the case of [43], this involved synthesizing the composition and conducting real-time X-ray diffraction and ellipsometry at a synchrotron beamline. d. Data Analysis and Route Correction: The new data is automatically analyzed (e.g., for phase identification and property measurement) and fed back into the model. The model is updated, and the loop repeats.
- Termination: The loop continues until a convergence criterion is met, such as a performance target, a exhausted experimental budget, or sufficient confidence in the identified optimum.
The Scientist's Toolkit: Research Reagents and Computational Solutions
The implementation of autonomous laboratories relies on a suite of software tools and theoretical concepts. The following table lists key "research reagents" in this context.
Table 2: Key resources for implementing active learning and Bayesian optimization in materials science.
| Resource Name / Concept | Type | Function / Application |
|---|---|---|
| Gibbs Phase Rule | Theoretical Concept | A physics-based constraint used to inform and validate probabilistic phase maps [43]. |
| Gaussian Process | Statistical Model | A surrogate model that provides predictions with uncertainty estimates for Bayesian optimization [46]. |
| Graph-based Endmember Extraction | Algorithm | Used for labeling and determining phase boundaries in composition space (e.g., in CAMEO) [43]. |
| ParBayesianOptimization | Software Library | An R package for parallelizable Bayesian optimization [47]. |
| Summit | Software Platform | A Python toolkit for applying Bayesian optimization to scientific problems across discovery, process optimization, and system tuning [47]. |
| ProcessOptimizer | Software Tool | A Python tool for optimizing real-world processes, such as DNA extraction protocols [47]. |
Workflow Visualization of an Integrated System
The diagram below synthesizes the concepts of active learning, Bayesian optimization, and materials-specific strategies into a single workflow for an autonomous materials discovery platform.
Integrated Autonomous Discovery Workflow. A system combining Bayesian optimization with materials-specific strategies like phase and constraint mapping.
Active Learning and Bayesian Optimization form the intelligent core of next-generation autonomous laboratories. By moving beyond black-box optimization to incorporate scientific knowledge—such as phase boundaries and design constraints—these systems enable efficient route correction in the complex journey of materials discovery. Frameworks like CAMEO and CA-SMART demonstrate a significant acceleration in the identification of novel, high-performing materials while dramatically reducing experimental costs. As these methodologies mature and become more accessible through specialized software, their adoption will be critical for accelerating innovation in materials science and drug development.
Leveraging Thermodynamic Data to Avoid Low-Drive-Force Intermediates
The advent of closed-loop autonomous laboratories, such as the A-Lab for inorganic powders, represents a paradigm shift in materials research, successfully synthesizing 41 of 58 novel computational targets in one demonstration [6]. However, a primary failure mode in such autonomous systems is sluggish reaction kinetics, often traced to reaction steps with low thermodynamic driving forces—specifically, those below 50 meV per atom [6]. This technical guide articulates a strategic framework for leveraging thermodynamic data to identify and circumvent these low-drive-force intermediates, thereby increasing the success rate and throughput of autonomous materials discovery platforms. By integrating computational thermodynamics with active learning, researchers can design synthesis pathways that maximize the driving force to the target material, minimizing kinetic traps and the persistence of undesired by-products.
Core Concepts: Thermodynamic Drive Force and Competition
The Minimum Thermodynamic Competition (MTC) Hypothesis
The fundamental principle for avoiding kinetic by-products is the Minimum Thermodynamic Competition (MTC) hypothesis [48]. It posits that the optimal synthesis condition is achieved when the difference in free energy between the target phase and its most thermodynamically competitive by-product phase is maximized. This is formulated as:
$$\Delta \varPhi(Y) = \varPhi{k}(Y) - \min{i \in I{c}} \varPhi{i}(Y)$$
Here, $\Delta \varPhi(Y)$ is the thermodynamic competition metric, $\varPhi{k}(Y)$ is the free energy of the desired target phase *k*, and $\min{i \in I{c}} \varPhi{i}(Y)$ is the minimum free energy among all competing phases in the index set $I_c$ [48]. The intensive variables $Y$ (e.g., pH, redox potential E, ion concentrations) define the synthesis space. The condition for minimized thermodynamic competition is found at the point $Y^*$ where $\Delta \varPhi(Y)$ is minimized, which corresponds to maximizing the energy gap to the nearest competitor [48].
The Pitfall of Low-Drive-Force Intermediates
Within a synthesis pathway, intermediates that form with a small driving force (e.g., <50 meV per atom) are particularly problematic. They represent kinetic sinks because the subsequent reaction step to form the target material also possesses a minimal driving force [6]. This results in severely sluggish kinetics, requiring prohibitively long reaction times or higher temperatures that may degrade the final product. The A-Lab's active learning algorithm, ARROWS3, was explicitly designed to avoid such intermediates, as they "often require long reaction time and high temperature" [6].
Table 1: Key Thermodynamic Metrics for Synthesis Pathway Analysis
| Metric | Definition | Interpretation for Synthesis | Optimal Condition |
|---|---|---|---|
| Decomposition Energy | Energy to form a compound from its neighbours on the phase diagram [6] | Negative value indicates thermodynamic stability at 0 K; does not always correlate with synthesizability [6] | On or very near (<10 meV/atom) the convex hull of stable phases [6] |
| Drive Force of a Reaction Step | Negative change in Gibbs free energy (-ΔG) for a specific reaction [49] | A larger positive value indicates a stronger thermodynamic driving force, favoring faster kinetics [6] | Maximized; steps with <50 meV/atom are considered high-risk for kinetic failure [6] |
| Thermodynamic Competition (ΔΦ) | Free energy difference between the target and its most competitive by-product under given conditions [48] | A more negative ΔΦ indicates a more stable target and a larger energy barrier to by-product formation [48] | Minimized (i.e., made as negative as possible) to maximize phase purity [48] |
Computational Methodologies for Drive Force Analysis
Constructing Multielement Pourbaix Diagrams
For aqueous synthesis, the Pourbaix potential ($\bar{\Psi}$) provides the free-energy surfaces needed to compute thermodynamic competition [48]. The derived Pourbaix potential is expressed as:
$$\begin{array}{l}\bar{\Psi} = \frac{1}{N{\mathrm{M}}} \left( (G - N{\mathrm{O}}{\mu}{{\mathrm{H}}{2}{\mathrm{O}}}) - RT \times \ln(10) \times (2N{\mathrm{O}} - N{\mathrm{H}})\mathrm{pH} - (2N{\mathrm{O}} - N{\mathrm{H}} + Q)E \right)\end{array}$$
Where $NM$, $NO$, and $NH$ are the number of metal, oxygen, and hydrogen atoms in the compound, respectively; $Q$ is the charge; $R$ is the gas constant; $T$ is temperature; $E$ is the redox potential; and ${\mu}{{\mathrm{H}}_{2}{\mathrm{O}}}$ is the chemical potential of water [48]. First-principles multielement Pourbaix diagrams from resources like the Materials Project enable the mapping of stability regions and calculation of $\Delta \Phi$ across a multidimensional space of pH, E, and metal ion concentrations [48].
Active Learning with Pairwise Reaction Databases
In solid-state synthesis, autonomous labs like the A-Lab build a database of observed pairwise reactions [6]. This database enables two critical functions for avoiding low-drive-force intermediates:
- Pathway Inference: The products of proposed recipes can be inferred from known pairwise reactions, precluding the need to test recipes that are known to lead to kinetic traps [6].
- Driving-Force-Guided Optimization: When multiple reaction pathways are possible, priority is given to those that form intermediates with a large remaining driving force to the target. For example, in synthesizing CaFe₂P₂O₉, the A-Lab actively learned to avoid a pathway forming FePO₄ and Ca₃(PO₄)₂ (which had a meager 8 meV/atom drive force to the target) in favor of a pathway forming CaFe₃P₃O₁₃ (with a 77 meV/atom drive force to the target), resulting in a ~70% yield increase [6].
The following diagram illustrates the core logical relationship of this active-learning process within a closed-loop autonomous laboratory.
Experimental Protocols and Reagent Solutions
Protocol: Validating MTC for Aqueous Synthesis
This protocol is adapted from the empirical validation of the MTC hypothesis for phases like LiIn(IO₃)₄ and LiFePO₄ [48].
Computational Screening:
- Using the target's composition, calculate its multielement Pourbaix diagram.
- Implement a gradient-based algorithm to identify the point $Y^$ (pH, E, [ion]) where the thermodynamic competition $\Delta \Phi(Y)$ is minimized [48].
- Select several additional synthesis conditions within the target's thermodynamic stability region but with varying, higher levels of thermodynamic competition.
Precursor Preparation:
- Prepare aqueous precursor solutions with metal ion concentrations precisely matching those calculated for the test conditions. For example, a ternary metal system requires control over three metal ion concentrations [48].
- Use standard reagents like metal salts (e.g., nitrates, acetates) and adjust pH using acids (e.g., HNO₃) or bases (e.g., NaOH, KOH).
Synthesis Execution:
- Carry out synthesis reactions (e.g., under hydrothermal conditions) across the selected range of conditions.
- Precisely control and monitor the solution pH and redox potential E during the reaction.
Phase Purity Analysis:
- Collect and analyze the final solid products using X-ray Diffraction (XRD).
- Use probabilistic machine learning models and automated Rietveld refinement to determine the phase and weight fractions of the target and all by-products [6].
- Expected Outcome: Phase-pure synthesis of the target material is expected predominantly, or exclusively, at or near the condition $Y^*$ where thermodynamic competition is minimized [48].
Protocol: Optimizing Solid-State Synthesis with Active Learning
This protocol is derived from the operation of the A-Lab for solid-state inorganic powders [6].
Initial Recipe Generation:
Robotic Synthesis and Characterization:
- Employ robotic arms to dispense, mix, and mill precursor powders before loading them into a box furnace for heating [6].
- After heating and cooling, transfer the sample to an automated station for grinding and XRD measurement.
Active Learning Cycle:
- If the target yield is ≤50%, initiate the ARROWS3 active learning algorithm [6].
- The algorithm consults the lab's growing database of observed pairwise reactions to avoid precursors that lead to known low-drive-force intermediates.
- It proposes new precursor sets designed to favor intermediates with a large computed driving force to the target material, using formation energies from the Materials Project [6].
- This cycle repeats until the target is obtained as the majority phase or all viable recipes are exhausted.
Table 2: Essential Research Reagent Solutions for Autonomous Materials Synthesis
| Category / Item | Specific Examples & Functions |
|---|---|
| Computational Databases | Materials Project/Google DeepMind DB: Source of ab initio computed formation energies, reaction energies, and phase stability data to calculate driving forces and build Pourbaix diagrams [6]. |
| Text-Mined Synthesis Data | Literature Recipe Database: 35,675 solution synthesis recipes text-mined from literature; used to train ML models for proposing initial synthesis attempts based on analogy [48] [6]. |
| Precursor Powders | Wide array of solid inorganic powders (oxides, phosphates, carbonates); must handle varying density, flow behavior, and hardness for robotic dispensing and milling [6]. |
| Characterization Tools | X-ray Diffraction (XRD): Primary tool for phase identification. ML-Powered Phase Analysis: Probabilistic models trained on experimental structures (ICSD) to analyze XRD patterns and provide quantitative phase fractions [6]. |
The strategic minimization of thermodynamic competition and the active avoidance of low-drive-force intermediates are not just theoretical concepts but are now being operationalized within autonomous laboratories. By making thermodynamic data a central component of the experimental workflow—guiding both initial condition selection and real-time, AI-driven optimization—researchers can dramatically accelerate the reliable synthesis of novel computational materials. This closed-loop integration of computation, historical data, and robotics, as demonstrated by platforms like the A-Lab, is a cornerstone of the next generation of high-throughput, data-driven materials science.
The evolution of traditional laboratories into closed-loop autonomous systems represents a paradigm shift in novel materials research and drug development. Self-driving laboratories (SDLs) accelerate scientific discovery by integrating robotics, artificial intelligence (AI), and automated experimentation into an iterative research cycle [50]. However, the path to full autonomy is fraught with significant technical hurdles, primarily centered on achieving seamless hardware interoperability and robust software integration. This guide details these core challenges and provides actionable methodologies for overcoming them, framed within the context of advanced materials research.
The Core Challenge: From Automation to Autonomy
A critical distinction exists between mere laboratory automation and a truly self-driving laboratory. Automated laboratories often function as open-loop systems, where researchers must analyze outcomes and plan subsequent steps, creating a bottleneck [50].
The transition to a closed-loop autonomous system is embodied by the Design-Make-Test-Analyze (DMTA) cycle, a foundational framework for SDLs [50]:
- Design: An AI or optimization algorithm formulates experimental hypotheses and synthesis strategies.
- Make: Robotic and fluidic synthesis systems execute the proposed experiments.
- Test: Automated analytical instruments characterize the resulting products or materials.
- Analyze: Data interpretation and AI-driven analysis extract meaningful insights, which automatically inform the next "Design" step.
This closed-loop workflow enables iterative autonomous optimization, allowing the system to navigate complex experimental spaces without human intervention. The "Make" and "Test" steps represent the physical layer, governed by hardware, while "Design" and "Analyze" are driven by software intelligence [50]. The primary technical hurdles lie in seamlessly connecting these domains.
Hardware Interoperability
The Integration Challenge
A central hardware challenge in SDLs is the inefficiency of force-integrating modular systems. Commercial laboratory equipment is often designed as standalone units, not as components of a unified ecosystem. This creates a landscape of heterogeneous communication protocols, physical interfaces, and control philosophies [50]. For instance, a liquid handler from one vendor, a robotic arm from another, and an HPLC from a third must all function in concert, which demands significant engineering effort to overcome proprietary barriers.
Strategies for Unified Hardware Control
Successful hardware interoperability is achieved through a multi-layered approach:
- Adoption of Standardized Communication Protocols: Implementing standards like SiLA2 (Standardization in Lab Automation) facilitates plug-and-play interoperability by defining a common language for device communication and data exchange [51].
- Modular Hardware Design: Designing or selecting hardware components with adaptable physical interfaces (e.g., standard fittings, modular tool changers) and software abstraction layers allows for greater system flexibility and reconfigurability [50].
- Hardware Abstraction in Software: As demonstrated by the IvoryOS orchestrator, creating a software layer that abstracts vendor-specific commands into a unified API is crucial. This allows high-level experimental protocols to be written in a hardware-agnostic manner [51].
Table 1: Common Hardware in Self-Driving Laboratories and Integration Challenges
| Hardware Category | Examples | Primary Function | Key Integration Challenges |
|---|---|---|---|
| Synthesis & Handling | Liquid handlers, robotic arms, automated reactors | Execute physical synthesis and sample preparation | Proprietary control software, physical coupling to other modules, precision and reproducibility. |
| Analytical Instruments | HPLC, Mass Spectrometers, Plate Readers | Characterize synthesized materials | Data output formats, real-time data access, instrument timing and triggering. |
| Ancillary Systems | Temperature controllers, automated balances, filtration modules | Provide controlled environmental conditions | Low-level communication protocols (e.g., RS-232, GPIO), feedback latency. |
Software Integration
The Orchestration Imperative
Software forms the "central nervous system" of an SDL, responsible for coordinating all activities. The key challenge is to integrate disparate software components—device drivers, data pipelines, and AI models—into a cohesive, autonomous whole [50]. Without a specialized operating system, SDLs require researchers to develop extensive custom scripts, creating a high barrier to entry and maintenance challenges [51].
Architectural Components for Seamless Integration
A robust SDL software architecture requires several key components, as exemplified by modern platforms like IvoryOS [51]:
- Specialized Operating System (OS): An SDL-specific OS manages multiple databases, allocates tasks to hardware along optimized paths, and facilitates fault detection and system-wide monitoring [50].
- Dynamic Web Interfaces: Tools like IvoryOS use lightweight web frameworks (e.g., Flask) to dynamically generate control interfaces directly from the underlying Python code. This provides a plug-and-play GUI that automatically updates with new hardware or functionalities, eliminating the need for manual interface development [51].
- Workflow Management: A visual, drag-and-drop workflow designer allows researchers to construct complex experimental protocols without coding. These interfaces translate visual workflows into executable scripts (e.g., in JSON format), enabling both human-in-the-loop and fully closed-loop experimentation [51].
- AI and Optimization Integration: The software must seamlessly integrate optimization algorithms (e.g., Bayesian Optimization) to autonomously suggest subsequent experiments. Furthermore, AI and Large Language Models (LLMs) can be embedded to assist in translating natural language task descriptions into machine-executable workflows [50] [51].
Experimental Protocols for Integration Assessment
Rigorous assessment of both hardware and software integration is essential for establishing a reliable SDL. The following protocols provide detailed methodologies for benchmarking system performance.
Protocol: Hardware Interoperability and Robustness
Objective: To quantitatively evaluate the seamless coordination and reliability of integrated hardware components within an SDL platform during a standardized experimental run.
Materials:
- Integrated SDL platform (e.g., robotic arm, liquid handler, HPLC)
- Standard reference materials and solvents
- Data logging system
Methodology:
- Script a Multi-Step Workflow: Develop an automated protocol that sequentially engages all critical hardware modules. For a chromatography SDL, this includes weighing, solvent delivery, mixing, injection, analysis, and cleanup [51] [52].
- Execute Repeated Runs: Perform a minimum of n=10 consecutive runs of the standardized workflow without human intervention.
- Data Collection: Log the following for each run and each hardware step:
- Success Rate: Percentage of steps completed without error.
- Timing Fidelity: Deviation from expected step duration.
- Data Transfer Success: Confirmation of successful data file generation and transfer from analytical instruments (e.g., HPLC) to the central data system [52].
Analysis:
- Calculate mean success rates and timing deviations for each hardware component.
- A robust, fully interoperable system should demonstrate a >95% success rate across all hardware steps with minimal timing drift.
Protocol: Software Integration and Data Flow
Objective: To validate the integrity and latency of data flow from instrument acquisition through AI analysis and back to experimental design.
Materials:
- Fully integrated SDL software stack (orchestrator, database, AI planner)
- Targeted LC-MS data set for processing with a known ground truth [52]
Methodology:
- Automated Data Processing: Configure the SDL's data pipeline (e.g., using a tool like TARDIS for LC-MS data) to automatically ingest raw data files, perform peak integration, and calculate quality metrics (AUC, signal-to-noise, peak shape) upon detection of a new run [52].
- AI-Driven Design Trigger: Set the AI planner (e.g., Bayesian Optimization) to automatically query the processed results from the database and generate a new experimental condition upon receipt of new data.
- Latency Measurement: Measure the time elapsed from: a) raw data file creation, to b) availability of processed data in the database, to c) generation of a new experiment by the AI.
Analysis:
- The protocol is successful if the entire data-to-design cycle is completed without manual intervention.
- Latency benchmarks will vary by experiment type, but the process should be efficient enough to prevent the hardware from idling, thus maintaining a closed loop.
The Scientist's Toolkit: Essential Reagents & Solutions
The following table details key computational and data solutions required for implementing the integrated workflows described in this guide.
Table 2: Key Research Reagent Solutions for SDL Integration
| Item | Function | Application Example |
|---|---|---|
| Orchestration Software (IvoryOS) | An open-source orchestrator that automatically generates web interfaces for Python-based SDLs, enabling drag-and-drop workflow design and execution management [51]. | Provides a no-code interface for researchers to design and run complex, multi-step experiments on integrated hardware. |
| Targeted Data Processing (TARDIS) | An open-source R package for the robust, automated analysis of targeted LC-MS metabolomics and lipidomics data. It includes quality metrics for peak evaluation [52]. | Ensures consistent, reproducible data analysis within the closed loop, automatically processing results from the "Test" phase for the "Analyze" phase. |
| Bayesian Optimization Library (Ax Platform) | A library for adaptive experimentation and optimization. It intelligently suggests the next best experiment to run based on previous results [51]. | Serves as the AI "brain" in the "Design" phase, optimizing for desired material properties or reaction outcomes. |
| Standardized Communication Protocol (SiLA2) | A standard for interoperability in laboratory automation. It allows devices from different vendors to communicate using a common language [51]. | Acts as a universal translator for hardware, simplifying the integration of instruments from different manufacturers. |
| Large Language Model (e.g., GPT-4) | A natural language processing model that can be integrated into SDL software to translate text-based experimental descriptions into executable workflow scripts [51]. | Lowers the barrier for human-in-the-loop control, allowing scientists to interact with the SDL using natural language. |
Achieving robust hardware interoperability and software integration is the most significant technical challenge in realizing the full potential of closed-loop autonomous laboratories. The path forward requires a concerted shift from isolated automation to architecturally unified systems. This involves embracing standardized protocols, modular hardware design, and sophisticated software orchestrators that can dynamically manage the entire DMTA cycle. By systematically addressing these hurdles with the strategies and methodologies outlined herein, researchers can deploy SDLs that dramatically accelerate the discovery and development of novel materials and pharmaceuticals.
Building a Foundational Database of Reaction Pathways for Smarter Searches
In the context of closed-loop autonomous laboratories for novel materials research, a foundational database of reaction pathways is not merely a reference tool; it is the core cognitive engine that enables artificial intelligence to plan, interpret, and learn from experiments. Autonomous systems like the "A-Lab" leverage such databases to close the gap between computational prediction and experimental realization of novel materials at an unprecedented pace [6]. Over 17 days of continuous operation, the A-Lab successfully synthesized 41 of 58 novel inorganic target compounds identified through computational screening—a 71% success rate that demonstrates the power of integrating computed pathway data with robotic experimentation [6]. This technical guide outlines the methodologies, components, and architectures required to construct these foundational databases, framing them within the operational context of self-driving laboratories that aim to accelerate materials discovery by 10-100 times compared to traditional approaches [53].
Core Components of a Reaction Pathway Database
Data Dimensions and Specifications
A comprehensive reaction pathway database for autonomous materials research must encompass multiple data dimensions to effectively guide robotic synthesis platforms. The database architecture should capture both thermodynamic and kinetic parameters alongside extensive metadata on experimental conditions.
Table 1: Essential Data Dimensions for Reaction Pathway Databases
| Data Category | Specific Parameters | Application in Autonomous Labs |
|---|---|---|
| Thermodynamic Properties | Formation energy, Decomposition energy, Reaction driving force | Predicts reaction feasibility and selects optimal precursors [6] |
| Kinetic Parameters | Activation barriers, Transition states, Intermediate stability | Identifies and overcomes kinetic limitations in synthesis [6] |
| Structural Information | Crystal structures, Bond lengths, Atomic coordinates | Enables phase identification and characterization via XRD [6] |
| Synthesis Conditions | Precursor selection, Temperature profiles, Heating rates | Informs robotic execution of synthesis recipes [6] |
| Characterization Data | XRD patterns, Spectral signatures, Phase fractions | Provides ground truth for automated data interpretation [6] |
The Halo8 dataset exemplifies this approach, comprising approximately 20 million quantum chemical calculations derived from about 19,000 unique reaction pathways, systematically incorporating halogen chemistry essential for pharmaceutical and materials applications [54]. Each entry in such a database should contain structures with associated energies, forces, dipole moments, and partial charges computed at consistent theoretical levels to ensure data uniformity [54].
Pathway Representation and Modeling
Effective pathway representation requires moving beyond simple reactant-product mappings to capture the complete reaction landscape. The A-Lab employs the ARROWS³ (Autonomous Reaction Route Optimization with Solid-State Synthesis) algorithm, which integrates ab initio computed reaction energies with observed synthesis outcomes to predict solid-state reaction pathways [6]. This approach operates on two key hypotheses: (1) solid-state reactions tend to occur between two phases at a time (pairwise), and (2) intermediate phases with small driving forces to form the target material should be avoided as they often require longer reaction times and higher temperatures [6].
The database should catalog these pairwise reactions—the A-Lab identified 88 unique pairwise reactions from its synthesis experiments—enabling the system to infer products of proposed recipes without physical testing, thereby reducing the experimental search space by up to 80% in some cases [6]. This knowledge allows prioritization of intermediates with large driving forces to form targets, significantly optimizing synthesis success rates.
Experimental Protocols for Pathway Data Generation
Computational Workflow for Pathway Sampling
Building a comprehensive reaction pathway database requires sophisticated computational protocols that efficiently explore chemical space while maintaining quantum chemical accuracy. The multi-level workflow implemented in the Dandelion pipeline demonstrates an effective approach, achieving a 110-fold speedup over pure density functional theory (DFT) methods [54].
Figure 1: Computational workflow for generating reaction pathway data, from initial reactant preparation to final database entry.
The protocol begins with reactant preparation, where molecules undergo systematic selection (e.g., from GDB-13 database), stereoisomer enumeration using RDKit, 3D coordinate generation via MMFF94 force field, and initial geometry optimization with GFN2-xTB [54]. The product search phase employs single-ended growing string method (SE-GSM) to explore possible bond rearrangements from the reactant, with driving coordinates generated automatically [54]. Landscape exploration then uses nudged elastic band (NEB) calculations with climbing image for improved transition state location [54].
Critical filtering criteria ensure chemical validity by excluding pathways with strictly uphill energy trajectories, negligible energy variations, or repetitive structures. New bands are sampled only when the cumulative sum of Fmax exceeds 0.1 eV/Å since the last inclusion, and pathways must exhibit proper transition state characteristics (single imaginary frequency) [54]. The final refinement stage performs single-point DFT calculations on selected structures along each pathway at the ωB97X-3c level, providing accurate energies, forces, dipole moments, and partial charges while balancing computational cost and accuracy [54].
Experimental Validation and Autonomous Refinement
Computationally derived pathways require experimental validation within autonomous laboratories to create closed-loop learning systems. The A-Lab demonstrates this approach through its integrated platform consisting of three robotic stations for sample preparation, heating, and characterization [6].
Table 2: Autonomous Laboratory Components for Pathway Validation
| System Component | Function | Implementation in A-Lab |
|---|---|---|
| Sample Preparation | Dispenses and mixes precursor powders | Robotic dispensing into alumina crucibles [6] |
| Heating System | Executes temperature profiles | Four box furnaces with robotic loading [6] |
| Characterization | Analyzes synthesis products | Automated X-ray diffraction (XRD) with grinding [6] |
| Data Interpretation | Identifies phases and weight fractions | Probabilistic ML models trained on ICSD data [6] |
| Active Learning | Proposes improved follow-up recipes | ARROWS³ algorithm using observed reaction data [6] |
The validation cycle begins with robotic arms transferring mixed precursors to box furnaces for heating according to computed temperature profiles [6]. After cooling, samples are automatically ground into fine powder and measured by XRD. Phase and weight fractions of synthesis products are extracted by probabilistic machine learning models trained on experimental structures from the Inorganic Crystal Structure Database, with patterns for novel materials simulated from computed structures and corrected to reduce DFT errors [6]. When initial recipes fail to produce >50% target yield, the active learning system uses observed outcomes to propose improved follow-up recipes, continuously expanding the pathway database with experimentally verified reaction data.
Pathway Visualization and Analysis Tools
Effective visualization of reaction networks is pivotal for identifying crucial compounds and transformations within complex chemical spaces. Tools like rNets provide specialized capabilities for visualizing reaction networks with user-friendly interfaces, modularity, and seamless integration with research software [55]. These visualization platforms enable researchers to navigate complex connectivity within pathway databases, identifying critical branching points and optimization opportunities.
In biological contexts, systems like PathText integrate pathway visualizers with text mining systems and annotation tools, creating environments where researchers can freely move between pathway representations and relevant scientific literature [56]. Similar approaches can be adapted for materials pathway databases, linking computational predictions with experimental reports and synthesis conditions. Reactome's analysis tools demonstrate how pathway databases can support statistical analyses, including over-representation tests that determine whether certain pathways are enriched in submitted data, though these are primarily focused on biological applications [57] [58].
The Scientist's Toolkit: Essential Research Reagents and Materials
Implementing an autonomous discovery pipeline requires specific computational and experimental resources. The following table details essential components for building and utilizing reaction pathway databases in materials research.
Table 3: Research Reagent Solutions for Pathway Database Development
| Tool/Category | Specific Examples | Function/Role |
|---|---|---|
| Quantum Chemistry Software | ORCA 6.0.1 [54] | Performs DFT calculations for accurate energies and forces |
| Computational Methods | ωB97X-3c, GFN2-xTB [54] | Provides balanced accuracy and efficiency for large-scale sampling |
| Molecular Databases | GDB-13, Transition1x [54] | Sources diverse molecular structures for reaction exploration |
| Structure Generation | RDKit, OpenBabel [54] | Enumerates stereoisomers and generates 3D coordinates |
| Pathway Sampling Methods | SE-GSM, NEB with climbing image [54] | Discovers and characterizes reaction pathways |
| Synthesis Precursors | Oxide and phosphate powders [6] | Starting materials for solid-state synthesis of inorganic compounds |
| Laboratory Hardware | Robotic arms, Box furnaces, XRD [6] | Automated execution and characterization of synthesis experiments |
| Data Analysis Frameworks | Probabilistic ML models, ARROWS³ [6] | Interprets experimental data and proposes improved syntheses |
Foundational databases of reaction pathways represent the cornerstone of autonomous materials discovery, enabling closed-loop systems to efficiently navigate complex chemical spaces. By integrating computational pathway sampling with experimental validation and active learning, these databases continuously refine their predictive capabilities, accelerating the transition from computational screening to synthesized materials. The success of platforms like the A-Lab—demonstrating a 71% synthesis success rate for novel compounds—validates this approach and highlights the transformative potential of comprehensive pathway data in materials research [6]. As these databases expand to encompass more diverse chemistry and more sophisticated synthesis protocols, they will increasingly serve as the foundational knowledge base for fully autonomous discovery across energy storage, catalysis, and pharmaceutical development.
Validating the Future: Benchmarking SDL Performance and Deployment Models
The development of novel materials has traditionally been a slow, iterative process, often spanning decades from initial discovery to deployment. The emergence of Self-Driving Labs (SDLs) represents a paradigm shift, promising to accelerate this timeline dramatically. This whitepaper provides a quantitative framework for benchmarking the performance of SDLs against traditional research methodologies within the context of closed-loop autonomous laboratories for novel materials research. We present empirical data from operational SDLs, detail the experimental protocols that enable their autonomous function, and visualize the core workflows. The evidence indicates that SDLs can reduce materials discovery and optimization cycles from years to days, while maintaining a high success rate, thereby offering researchers and drug development professionals a compelling new tool for rapid innovation.
The conventional materials discovery pipeline is characterized by manual, sequential experimentation often limited by human speed, resource constraints, and cognitive bandwidth. This frequently results in a multi-decade timeline for advanced materials to move from the laboratory to full deployment [59]. Autonomous experimentation systems, or Self-Driving Labs (SDLs), challenge this paradigm by combining artificial intelligence (AI), robotics, and high-throughput computation to automate the entire scientific method. SDLs are defined as systems that can "autonomously perform multiple cycles of the scientific method," interpreting results from one cycle to inform the design of the next [60]. For materials scientists and drug development professionals, this closed-loop operation offers the potential to explore high-dimensional experimental spaces orders of magnitude faster than traditional approaches, unlocking the study of more complex phenomena and accelerating the path to application.
Quantitative Benchmarking: SDLs vs. Traditional Timelines
To objectively evaluate the impact of SDLs, we must move beyond theoretical promises to empirical data. A landmark study from an autonomous laboratory, the A-Lab, provides a direct quantitative comparison.
Performance Metrics of an Operational SDL
The A-Lab, focused on the solid-state synthesis of inorganic powders, demonstrated the following performance over a continuous 17-day operational run [6]:
Table 1: Key Performance Indicators of the A-Lab SDL
| Metric | Performance | Contextual Comparison to Traditional Methods |
|---|---|---|
| Operation Duration | 17 days of continuous operation | Human-led labs are typically limited by working hours and manual processes. |
| Novel Compounds Targeted | 58 | A target set of this size could occupy a human research team for multiple years. |
| Successfully Synthesized | 41 compounds | A 71% success rate for first-time synthesis of novel materials. |
| Throughput | 41 novel compounds in 17 days | Represents an order-of-magnitude increase in the rate of materials discovery. |
| Optimization Capability | Active learning improved yield for 9 targets, 6 of which had zero initial yield. | Demonstrates the ability to learn from failure and iteratively improve without human intervention. |
Analysis of Failed Syntheses and Implicit Benchmarks
The A-Lab's 17 failed syntheses provide an implicit benchmark for traditional methods' challenges. The failures were categorized into: sluggish reaction kinetics (11 targets), precursor volatility, amorphization, and computational inaccuracy [6]. This analysis is crucial; it shows that while SDLs dramatically accelerate the process, they still contend with the same fundamental chemical and physical barriers that slow human researchers. However, the SDL's ability to rapidly identify these failure modes—a process that might take a graduate student months of trial and error—is in itself a significant acceleration of the diagnostic phase of research.
Experimental Protocols in Autonomous Materials Synthesis
The performance metrics outlined in Section 2 are enabled by a tightly integrated set of experimental protocols. The following workflow, implemented by the A-Lab, is representative of a high-autonomy SDL for solid-state materials synthesis [6].
Core Autonomous Workflow
The closed-loop operation of an SDL can be abstracted into a cyclic process of planning, execution, and analysis. The diagram below illustrates this core workflow and the logical relationships between its components.
Detailed Methodologies
A. Synthesis Planning: For a novel target compound, the SDL generates initial synthesis recipes using AI models trained on historical literature data. Natural-language processing models assess "target similarity" to identify effective precursors based on known related materials. A second model proposes an initial synthesis temperature based on mined historical data [6]. This mimics a human researcher's literature review but is executed in seconds.
B. Robotic Execution: The planned recipe is executed by an integrated robotic system. This typically involves:
- Dispensing & Mixing: A robotic station precisely dispenses and mixes precursor powders, transferring them into crucibles.
- Heating: A robotic arm loads the crucible into a box furnace for heating under a specified profile.
- Transfer & Preparation: After cooling, the sample is transferred to a station where it is ground into a fine powder to prepare for analysis [6].
C. AI-Powered Analysis: The synthesized powder is characterized by X-ray Diffraction (XRD). The resulting pattern is analyzed by machine learning models to identify phases and extract weight fractions of the products. For novel materials with no experimental data, diffraction patterns are simulated from computed structures and corrected for density functional theory (DFT) errors [6].
D. Success Evaluation & Active Learning: If the target yield is >50%, the process is concluded successfully. If not, an active learning loop, such as the Autonomous Reaction Route Optimization with Solid-State Synthesis (ARROWS3) algorithm, is initiated. This algorithm integrates ab initio computed reaction energies with observed synthesis outcomes to propose a new, optimized synthesis pathway, and the loop returns to step A [6]. The diagram below details this critical decision-making logic.
The Scientist's Toolkit: Key Research Reagent Solutions
The experimental workflow of an SDL relies on a suite of integrated hardware and software components. The following table details the essential "research reagents" — the core solutions and materials — that constitute a modern SDL for materials research.
Table 2: Essential Components of a Solid-State Synthesis SDL
| Item / Solution | Function in the SDL Workflow |
|---|---|
| Precursor Powders | High-purity starting materials that are robotically dispensed and mixed to form the initial reaction mixture. |
| Robotic Powder Dispensing & Milling Station | Ensures precise, reproducible handling and mixing of solid precursors, which have varied physical properties, to ensure good reactivity. |
| High-Temperature Box Furnaces | Provides the controlled thermal environment necessary for solid-state reactions, often with multiple furnaces for parallel processing. |
| X-Ray Diffraction (XRD) | The primary characterization tool used for phase identification and quantification of the synthesis products. |
| AI for Phase Analysis | Machine learning models that analyze XRD patterns to identify phases and calculate product yield, even for previously unreported compounds. |
| Ab Initio Computational Database (e.g., Materials Project) | Provides the foundational thermodynamic data (e.g., formation energies, phase stability) used to select targets and plan syntheses. |
| Active Learning Algorithm (e.g., ARROWS3) | The "brain" that closes the loop; it uses thermodynamic data and experimental outcomes to propose improved synthesis routes after failed attempts. |
Discussion and Future Outlook
The quantitative data presented in this whitepaper leaves little doubt that SDLs can drastically compress the timeline for materials discovery and optimization. The demonstrated ability to synthesize 41 novel compounds in 17 days provides a concrete benchmark against which traditional research can be measured. This acceleration is not merely a result of automation, but of the deep integration of AI-driven planning and analysis that enables the system to learn from every experiment.
The autonomy of these systems is classified on a spectrum. Most current SDLs, like the A-Lab, operate at Level 3 (Conditional Autonomy) or Level 4 (High Autonomy), capable of multiple closed-loop cycles of experimentation with minimal human intervention for anomalies [60]. The ultimate goal of Level 5 (Full Autonomy), an AI researcher that sets its own hypotheses, remains on the horizon.
For researchers and drug development professionals, the implication is profound. SDLs free human experts from routine experimentation, allowing them to focus on high-level problem definition, creative strategy, and interpreting broad scientific implications. Furthermore, the emergence of "cloud labs" offers remote access to automated experimentation capabilities, promising to democratize access to this powerful research methodology [60]. As these technologies mature, the benchmark for rapid innovation in materials science will be redefined by the pace of autonomous discovery.
The evolution of autonomous laboratories for accelerated materials research represents a fundamental shift in scientific experimentation. This transition is underpinned by a critical choice between two competing architectural paradigms: centralized models, which offer control and simplicity, and distributed models, which provide resilience and scalability. In the context of closed-loop autonomous systems for novel materials discovery, this distinction moves beyond abstract network theory to become a practical determinant of experimental throughput, reliability, and ultimate success.
The emergence of fully autonomous research platforms, such as the A-Lab for synthesizing novel inorganic powders, demonstrates the material impact of this architectural decision. These systems integrate computational screening, robotic execution, and artificial intelligence to plan and interpret experiments, effectively closing the discovery loop without human intervention. The architectural framework governing these components—whether centralized or distributed—directly influences their capacity to manage data, coordinate robotic assets, and scale operations. This technical guide examines these models within the specific context of accelerated materials research, providing researchers and scientists with the foundational knowledge to design infrastructure that meets the demanding requirements of modern autonomous discovery.
Defining Architectural Models
Centralized Models
Centralized models consolidate control, data processing, and decision-making authority within a single primary unit or location. In this architecture, often described as a hub-and-spoke model, all peripheral nodes (such as robotic instruments or user terminals) rely entirely on the central server for direction and resources.
Core Characteristics: A centralized system features a single point of control where all data processing and management tasks are handled [61]. This creates a clear, hierarchical structure that simplifies management and administration. All operations are routed through the central node, leading to efficient resource utilization and easier implementation of security measures and updates [61] [62]. Communication flows uniformly from peripheral nodes to the central authority and back.
Use Cases in Research: In experimental settings, centralized models often appear in traditional automated laboratories where a central server manages a fleet of robotic instruments [63]. This server might host the computational models that predict new stable materials, store the historical synthesis data, and queue experimental tasks for individual robotic stations. Enterprise systems like centralized ERP (Enterprise Resource Planning) or CRM (Customer Relationship Management) systems, which manage core business processes from a single system, exemplify this architecture in supporting research operations [61].
Distributed Models
Distributed models disperse control, processing, and data storage across multiple independent nodes. These nodes, which may be geographically separated, collaborate as a single coherent system while maintaining a degree of operational autonomy.
Core Characteristics: Distributed systems are defined by decentralized control and geographical distribution of nodes [64] [61]. They communicate via networks and exhibit concurrency, with multiple nodes operating simultaneously. This architecture provides inherent fault tolerance—the failure of one node does not cripple the system—and high scalability through the addition of more nodes [61] [62]. Resources such as processing power and storage are shared across the network, enabling more efficient utilization.
Use Cases in Research: Distributed architectures underpin modern large-scale research infrastructures. Cloud computing platforms (e.g., AWS, Google Cloud) provide on-demand, scalable computational resources for massive data analysis and simulation in materials research [61]. Content Delivery Networks (CDNs) distribute experimental data and software tools globally to reduce latency [62]. In autonomous laboratories, a distributed model might involve multiple specialized labs, each with local compute and decision-making capacity, collaborating on a shared materials discovery campaign without relying on a single central coordinator.
Decentralized Models as an Intermediate Paradigm
It is valuable to distinguish a third, hybrid architecture: the decentralized model. A decentralized system distributes control to multiple intermediate nodes, but unlike a fully distributed system, these nodes often have specialized roles or regional authority.
Core Characteristics: Decentralized systems feature distributed control where multiple nodes operate independently, but not necessarily equally [65] [61]. This structure enhances fault tolerance compared to centralized systems, as the failure of one node does not impact the entire system. Scaling is achieved by adding more nodes without overwhelming a central point [61].
Relationship to Other Models: Decentralization represents a middle ground. It avoids the single point of failure of centralized systems while being less complex to manage than fully distributed systems. Use cases include blockchain technologies for secure, immutable data logging in research, and Peer-to-Peer (P2P) networks for sharing large experimental datasets directly between research institutions [61].
Comparative Analysis: Centralized vs. Distributed Architectures
The choice between centralized and distributed models involves trade-offs across several critical dimensions. The following table summarizes these key differences, with particular emphasis on their implications for autonomous research environments.
Table 1: Core Architectural Comparison
| Aspect | Centralized Model | Distributed Model |
|---|---|---|
| Control & Management | Single point of control and management [61] [62]. Easier to govern and enforce policies [63]. | Decentralized control and authority; shared across nodes [61] [62]. More complex to manage [63]. |
| Fault Tolerance | High risk; a central server failure crashes the entire system [64] [61]. | High resilience; redundancy ensures operation despite node failures [64] [61]. |
| Scalability | Limited scalability; the central server can become a bottleneck [64] [65]. | Highly scalable; new nodes can be added easily to distribute load [64] [61]. |
| Data Management | All data managed and stored centrally [62]. | Data and resources are distributed across multiple nodes [62]. |
| Security | Strong perimeter defenses possible; simpler compliance [63]. Single point is a attractive target. | No single point of attack; requires compromising many nodes [64]. More complex to secure [63]. |
| Performance | Can be high initially but may degrade with increased load [61]. Lower latency for local operations. | High performance due to parallel processing and resource sharing [61]. Potentially higher latency from network communication. |
For autonomous laboratories, the implications of this architectural choice are profound. A centralized model offers simplified management and tighter oversight, which is advantageous in the early stages of developing a closed-loop system or for research with standardized, well-defined protocols [63]. Its primary weakness is the single point of failure; if the central server controlling the robotic synthesis and characterization pipeline fails, the entire discovery process halts [65].
Conversely, a distributed model excels in scalability and resilience. As the volume of computational screening data from sources like the Materials Project grows exponentially, a distributed system can scale horizontally to handle the load [64]. Its inherent fault tolerance ensures that the failure of a single robotic synthesizer or compute node does not stop a multi-target research campaign, as tasks can be rerouted to other available nodes [61]. This makes it ideally suited for large-scale, high-throughput experimentation.
Table 2: Strategic Implications for Autonomous Research
| Consideration | Centralized Model | Distributed Model |
|---|---|---|
| Experimental Throughput | Limited by central server capacity; risk of bottlenecks during peak load [64]. | Sustained high throughput; load is shared across multiple compute and robotics nodes [64]. |
| Operational Continuity | Critical vulnerability; central server maintenance or failure causes complete downtime [65]. | High availability; maintenance and failures are isolated to individual nodes without stopping the entire system [61]. |
| Data Accessibility | Dependent on central storage; if compromised, data is unavailable [64]. | Data is accessible from multiple points; failure of one storage node does not cause data loss [64]. |
| Integration of New Capabilities | Can be complex, requiring integration with and potential overhaul of the central core. | More agile; new instruments or compute resources can be added as independent nodes. |
Case Study: The A-Lab - A Hybrid Architectural Implementation
The A-Lab (Autonomous Laboratory) at UC Berkeley serves as a seminal real-world example of architectural choices in action. Its mission to close the gap between computational screening and experimental synthesis of novel materials requires a sophisticated integration of both centralized and distributed principles [6] [53].
Workflow and System Architecture
The A-Lab's workflow for the autonomous synthesis of novel materials demonstrates a tightly integrated, semi-centralized control system managing distributed physical components.
Diagram 1: A-Lab Closed-Loop Workflow
Experimental Protocol and Implementation
The operational success of the A-Lab is rooted in its detailed experimental protocols, which bridge computational planning and physical robotic execution.
Target Selection and Feasibility Assessment:
- Input: Targets are identified from large-scale ab initio phase-stability data from the Materials Project and Google DeepMind [6].
- Criterion: Selected compounds are predicted to be stable (on or near the convex hull of stable phases) and inert to reactions with O₂, CO₂, and H₂O to ensure compatibility with the lab's open-air handling [6].
- Output: A finalized list of novel, synthesizable target materials.
Literature-Inspired Recipe Generation:
- Methodology: Initial synthesis recipes are generated by a machine learning model that assesses "target similarity" through natural-language processing of a large text-mined database of historical syntheses [6]. This mimics a human researcher's approach of basing attempts on analogous known materials.
- Temperature Setting: A second ML model, trained on heating data from the literature, proposes an initial synthesis temperature [6].
Robotic Execution of Synthesis:
- Sample Preparation: A robotic station dispenses and mixes precursor powders before transferring them into alumina crucibles [6].
- Heating: A robotic arm loads crucibles into one of four available box furnaces for heating according to the planned recipe [6].
- Cooling: Samples are allowed to cool after the heating cycle is complete.
Automated Characterization and Analysis:
- Transfer & Preparation: A robotic arm transfers the cooled sample to a station where it is ground into a fine powder [6].
- XRD Measurement: The prepared powder is measured by X-ray diffraction (XRD) [6].
- Phase Identification: The phase and weight fractions of the synthesis products are extracted from XRD patterns by probabilistic ML models. As the targets are novel, their diffraction patterns are simulated from computed structures and corrected for DFT errors [6].
- Validation: Identified phases are confirmed with automated Rietveld refinement [6].
Active Learning and Optimization (ARROWS3):
- Trigger: This loop activates if the initial literature-inspired recipes fail to produce a target yield of >50% [6].
- Mechanism: The ARROWS3 algorithm integrates ab initio computed reaction energies with observed synthesis outcomes to predict improved solid-state reaction pathways. It operates on two key hypotheses: 1) reactions tend to occur pairwise, and 2) intermediates with a small driving force to form the target should be avoided [6].
- Outcome: The system proposes new precursor sets or thermal profiles and iterates through experiments until the target is obtained or all options are exhausted.
Key Research Reagents and Solutions
The experimental process relies on a core set of physical and computational components.
Table 3: Essential Research Reagents and Solutions for Autonomous Synthesis
| Item / Solution | Function / Description | Role in Autonomous Workflow |
|---|---|---|
| Precursor Powders | High-purity inorganic powders serving as starting materials for solid-state reactions. | The foundational physical input; dispensed and mixed by robotics based on the computed recipe [6]. |
| Alumina Crucibles | Chemically inert containers capable of withstanding high-temperature solid-state synthesis. | Act as standardized, robotic-friendly vessels for holding powder samples during firing in box furnaces [6]. |
| Ab Initio Database (e.g., Materials Project) | A computational database of calculated material properties and phase stabilities. | Provides the initial target list and thermodynamic data (e.g., formation energies) crucial for the active learning algorithm [6]. |
| Text-Mined Synthesis Database | A large collection of historical synthesis procedures extracted from scientific literature. | Trains the ML models that propose the initial, literature-inspired synthesis recipes and temperatures [6]. |
| Probabilistic ML Model for XRD | A machine learning model trained on experimental structures from the ICSD. | Automates the critical interpretation step by identifying phases and quantifying their weight fractions from XRD patterns [6]. |
Performance Outcomes and Architectural Insights
Over 17 days of continuous operation, the A-Lab successfully synthesized 41 out of 58 novel target compounds, achieving a 71% success rate [6]. This outcome provides critical insights:
- Centralized Intelligence, Distributed Execution: The A-Lab's architecture is a hybrid. The planning, data interpretation, and decision-making are functionally centralized in specific software agents. In contrast, the physical execution is distributed across multiple, specialized robotic stations (preparation, heating, characterization) that operate in a coordinated sequence [6].
- The Role of Distributed Knowledge: The system's success was heavily dependent on distributed knowledge sources. The use of a text-mined database of historical knowledge, combined with the large computational database of the Materials Project, provided a robust foundation for its initial decisions, much like a distributed network of information [6].
- Handling Failure Modes: The 17 unsuccessful syntheses highlighted barriers like slow reaction kinetics and precursor volatility [6]. A more distributed control architecture, where individual robotic nodes have greater autonomy to adjust parameters locally in response to real-time data, could potentially mitigate some of these issues by allowing for more adaptive, parallel experimentation.
Implementation Guide for Autonomous Research Systems
Selecting and implementing the appropriate architectural model requires a strategic assessment of research goals and constraints.
Model Selection Framework
- Evaluate Research Scope and Scale: Smaller, single-focus autonomous labs with a limited set of instruments may benefit from the simplicity and control of a centralized model. Organizations planning large-scale, multi-instrument campaigns across different domains (e.g., synthesis and characterization in separate facilities) will find the scalability and fault tolerance of a distributed model necessary [63].
- Assess Throughput and Availability Requirements: If experimental campaigns are time-sensitive and cannot tolerate downtime, the redundancy of a distributed system is the superior choice. For projects where scheduled maintenance is acceptable and throughput is predictable, a centralized system may suffice [64] [63].
- Consider Data Governance and Compliance: Centralized systems offer easier governance and streamlined audits as all data resides in one location [63]. Distributed systems require more sophisticated tools and policies to manage data sovereignty and ensure consistent compliance across all nodes [63].
- Analyze Integration and Interoperability Needs: Distributed models are inherently more flexible in integrating new, heterogeneous instruments and software tools from different vendors, as they can be added as independent nodes. Centralized models may require more custom integration work to ensure compatibility with the central core.
The Future: Hybrid and Edge-Computing Architectures
The dichotomy between centralized and distributed is increasingly blurred by the adoption of hybrid models. A common and powerful pattern in modern autonomous research is the use of edge computing [63].
In this model, centralized core infrastructure (e.g., for storing final results and running large-scale simulations) is combined with distributed edge nodes at the experimental site. Each edge node—such as a robotic synthesizer or a smart electron microscope—has its own local compute capacity to handle data-intensive tasks in real-time (e.g., initial image analysis, immediate feedback control for an experiment). This architecture reduces latency, minimizes bandwidth needs to the central cloud, and allows the system to function even if the central connection is temporarily lost, while still benefiting from centralized oversight and data aggregation [63]. This approach effectively creates a modular network of intelligent "foundries" capable of both autonomous operation and coordinated action.
The pursuit of accelerated materials discovery through autonomous laboratories is as much an engineering challenge as it is a scientific one. The choice between centralized and distributed architectural models is fundamental, influencing a system's capacity for scale, its resilience to failure, and its ultimate pace of discovery. While centralized models offer initial simplicity, the future of autonomous research lies in distributed and hybrid architectures. These models provide the scalability, fault tolerance, and modularity required to manage the vast data streams from computational screening and the complex, parallel operations of robotic experimentation. As platforms like the A-Lab continue to evolve, their success will increasingly depend on sophisticated cyber-infrastructure that mirrors the distributed, adaptive, and collaborative nature of the scientific endeavor itself.
Autonomous Experimentation (AE) and Self-Driving Labs (SDLs) represent a paradigm shift in materials science and drug development, revolutionizing the research process by combining artificial intelligence (AI) and robotics to design, execute, and analyze experiments in a rapid, iterative fashion [66]. These systems operate on a "human on the loop" rather than "human in the loop" principle, enabling them to generate and test scientific hypotheses faster and more effectively than human researchers alone [66]. The core value proposition of AE/SDLs lies in their ability to accelerate materials synthesis research and development by orders of magnitude, optimizing process quality and speed while producing deeper scientific understanding of materials phenomena [66]. This technical guide examines the real-world validation of these systems through outcomes from national laboratory initiatives and industrial applications, focusing specifically on their implementation within closed-loop frameworks for novel materials research.
Performance Benchmarks and Quantitative Outcomes
Synthesis and Optimization Efficiency
Table 1: Performance Metrics from Autonomous Experimentation Systems
| System/Initiative | Material/Application Domain | Key Performance Metrics | Experimental Efficiency Gains |
|---|---|---|---|
| ARES (Air Force Research Lab) | Carbon Nanotube (CNT) Synthesis | Rapid probing across 500°C temperature window and oxidizing-to-reducing gas partial pressure ratios spanning 8-10 orders of magnitude [66] | Dynamic parameter search optimizing process quality and speed at fraction of time/labor [66] |
| Autonomous PVD Exploration | Ge-Sb-Te Phase-Change Memory | Identification of Ge4Sb6Te7 with superior performance to widely used Ge2Sb2Te5 [66] | Optimal material identification after measuring only a fraction of full compositional range [66] |
| Sn-Bi Binary Thin-Film System | Temperature-Composition Phase Diagram | Accurate eutectic phase diagram determination [66] | Six-fold reduction in number of required experiments [66] |
| Robot-Controlled Multi-Chamber Vacuum System | Thin-Film Synthesis Optimization | Found optimized synthesis conditions within small number of deposition runs [66] | Fully autonomous closed-loop cycles integrating synthesis and characterization [66] |
AI-Driven Clinical Trial Optimization
Table 2: Performance of AI/ML Systems in Pharmaceutical Research
| Application Area | System/Method | Performance Metrics | Validation Outcome |
|---|---|---|---|
| Clinical Trial Feasibility | LLM-based Criteria Transformation | 58.2% token reduction while preserving clinical semantics [67] | Accelerated query generation from hours to minutes [67] |
| Clinical Concept Mapping | GPT-4 vs USAGI | GPT-4 achieved 48.5% concept mapping accuracy versus USAGI's 32.0% (P<.001) [67] | Domain-specific performance ranged from 72.7% (drug) to 38.3% (measurement) [67] |
| SQL Query Generation | llama3:8b vs GPT-4 | llama3:8b achieved highest effective SQL rate (75.8%) vs GPT-4 (45.3%) [67] | Lower hallucination rates (21.1% vs 33.7%) with smaller model [67] |
| Clinical Validation | LLM-Generated Queries | High concordance for type 1 diabetes (Jaccard=0.81), complete failure for pregnancy (Jaccard=0.00) [67] | Mixed performance revealing context-dependent reliability [67] |
Experimental Protocols and Methodologies
Autonomous Carbon Nanotube Synthesis via CVD
The ARES (Autonomous Research System) platform developed by the Air Force Research Laboratory represents one of the first fully autonomous systems for materials synthesis [66]. The experimental protocol encompasses several meticulously designed stages:
System Configuration: A cold-wall CVD system where growth gases are introduced into a chamber containing small silicon pillars (microreactors) seeded with CNT catalysts [66].
Stimulus Application: A high-power laser heats a single pillar to the target growth temperature, initiating carbon nanotube growth [66].
Real-Time Characterization: Growth is characterized in real time by analyzing scattered laser light with Raman spectroscopy as the nanotube forms [66].
AI-Guided Iteration: After experiment completion and result analysis, an AI planner selects growth conditions for the next experimental iteration, guided by user-defined goals [66].
Campaign objectives can be framed as either "Blackbox" optimization to maximize target properties or hypothesis testing. In one notable campaign, researchers tested the hypothesis that CNT catalyst would be most active under synthesis conditions where the metal catalyst was in equilibrium with its oxide [66]. The acquisition function (planner decision method) balanced exploration and exploitation to systematically vary the growth environment from oxidizing (higher water vapor or CO2 content, lower temperature) to reducing (greater hydrocarbon partial pressure, higher temperature) conditions [66].
Self-Driving Phase Diagram Mapping
A fully autonomous methodology for phase diagram mapping was demonstrated for the Sn-Bi binary thin-film system, integrating real-time, self-driving cyclical interaction between experiments and computational predictions [66]:
Combinatorial Library Fabrication: Creation of thin-film composition spreads using Physical Vapor Deposition (PVD) techniques [66].
Autonomous Thermal Processing: Implementation of self-guided thermal processing based on real-time experimental feedback [66].
Phase Boundary Determination: Experimental determination of compositional phase boundaries through in-situ characterization [66].
Real-Time Model Updating: Immediate updating of phase diagram predictions through Gibbs free energy minimization calculations [66].
This closed-loop approach enabled accurate determination of the eutectic phase diagram while sampling only a small fraction of the entire composition-temperature space, demonstrating a six-fold reduction in required experiments compared to conventional methodologies [66].
Clinical Trial Optimization Pipeline
For pharmaceutical applications, a sophisticated three-stage pipeline transforms free-text eligibility criteria into OMOP CDM-compliant SQL queries [67]:
Preprocessing Module: Implements segmentation (extracting individual criteria while preserving Boolean logic and hierarchical structures), filtration (removing non-queryable trial-specific criteria), and simplification (standardizing temporal expressions and reducing token count while maintaining clinical semantics) [67].
Information Extraction Module: Identifies seven structured elements from preprocessed text: Clinical Terms, Medical Terminology Systems (SNOMED CT, ICD-10, RxNorm, LOINC), Codes, Values, Attributes, Temporal, and Negation, then maps each clinical term to OMOP-standardized vocabularies [67].
SQL Generation Module: Creates CDM-compliant queries through iterative refinement and optimization, with data exchange between modules facilitated via structured JSON to ensure interoperability [67].
This pipeline was validated using OMOP CDM version 5.3 data from Asan Medical Center containing 4,951,000 unique patients with clinical records spanning from May 1989 to December 2020 [67].
Technical Architecture and Workflows
The operational logic of a fully autonomous materials research system follows a tightly integrated workflow that combines computational planning with physical experimentation. The diagram below illustrates this continuous cycle:
This workflow demonstrates the fundamental operational logic of autonomous laboratories, highlighting the continuous feedback loop that enables adaptive experimental design. The AI planner's acquisition function strategically balances exploration (searching unexplored regions for potentially superior outcomes) and exploitation (testing nearby conditions to optimize known peaks) to maximize information gain within experimental constraints [66].
Research Reagent Solutions and Essential Materials
Table 3: Key Research Reagents and Materials for Autonomous Experimentation
| Category | Specific Materials/Components | Function/Purpose | Application Context |
|---|---|---|---|
| Precursor Materials | Hydrocarbon gases (e.g., ethylene), reducing gases (e.g., hydrogen), oxidants (e.g., water vapor, CO2) [66] | Carbon source and environment control for CNT growth | CVD-based synthesis [66] |
| Catalyst Systems | Metal nanoparticles (Fe, Co, Ni) on silicon pillars/substrates [66] | Catalytic decomposition of precursors to template cylindrical nanotube structure | CNT synthesis in microreactors [66] |
| Thin-Film Deposition Targets | Ge-Sb-Te alloys, Sn-Bi binaries [66] | Composition-spread libraries for high-throughput materials exploration | PVD-based combinatorial synthesis [66] |
| Substrate Systems | Silicon wafers, combinatorial library chips with sample arrays [66] | Support material for thin-film deposition and characterization | CVD and PVD materials synthesis [66] |
| Characterization Tools | In-situ Raman spectroscopy, resistance measurement systems [66] | Real-time monitoring of material formation and properties | Autonomous characterization [66] |
| Computational Resources | Gaussian process models, Gibbs free energy minimization algorithms [66] | Prediction of material properties and phase behavior | AI-guided experimental planning [66] |
Implementation Challenges and Validation Frameworks
Technical and Operational Hurdles
Despite their promising capabilities, autonomous laboratories face several significant implementation challenges:
System Complexity: Robot-based systems incorporating sample-handling robots, while effective, can be costly and complex to operate and maintain [66].
Data Quality and Coverage: Limited concept coverage in validation datasets (e.g., SynPUF with ~27,000 of >2 million OMOP concepts) creates ideal conditions for identifying hallucination behaviors in AI systems [67].
Hallucination Management: LLMs exhibit concerning hallucination rates of 21%-50% when mapping clinical concepts to standardized vocabularies, with wrong domain assignments (34.2%) and placeholder insertions (28.7%) being the most common patterns [67].
Context-Dependent Performance: Clinical validation reveals wildly variable performance across different medical conditions, with high concordance for type 1 diabetes (Jaccard=0.81) but complete failure for pregnancy (Jaccard=0.00) [67].
Validation Methodologies
Robust validation frameworks are essential for establishing reliability of autonomous research systems:
Multi-Model Comparison: Comprehensive evaluation across 8 LLMs (both cloud-based and local) using diverse prompting strategies to identify optimal model-prompt combinations [67].
Real-World Clinical Validation: Testing against comprehensive medical datasets (e.g., Asan Medical Center's OMOP CDM database with 4.9M+ patients) to verify practical utility [67].
Hybrid Approach Development: Combining LLM capabilities with rule-based methods for handling complex clinical concepts to balance AI flexibility with deterministic reliability [67].
Human-in-the-Loop Verification: Maintaining expert researcher oversight for hypothesis generation and campaign objective definition while delegating iterative experimentation to autonomous systems [66].
Real-world validation of autonomous laboratory systems demonstrates their transformative potential while highlighting critical areas for continued development. The documented outcomes from national labs and industry partners confirm that AE/SDLs can accelerate materials discovery by orders of magnitude, optimize synthesis parameters with unprecedented efficiency, and generate scientific insights that extend beyond naive optimization to fundamental understanding of materials phenomena [66]. In pharmaceutical research, AI-driven systems show promising capabilities for accelerating clinical trial feasibility assessment, though hallucination rates of 21%-50% necessitate careful model selection and validation strategies [67].
Future advancements will likely focus on several key areas: improved hybridization of data-driven and physics-based models, development of more comprehensive validation frameworks across diverse material systems and medical domains, reduction of operational complexity and cost barriers, and establishment of standardized data formats and interoperability standards to facilitate cross-platform collaboration. As these systems mature, they hold the potential to fundamentally reshape the materials discovery and drug development landscape, turning autonomous experimentation into a powerful engine for scientific advancement across multiple disciplines.
The discovery and development of novel materials have traditionally been slow, costly processes, often spanning decades from initial concept to practical application. However, a transformative shift is underway, propelled by the emergence of closed-loop autonomous laboratories. These systems, often called Self-Driving Labs (SDLs), integrate robotics, artificial intelligence (AI), and massive data infrastructure to create a continuous, adaptive discovery pipeline. By fundamentally reengineering the scientific method itself, SDLs promise to accelerate the pace of discovery by 100 to 1000 times compared to conventional methods, thereby offering a compelling economic and strategic imperative for their widespread adoption in materials science and drug development [1]. This acceleration is not merely incremental; it represents a fundamental breakthrough in our capacity for innovation, potentially collapsing discovery timelines from 20 years to a matter of weeks [1] [68].
This whitepaper delineates the core architectures, methodologies, and economic rationales underpinning this acceleration. Framed within the broader context of national initiatives like the Materials Genome Initiative (MGI), which aims to double the speed and halve the cost of materials development, SDLs provide the critical experimental pillar to achieve these ambitious goals [1]. For researchers and drug development professionals, mastering this new paradigm is no longer a forward-looking aspiration but an immediate strategic necessity.
The Architectural Foundation of Self-Driving Labs
At its core, a Self-Driving Lab is an integrated system that automates the entire "design-make-test-analyze" (DMTA) cycle. This closed-loop operation is what enables the exponential acceleration of research. The functional architecture of a sophisticated SDL, such as one used for molecular discovery, can be broken down into five interconnected layers [1]:
- Data Layer: Serves as the foundational memory of the system, responsible for storing, managing, and sharing all experimental data, metadata, and full digital provenance.
- Autonomy Layer: The "brain" of the operation, where AI agents plan subsequent experiments, interpret results, and refine models using algorithms like Bayesian optimization and multi-objective reinforcement learning.
- Control Layer: The central orchestrator that executes the experimental sequences, ensuring synchronization, safety, and precision across all hardware.
- Sensing Layer: Comprises sensors and analytical instruments that capture real-time data on process parameters and material properties.
- Actuation Layer: Encompasses the robotic systems and programmable hardware that perform physical tasks such as dispensing, mixing, heating, and synthesis.
The following workflow diagram illustrates how these layers interact in a closed-loop system to autonomously discover new materials.
Figure 1: The closed-loop workflow of a Self-Driving Lab for materials discovery. This continuous, autonomous cycle of design, synthesis, testing, and learning can reduce the time per discovery iteration from weeks to days or hours [1].
Quantitative Acceleration: Data and Case Studies
The promised 100x to 1000x acceleration is not theoretical. Multiple documented case studies across various domains of materials science demonstrate the dramatic efficiency gains enabled by SDLs. The core driver of this acceleration is the massive compression of the DMTA cycle time and the ability to run experiments in a highly parallelized, high-throughput manner. For instance, in quantum dot synthesis, SDLs have been shown to map complex compositional and process landscapes an order of magnitude faster than manual methods [1]. A specific example is the Autonomous Multiproperty-driven Molecular Discovery (AMMD) platform, which autonomously discovered and synthesized 294 previously unknown dye-like molecules across just three DMTA cycles [1]. This scale and speed of exploration are simply unattainable through traditional manual research.
The economic driver behind this push for acceleration is a massive surge in computational demand. Google's AI infrastructure directives, for example, project a 1,000-fold increase in compute needs over four to five years, a pace that dramatically outpaces the historical trend of Moore's Law [69]. This creates a powerful feedback loop: advanced AI requires more computation, which in turn accelerates materials discovery, which can lead to new materials that further advance computational hardware. The table below summarizes key quantitative benchmarks from the field.
Table 1: Documented Performance Benchmarks of Autonomous Research Systems
| System / Platform | Domain | Key Achievement | Reported Acceleration Factor | Source |
|---|---|---|---|---|
| AMMD Platform | Molecular Discovery | Discovered & synthesized 294 new molecules in 3 DMTA cycles. | >100x (Time-to-solution) | [1] |
| SDL for Quantum Dots | Nanomaterials | Mapped compositional/process landscapes. | ~10x faster than manual methods. | [1] |
| OmniScient System | General Science | Models the full structure of human science (concept). | 100x-1000x acceleration projected. | [68] |
| Google AI Compute | Infrastructure | Projected growth to meet AI demand. | 1000x increase over 5 years. | [69] |
| National SDL Network | Materials Research | Projected reduction in discovery timelines. | 100x-1000x (vs. status quo) | [1] |
Experimental Protocols for Autonomous Discovery
To translate the architectural vision into tangible results, SDLs rely on rigorous, automated experimental protocols. The following provides a detailed methodology for a closed-loop experiment aimed at optimizing a functional material, such as a phosphor or a catalyst, for multiple properties.
Protocol: Multi-Objective Bayesian Optimization for Material Formulation
Objective: To autonomously discover a material formulation that simultaneously maximizes performance (e.g., luminescence intensity) and minimizes cost (e.g., concentration of a rare-earth element).
Initialization Phase:
- Define Search Space: Specify the chemical search space, including the identities of precursor compounds and their allowable concentration ranges (e.g., Dopant A: 0.1-10 mol%, Host B: 90-99.9 mol%).
- Establish Constraints: Input physical and safety constraints (e.g., total volume, maximum temperature, exclusion of hazardous compounds).
- Select Acquisition Function: Choose a multi-objective acquisition function, such as Expected Hypervolume Improvement (EHVI), to balance the exploration of unknown regions with the exploitation of known high-performance areas.
Active Learning Loop:
- Proposal: The autonomy layer's Bayesian optimization model proposes a batch of 4-8 candidate formulations that are most likely to improve the Pareto front (the set of non-dominated optimal solutions).
- Synthesis: The control layer directs robotic pipettes and liquid handlers in the actuation layer to precisely dispense and mix the precursor solutions according to the proposed formulations into a multi-well plate.
- Processing & Testing: The plate is transferred by a robotic arm to a furnace for sintering (e.g., 60 min at 1200°C) and then to a spectrophotometer or other characterization instrument (sensing layer) for measurement of target properties.
- Analysis & Model Update: The measured data (e.g., emission spectrum, intensity) is automatically processed, stored in the data layer with full provenance, and used to update the Bayesian optimization model. The loop repeats from step 1.
Termination Condition: The experiment concludes after a predefined budget (e.g., 200 experimental iterations) or when the improvement in the Pareto front falls below a set threshold for 20 consecutive iterations [1].
The Scientist's Toolkit: Key Research Reagent Solutions
The effective operation of an SDL depends on a suite of integrated hardware and software components. The following table details the essential "research reagent solutions" — the core materials and tools that form the backbone of any autonomous discovery platform.
Table 2: Essential Components of a Self-Driving Lab Toolkit
| Tool / Component | Function | Implementation Example |
|---|---|---|
| Bayesian Optimization Software | AI decision engine that plans the next best experiments by trading off exploration and exploitation. | Custom Python code using libraries like BoTorch or Scikit-Optimize. |
| Laboratory Robotics | Executes physical tasks: synthesis, dispensing, and sample handling. | High-throughput liquid handlers, robotic arms for plate movement, automated synthesis reactors. |
| In-Line / On-Line Spectrometers | Provides real-time, high-frequency data on material properties for immediate feedback. | Integrated UV-Vis, NMR, or fluorescence spectrometers connected to reactor outlets. |
| Laboratory Information Management System (LIMS) | Manages experimental data, metadata, and provenance; ensures data is FAIR (Findable, Accessible, Interoperable, Reusable). | Benchling, an custom database with structured ontologies for materials science. |
| Modular Microreactors | Enables rapid, small-volume synthesis with precise control over reaction parameters (T, P, flow rate). | Continuous-flow chip-based reactors for rapid screening of reaction conditions. |
Strategic Implications and Future Outlook
The strategic implications of 100x-1000x accelerated discovery are profound. For nations, leadership in AI, quantum computing, and fusion energy — all fields dependent on advanced materials — is at stake [70]. The emergence of a "technological trinity," where advancements in AI, quantum computing, and fusion energy reinforce each other, creates a powerful virtuous cycle. For instance, AI is already being used to optimize plasma containment in fusion reactors, while the prospect of fusion energy promises the vast, clean power required for future generations of energy-intensive AI and quantum computers [70].
For pharmaceutical and materials companies, the ability to rapidly explore vast chemical and formulation spaces will de-risk development pipelines and unlock unprecedented innovation. This paradigm shift also reshapes the research workforce, necessitating interdisciplinary scientists who are as fluent in data science as they are in traditional laboratory science. The organizations and researchers who embrace and invest in this autonomous infrastructure today will be the undisputed leaders of the scientific discovery tomorrow. The time to build, integrate, and master these Self-Driving Labs is now.
The emergence of closed-loop autonomous laboratories represents a paradigm shift in materials science and drug development. These self-driving labs integrate artificial intelligence (AI), robotics, and high-throughput experimentation to accelerate the discovery of novel materials and compounds [71] [1]. Platforms such as the A-Lab for inorganic powders and autonomous systems for chemical discovery demonstrate the transformative potential of these technologies, having successfully synthesized dozens of previously unknown compounds through continuous, AI-driven experimentation [72] [6]. However, this rapid technological advancement has created a significant innovation gap in intellectual property (IP) law, where traditional inventorship frameworks struggle to accommodate inventions generated with substantial AI assistance. This whitepaper provides researchers, scientists, and drug development professionals with a comprehensive technical guide to navigating the complex IP landscape for AI-generated inventions within the context of autonomous materials research.
The Current Legal Framework for AI Inventorship
Foundational Legal Principles
The United States Patent and Trademark Office (USPTO) has established clear guidelines that only natural persons can be named as inventors on patent applications, regardless of whether AI systems contributed to the inventive process [73] [74]. This position was reinforced in November 2025 when the USPTO rescinded its February 2024 guidance and issued updated inventorship guidance for AI-assisted inventions. The current legal standard centers on the concept of "conception" – defined as "the formation in the mind of the inventor, of a definite and permanent idea of the complete and operative invention, as it is hereafter to be applied in practice" [73]. AI systems are legally classified as tools or instruments used by human inventors, analogous to laboratory equipment, computer software, or research databases [73] [75].
Global Perspectives on AI Inventorship
Internationally, patent offices have largely adopted similar approaches to the USPTO, maintaining that inventorship requires human agency. The European Union, China, and other major jurisdictions generally refuse to recognize AI systems as inventors, though subtle differences exist in how they assess the technical character of AI inventions [76] [77]. This global alignment creates a relatively consistent framework for multinational research organizations but necessitates careful documentation of human contributions across all jurisdictions.
Table 1: International Comparison of AI Inventorship Standards
| Jurisdiction | Inventorship Standard | Key Legal Decisions/Guidance |
|---|---|---|
| United States | Only natural persons can be inventors; AI is a tool | Thaler v. Vidal (2022); USPTO Guidance (2025) |
| European Union | AI cannot be an inventor; human operator may claim ownership | EU Court of Justice rulings; EU AI Act |
| China | Does not recognize AI as inventor; requires human inventor | Chinese Patent Office guidelines |
| United Kingdom | Consultation ongoing regarding AI and IP law | December 2024 consultation on text and data mining |
Autonomous Laboratories: Architecture and Workflows
Technical Architecture of Self-Driving Labs
Closed-loop autonomous laboratories represent the cutting edge of AI-driven scientific discovery, implementing fully automated design-make-test-analyze (DMTA) cycles that can operate continuously with minimal human intervention [1] [72]. The A-Lab for solid-state synthesis of inorganic powders exemplifies this approach, having successfully realized 41 novel compounds from 58 targets during 17 days of continuous operation [6]. These systems integrate multiple technological layers into a cohesive discovery engine.
Diagram 1: Autonomous laboratory architecture showing the closed-loop workflow.
The technical architecture of autonomous laboratories typically comprises five integrated layers [1]:
- Actuation Layer: Robotic systems performing physical tasks (dispensing, heating, mixing)
- Sensing Layer: Sensors and analytical instruments capturing real-time data
- Control Layer: Software orchestrating experimental sequences and safety protocols
- Autonomy Layer: AI agents planning experiments and interpreting results
- Data Layer: Infrastructure for storing, managing, and sharing experimental data and provenance
Key Research Reagents and Robotic Systems
Table 2: Essential Research Reagents and Robotic Systems in Autonomous Laboratories
| Component Type | Specific Examples | Function in Autonomous Workflow |
|---|---|---|
| Precursor Materials | Metal salts, oxides, phosphates | Starting materials for solid-state synthesis of inorganic powders |
| Robotic Manipulators | Multi-axis robotic arms | Transfer samples and labware between workstations |
| Automated Synthesis | Box furnaces, continuous flow reactors | Perform controlled heating and reaction protocols |
| Characterization | Powder X-ray diffraction (PXRD) | Analyze synthesis products for phase identification |
| AI Algorithms | Bayesian optimization, large language models | Plan experiments, interpret results, optimize parameters |
Experimental Protocols in Autonomous Discovery
Synthesis Workflow for Novel Materials
The experimental workflow for autonomous materials discovery follows a rigorous, iterative process that mirrors human scientific reasoning while operating at dramatically accelerated timescales. In the A-Lab implementation, this process begins with target identification from computational databases such as the Materials Project and Google DeepMind's GNoME database, which has expanded the number of known stable materials nearly tenfold to 421,000 [72] [6].
Diagram 2: Autonomous synthesis workflow for novel materials discovery.
The specific experimental protocol for solid-state synthesis of novel inorganic materials involves [6]:
- Target Selection: Compounds predicted to be stable through large-scale ab initio phase-stability calculations from the Materials Project and Google DeepMind.
- Precursor Selection: Initial synthesis recipes generated by natural language processing models trained on historical synthesis data from scientific literature.
- Robotic Execution:
- Automated dispensing and mixing of precursor powders
- Transfer to alumina crucibles using robotic arms
- Heating in one of four available box furnaces
- Cooling and grinding into fine powder
- Characterization: X-ray diffraction (XRD) analysis with phase and weight fractions extracted by probabilistic machine learning models.
- Active Learning: If initial recipes fail to produce >50% target yield, the autonomous system implements Bayesian optimization to propose improved synthesis routes based on observed reaction pathways and thermodynamic driving forces.
Key Algorithmic Methodologies
The autonomy layer of self-driving laboratories relies on sophisticated AI algorithms that enable adaptive experimentation [1] [72]:
- Bayesian Optimization: Efficiently navigates complex, multidimensional parameter spaces to converge on optimal synthesis conditions with minimal experimental iterations.
- Large Language Models (LLMs): Parse scientific literature and translate researcher intent into structured experimental constraints.
- Random Forest Models: Predict synthesis outcomes based on iterative training from prior experimental data.
- Genetic Algorithms: Handle large numbers of variables for discovery of novel catalysts and synthesis optimization.
- Knowledge Graphs: Provide structured representation of chemical data and relationships for enhanced decision-making.
Intellectual Property Strategy for AI-Assisted Inventions
Documenting Human Invention in Autonomous Systems
For research organizations utilizing autonomous laboratories, establishing clear inventorship requires meticulous documentation of human contributions throughout the discovery pipeline. The USPTO guidance emphasizes that "the same legal standard for determining inventorship applies to all inventions, regardless of whether AI systems were used in the inventive process" [73]. Critical human contributions that may establish inventorship include [73] [77]:
- Defining the Research Problem: Formulating the specific scientific problem or objective that the autonomous system addresses.
- Designing the Experimental Framework: Establishing the overall research methodology, including selection of characterization techniques and success metrics.
- Training AI Models: Curating training datasets, selecting model architectures, and fine-tuning algorithmic parameters.
- Interpreting Results: Analyzing and validating experimental outcomes to guide subsequent research directions.
- Recognizing Patentable Concepts: Identifying which discoveries represent novel, non-obvious, and useful inventions worthy of patent protection.
Patent Strategy and Claim Drafting Considerations
When pursuing patent protection for AI-assisted inventions, specific strategies enhance the likelihood of successful prosecution and enforcement [77]:
- Technical Implementation Focus: Claims should demonstrate concrete technical improvements rather than abstract algorithms, emphasizing specific model designs, training processes, or interface improvements.
- Human Contribution Documentation: Maintain laboratory notebooks (electronic or physical) that clearly document human decisions throughout the autonomous discovery process.
- Claim Diversity: Include claims directed to various aspects of the invention, including composition of matter, synthesis methods, characterization techniques, and specific applications.
- Global Portfolio Management: Tailor applications to address jurisdictional differences in AI patentability, emphasizing technical character in Europe and technical solutions in China.
The integration of artificial intelligence into materials discovery through autonomous laboratories represents a transformative advancement in scientific capability. These systems have demonstrated remarkable efficiency, with platforms like the A-Lab achieving a 71% success rate in synthesizing novel compounds identified through computational screening [6]. As this technology continues to evolve toward distributed networks and increasingly sophisticated AI agents, the intellectual property framework must maintain its fundamental requirement of human inventorship while adapting to new paradigms of discovery. For researchers and organizations operating in this space, success will depend on implementing robust documentation practices that clearly articulate human contributions throughout the autonomous research pipeline. By maintaining this focus on human ingenuity while leveraging the unprecedented capabilities of AI-driven systems, the scientific community can bridge the innovation gap and fully realize the potential of autonomous discovery for advancing materials science and drug development.
Conclusion
Closed-loop autonomous laboratories represent a fundamental shift in the scientific method, poised to compress materials discovery timelines from decades to days. By synthesizing AI-driven design with robotic execution and continuous learning, SDLs have demonstrated a remarkable ability to navigate complex experimental spaces and overcome traditional synthesis barriers, as validated by platforms like the A-Lab. For biomedical and clinical research, this promises a future of rapidly discoverable novel therapeutics, biomaterials, and diagnostics. Realizing this future requires addressing key challenges, including the development of robust interoperability standards, updated intellectual property frameworks for AI-generated inventions, and strategic investment in a national Autonomous Materials Innovation Infrastructure. The integration of SDLs into the research ecosystem will not replace scientists but will empower them to focus on high-level innovation, ultimately accelerating the translation of groundbreaking ideas into tangible solutions for human health.
References
- 1. Accelerating the Materials Genome Initiative with Self ... [https://www.nae.edu/340998/Accelerating-the-Materials-Genome-Initiative-with-SelfDriving-Labs]
- 2. Material intelligence by the convergence of artificial ... [https://www.sciencedirect.com/science/article/pii/S2950160125000300]
- 3. How automation has impacted quantitative research [https://www.zappi.io/web/blog/how-automation-has-impacted-quantitative-research/]
- 4. Autonomous closed-loop exploration of composition ... [https://www.nature.com/articles/s41524-025-01828-7]
- 5. A Quantitative Autonomy Quantification Framework for ... [https://arxiv.org/html/2311.01939v2]
- 6. An autonomous laboratory for the accelerated synthesis of ... [https://www.nature.com/articles/s41586-023-06734-w]
- 7. Data Center Robotics Industry Business Report 2025 ... [https://www.businesswire.com/news/home/20251110228124/en/Data-Center-Robotics-Industry-Business-Report-2025-Smart-Infrastructure-and-IoT-Integration-Amplifies-the-Value-Proposition-of-Collaborative-Robotics-in-Data-Centers---Global-Forecast-to-2030---ResearchAndMarkets.com]
- 8. Performance metrics to unleash the power of self-driving ... [https://www.nature.com/articles/s41467-024-45569-5]
- 9. Human AI collaboration for unsupervised categorization of ... [https://www.nature.com/articles/s41746-024-01383-3]
- 10. AI‐Powered Clinical Decision Support Systems in Disease ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12516455/]
- 11. Accelerating compound synthesis in drug discovery [https://pmc.ncbi.nlm.nih.gov/articles/PMC12560346/]
- 12. AI-Digital-Physical Convergence: The Future of DMTA in ... [https://www.acdlabs.com/resource/ai-digital-physical-convergence-the-future-of-dmta-in-drug-discovery-development/]
- 13. Accelerating Drug Discovery Through Agentic AI: A Multi- ... [https://arxiv.org/html/2507.09023v1]
- 14. Breaking down barriers across the DMTA cycle [https://www.drugtargetreview.com/article/112462/breaking-down-barriers-across-the-dmta-cycle/]
- 15. On-the-fly Closed-loop Autonomous Materials Discovery ... [https://arxiv.org/abs/2006.06141]
- 16. Materials Genome Initiative: MGI Homepage [https://www.mgi.gov/mgi-homepage]
- 17. Accelerating Materials Innovation: Lessons Learned and ... [https://www.nae.edu/341009/Accelerating-Materials-Innovation-Lessons-Learned-and-Opportunities-Ahead]
- 18. Guest Editor's Note - The Materials Genome Initiative (MGI) [https://www.nae.edu/341012/Guest-Editors-Note-The-Materials-Genome-Initiative-MGI-Status-and-Future-Outlook]
- 19. revolutionizing spatiotemporal data sharing and collaboration [https://link.springer.com/article/10.1007/s43762-025-00165-1]
- 20. SDL Materials Design [https://www.nhr4ces.de/simulation-and-data-labs/sdl-materials-design/]
- 21. IoT Architecture: Six Levels, Core Components and Use ... [https://www.itransition.com/iot/architecture]
- 22. Implementing Data-Driven Approach for Modelling ... [https://www.mdpi.com/2076-3417/12/12/5881]
- 23. Shared Data Layer [https://www.nokia.com/core-networks/shared-data-layer/]
- 24. The Summer Training Workshop on Spatiotemporal ... [https://sdl.gis.harvard.edu/event/summer-training-workshop-2025]
- 25. AI system learns from many types of scientific information ... [https://news.mit.edu/2025/ai-system-learns-many-types-scientific-information-and-runs-experiments-discovering-new-materials-0925]
- 26. Synthesis Planning - MMLI [https://moleculemaker.org/research/alpha-synthesis/]
- 27. Scaling Materials Discovery with Self-Driving Labs [https://ifp.org/scaling-materials-discovery-with-self-driving-labs/]
- 28. Reimagining the Future of Materials Discovery [https://www.bu.edu/hic/2025/10/14/reimagining-the-future-of-materials-discovery-from-automation-to-collaboration/]
- 29. 10 Innovative Lab Tools Scientific Research in 2025 [https://go.zageno.com/blog/innovative-lab-tools-2025]
- 30. Active learning in materials science with emphasis on ... [https://www.nature.com/articles/s41524-019-0153-8]
- 31. ACTIVE LEARNING IN MACHINE LEARNING: A STEP ... [https://teaching.ieee.org/active-learning-in-machine-learning-a-step-towards-smarter-models/]
- 32. Active learning machine learning: What it is and how it works [https://www.datarobot.com/blog/active-learning-machine-learning/]
- 33. Active Learning in Machine Learning: Guide & Strategies ... [https://encord.com/blog/active-learning-machine-learning-guide/]
- 34. Autonomous Experimentation | Materials Science [https://www.nrel.gov/materials-science/autonomous-experimentation]
- 35. Researchers Hit 'Fast Forward' on Materials Discovery with ... [https://news.ncsu.edu/2025/07/fast-forward-for-self-driving-labs/]
- 36. A Route to Design Novel Functional Peptides by Applying a ... [https://pubmed.ncbi.nlm.nih.gov/41147133/]
- 37. AI in drug discovery: Key trends shaping therapeutics in 2025 [https://www.gubra.dk/blog/ai-in-drug-discovery-key-trends-shaping-therapeutics-in-2025/]
- 38. 48Hour Discovery Pioneers Late-Stage Peptide Reshaping ... [https://48hourdiscovery.com/2025/04/22/48hour-discovery-pioneers-late-stage-peptide-reshaping-to-advance-drug-discovery/]
- 39. On amorphization as a deformation mechanism under high ... [https://www.sciencedirect.com/science/article/pii/S1359028621000796]
- 40. Hyper-Range Amorphization Unlocks Superior Damage ... [https://www.nature.com/articles/s41467-025-65379-7]
- 41. Epic Failures — Lessons from Volatility Funds blow-ups [https://volquant.medium.com/epic-failures-lessons-from-volatility-funds-blow-ups-6f4226c8334f]
- 42. Volmageddon and the Failure of Short Volatility Products ... [https://rpc.cfainstitute.org/research/financial-analysts-journal/2021/volmageddon-failure-short-volatility-products]
- 43. On-the-fly closed-loop materials discovery via Bayesian ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7686338/]
- 44. Bayesian optimization with active learning of design ... [https://www.nature.com/articles/s41524-023-01006-7]
- 45. A review of active learning approaches to experimental ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5453429/]
- 46. A Data-driven Active Learning Framework for Accelerating ... [https://arxiv.org/html/2503.21095v1]
- 47. Bayesian Optimization within automation - Research [https://labautomation.io/t/bayesian-optimization-within-automation/2004]
- 48. Optimal thermodynamic conditions to minimize kinetic by- ... [https://www.nature.com/articles/s44160-023-00479-0]
- 49. Novel computational and experimental approaches for ... [https://www.sciencedirect.com/science/article/pii/S1369527421001673]
- 50. Self-driving laboratories with artificial intelligence [https://www.sciencedirect.com/science/article/abs/pii/S0098135425002698]
- 51. IvoryOS: an interoperable web interface for orchestrating ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12137583/]
- 52. Automated Integration and Quality Assessment of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12257450/]
- 53. Autonomous experimentation for accelerated materials ... [https://ceder.berkeley.edu/research-areas/autonomous-experimentation-for-accelerated-materials-discovery/]
- 54. A dataset of chemical reaction pathways incorporating ... [https://www.nature.com/articles/s41597-025-05944-3]
- 55. rNets: a standalone package to visualize reaction networks [https://www.sciencedirect.com/org/science/article/pii/S2635098X2400130X]
- 56. PathText: a text mining integrator for biological pathway ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC2881405/]
- 57. Analysis Tools - Reactome Pathway Database [https://reactome.org/userguide/analysis]
- 58. Home - Reactome Pathway Database [https://reactome.org/]
- 59. Autonomous experimentation systems for materials ... [https://www.sciencedirect.com/science/article/pii/S2590238521003064]
- 60. Autonomous 'self-driving' laboratories: a review of technology ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12368842/]
- 61. Centralized vs. Decentralized vs. Distributed Systems [https://www.geeksforgeeks.org/system-design/comparison-centralized-decentralized-and-distributed-systems/]
- 62. Centralized vs Distributed System [https://www.geeksforgeeks.org/computer-networks/centralized-vs-distributed-system/]
- 63. Centralized vs. Distributed IT Infrastructure [https://www.scalecomputing.com/resources/centralized-vs-distributed-it-infrastructure]
- 64. Distributed VS centralized networks - iCommunity [https://icommunity.io/en/centralized-vs-distributed-networks/]
- 65. Centralized vs. Decentralized vs. Distributed Networks (the ... [https://www.liveaction.com/resources/blog-post/centralized-vs-decentralized-vs-distributed-networks-the-history-future/]
- 66. Autonomous Experimentation and Self-Driving Labs for ... [https://www.nae.edu/340966/Autonomous-Experimentation-and-SelfDriving-Labs-for-Materials-Synthesis-Using-Deposition-Techniques]
- 67. Large Language Models for Automating Clinical Trial ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12530336/]
- 68. Science automation progress, this is big Full AI-Driven ... [https://www.facebook.com/0xSojalSec/posts/science-automation-progress-this-is-bigfull-ai-driven-research-systemmost-curren/1381589990162067/]
- 69. Google's AI Boom: 1000x Compute Surge Defies Moore's ... [https://www.webpronews.com/googles-ai-boom-1000x-compute-surge-defies-moores-law/]
- 70. February 2025: The Tech Trinity Emerges [https://www.superseed.com/journal/february-2025-ai-giants-unleash-new-models-as-fusion-and-quantum-make-historic-leaps/]
- 71. Advancing materials discovery through artificial intelligence [https://www.sciencedirect.com/science/article/pii/S2352940725003981]
- 72. Autonomous laboratories in China: an embodied intelligence ... [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d5dd00072f]
- 73. Revised Inventorship Guidance for AI-Assisted Inventions [https://www.federalregister.gov/documents/2025/11/28/2025-21457/revised-inventorship-guidance-for-ai-assisted-inventions]
- 74. USPTO Issues New AI Inventorship Guidance, Snubs ... [https://ipwatchdog.com/2025/11/26/uspto-issues-new-ai-inventorship-guidance-snubs-vidals-approach/]
- 75. USPTO Withdraws Guidance, Reaffirms AI Cannot Be ... [https://meritalk.com/articles/uspto-withdraws-guidance-reaffirms-ai-cannot-be-listed-as-inventor/]
- 76. How AI Impacts Intellectual Property Laws and Policies in ... [https://lumenci.com/blogs/ai-impacts-intellectual-property-laws/]
- 77. AI Patent Protection and Litigation: Key Takeaways for ... [https://www.morganlewis.com/pubs/2025/11/ai-patent-protection-and-litigation-key-takeaways-for-innovators-and-companies]